The Kalman filter is an algorithm that measures the state of a system from measured data. It uses a two-step process: the first step predicts the state of the system, and the second step uses noisy measurements to refine the estimate of system state.
Robot Motion Example
Let’s say we have a robot that has state , which is just a position and velocity:
State
State is just a list of numbers about the underlying configuration of your system; it could be anything. In our example it’s position and velocity, but it could be data about the amount of fluid in a tank, the temperature of a car engine, the position of a user’s finger on a touchpad, or any number of things you need to keep track of.
Information we have:
- Our robot also has a GPS sensor, which is accurate to about 10 meters, which is good, but not precise enough.
- We also know how the robot moves in general; if it moves in one direction it will, at the next time step it will likely be further along that same direction. However, this is not perfect, as there might be terrain or external factors that result in noise.
Thus, both our sensor and model tell us some information about the state, but only indirectly, and both have some uncertainty. We don’t know what the actual position and velocity are; there are a whole range of possible combinations of position and velocity that might be true, but some of them are more likely than others.
Formulation
The Kalman filter assumes that both position and velocity are random variables that are Gaussian distributed. Each variable has:
- Mean of , which is the center of the distribution.
- Variance of , which is the uncertainty.
Covariance
However, it’s important to note that position and velocity could be correlated; the likelihood of observing a particular position depends on what velocity you have:
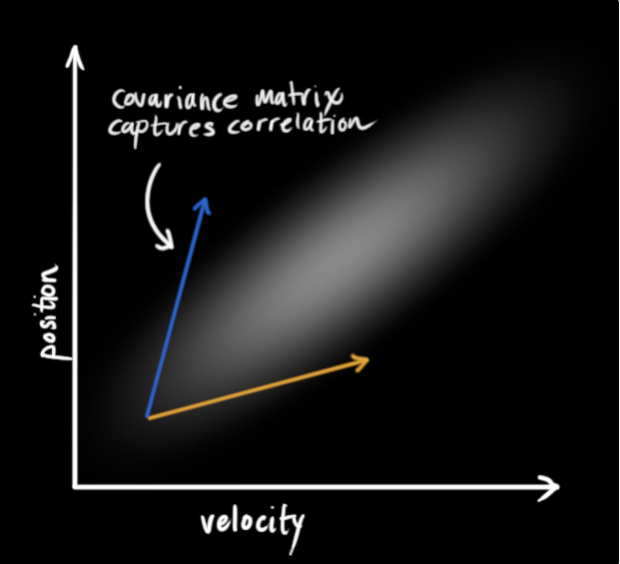
In this case, the correlation between position and velocity is obvious. If our velocity was high, we probably moved farther, so our position will be more distant. This relationship gives us more information about the system; one measurement tells us something about what the others could be.
This correlation is captured by a covariance matrix. Each element of the matrix is the degree of correlation between the i-th state variable and the j-th state variable.
Prediction Matrix
We’re modeling our knowledge about the state as a Gaussian blob, so we need two pieces of information at time : our best estimate , and its covariance matrix , such that
Next, we need to predict the next state at time based on the current state at . This prediction step is done with a prediction matrix , which takes every point in our original Gaussian estimate and moves it to a new predicted location.
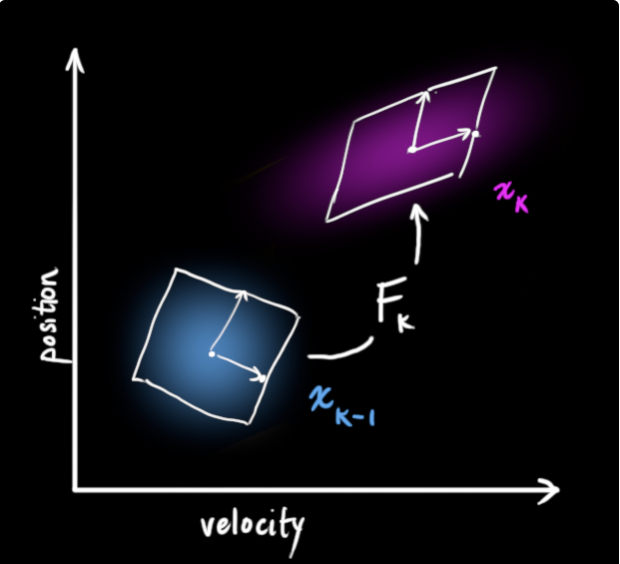
In our position/velocity example, we can formulate a model based on kinematic laws (assuming constant velocity):
In matrix form, this is:
which gives us our prediction matrix which gives us our next state.
