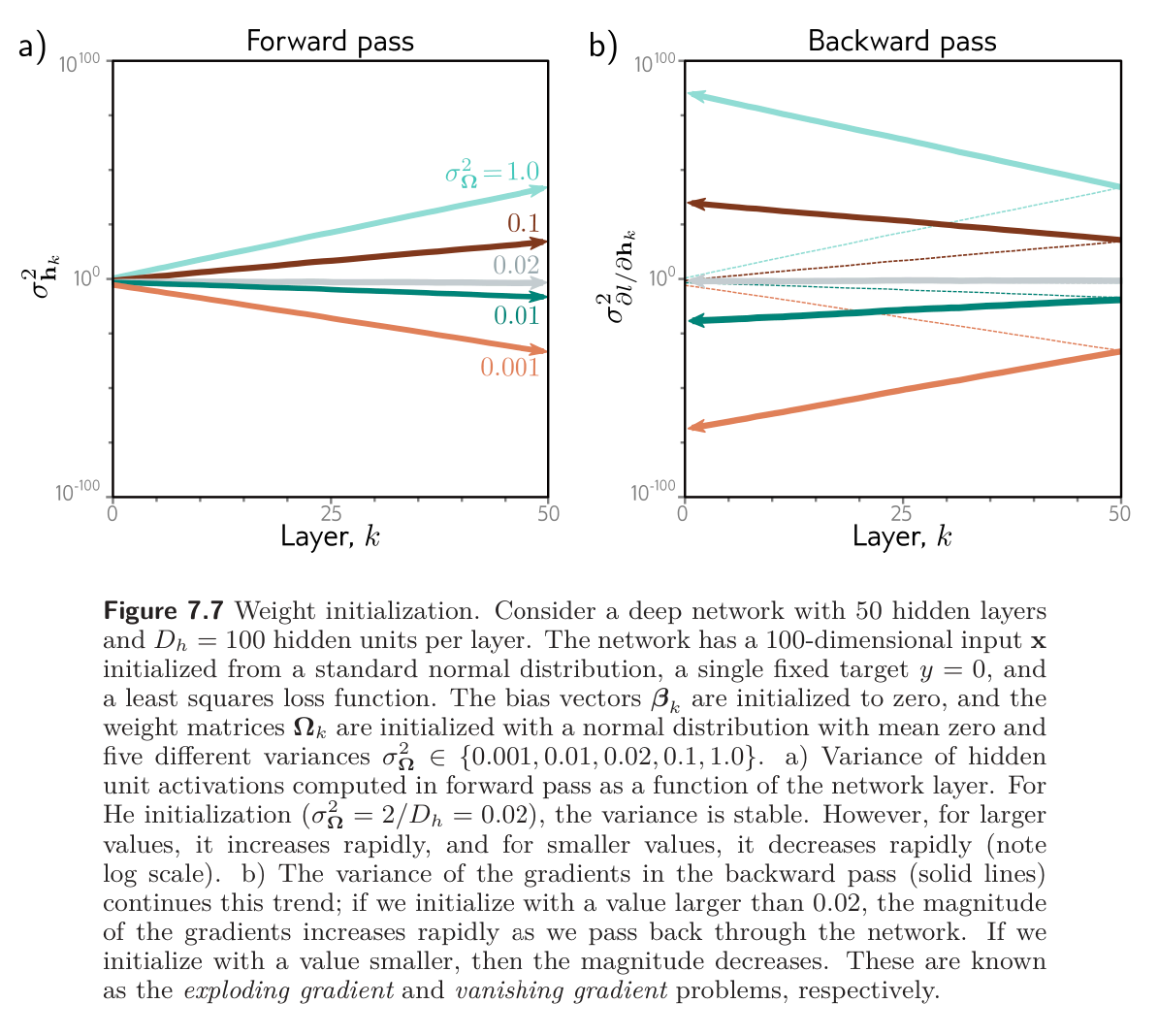
How do we initialize parameters before training?
To see why this is crucial, consider that during the forward pass, each set of pre-activations is computed as:
where applies the ReLU function and and are the weights and biases.
Imagine that we initialize all the biases to zero and elements of according to a normal distribution with mean zero and variance . Consider two scenarios:
- If the variance is very small, then each element of will be a weighted sum of where the weights are very small; the result will likely have a smaller magnitude than the input. In addition, ReLU clips values less than zero, so the range of will be half that of . Consequently, the magnitudes of the pre-activations at the hidden layers will get smaller and smaller as we progress throughout the network.
- If the variance is very large, then each element of will be a weighted sum of where the weights are very large; the result is likely to have much larger magnitude than the input. ReLU function halves the range of the inputs, but if is large enough, the magnitudes of the pre-activations will still get larger as we progress through the network.
In these two situations, the values at the pre-activations can become so small or so large that they cannot be represented with finite precision floating point arithmetic. Even if the forward pass is tractable, the same logic applies to the backward pass. Each gradient update consists of multiplying by . If the values of are not initialized sensibly, then the