Covariance Matrix
We can update the covariance matrix by observing what happens when we multiply every point in a distribution by a matrix :
Thus, our covariance matrix would be updated by:
This is also called the process noise covariance matrix.
Control Matrix & Control Vector
If we know any additional information about the world, we can stuff it into a vector called and add it to our prediction as a correction.
Let’s say we know the expected acceleration 𝑎 due to the throttle setting or control commands. From basic kinematics we get:
In matrix form:
Here, is the control matrix and is the control vector. For very simple systems with no external influence, we can omit these.
Uncertainty
We can model the uncertainty associated with the “world” (i.e. things we aren’t keeping track of or can’t control) by adding some new uncertainty after every prediction step. Every state in our original estimate could have moved to a range of states; each point in is moved to somewhere inside a Gaussian blob with covariance . Another way to say this is that we are treating the untracked influences as noise with covariance – this is called the process noise covariance matrix.
We get the expanded covariance by simply adding , giving our complete expression for the prediction step.
Prediction Step
As such, the new best estimate is is a prediction made from previous best estimate, plus a correction for known external influences. The new uncertainty is predicted from the old uncertainty, with some additional uncertainty from the environment.
Measurement
We might have several sensors which give us information about the state of our system. These give indirect readings; based on the state, the sensors have some transfer function/mapping to their measurement:
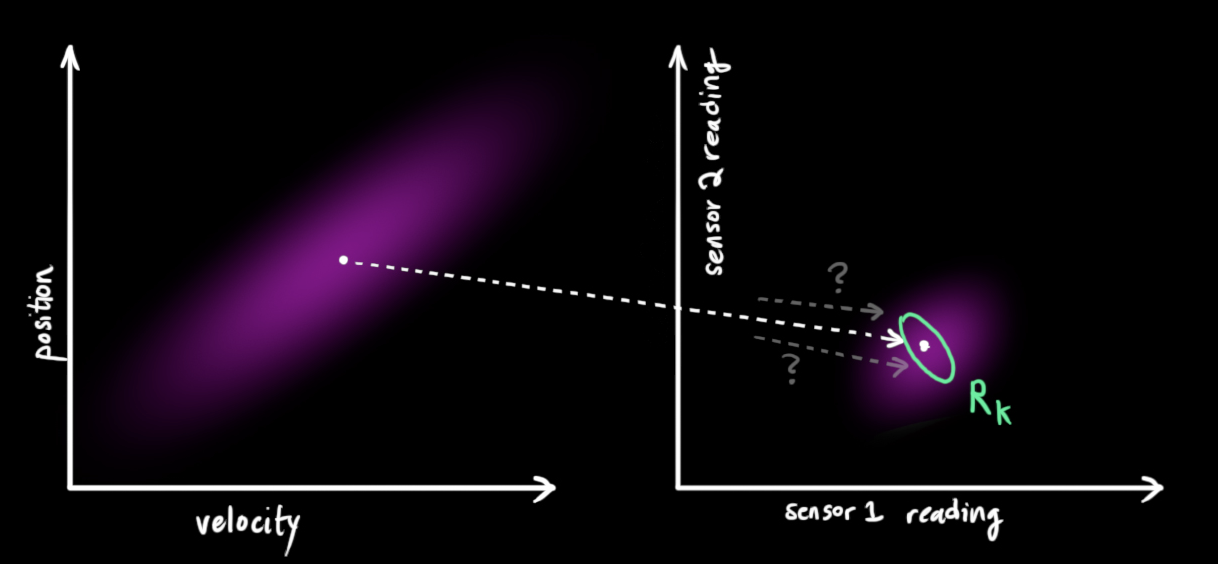
This transfer function can for the sensors can be modeled with a matrix, ; it takes a predicted state vector and turns it into a predicted measurement vector (what the sensor reading should be). This sensor reading distribution is given by:
We also need to deal with sensor noise; every very state in our original estimate might result in a range of sensor readings. The covariance of this uncertainty (sensor noise) is called – this is called the measurement noise covariance matrix.
The distribution has a mean equal to the reading we observed, which we’ll call .
Combining Gaussians
Now we have two Gaussian blobs: one for our prediction, and one surrounding the actual sensor reading we got, which we must reconcile.
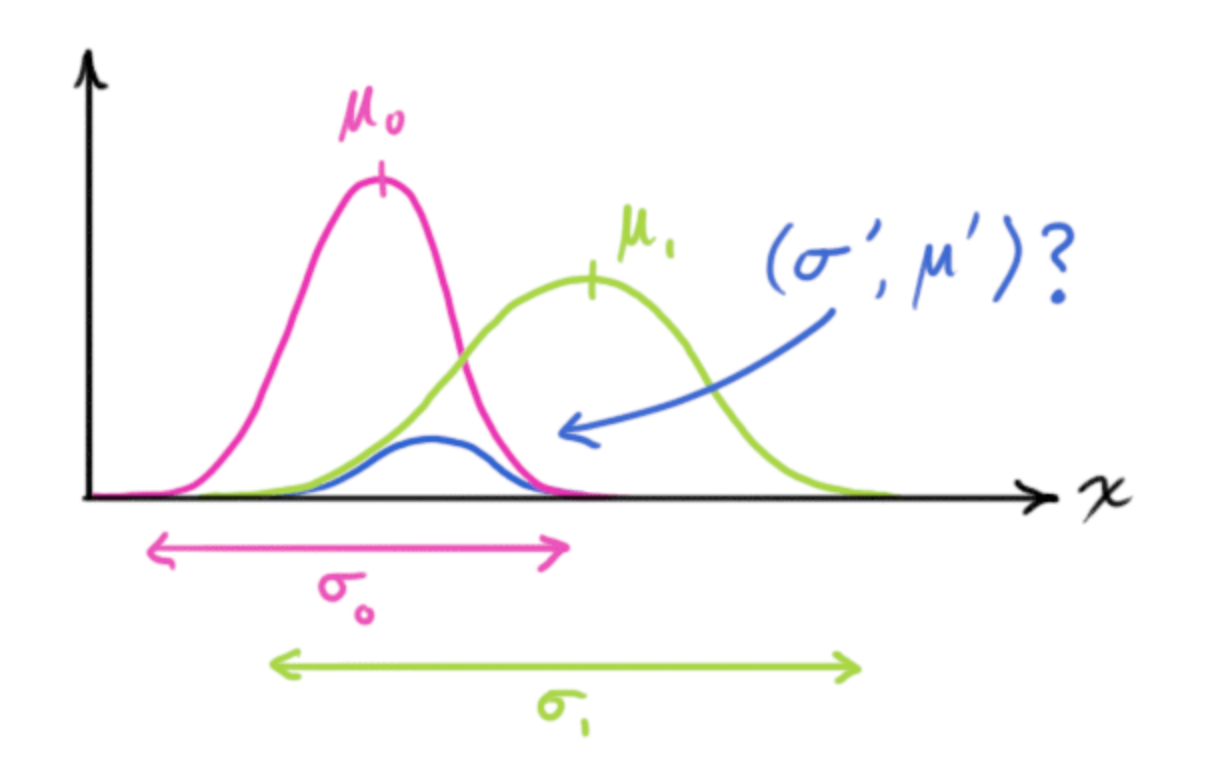
For any possible reading , we have two associated probabilities:
- The probability that our sensor reading is a mis-measurement of
- The probability that our previous estimate thinks is the reading we should see.
If we two probabilities and we want to know the chance that both are true, we just multiply them together. We’re left with the overlap, the region where both blobs are likely. The mean of this distribution is the state for which both estimates are most likely, and is therefore the best guess of the true state given all the information we have.
A distribution found by multiplying two distributions together is given by:
The matrix version of this is:
is a matrix called the Kalman gain, which essentially represents the weight given to the difference between the actual measurement and the predicted state.
- If the Kalman gain is high, the filter places more trust in the latest measurements.
- Conversely, a low Kalman gain indicates more confidence in the model predictions.
Update Step
We have two distributions:
- Prediction:
- Measurement:
Finding the overlap between these:
The Kalman gain is:
We can remove from every term:
That’s it! Our new best estimate is , and we can go on and feed it (along with ) back in, to predict or update as many times as we like.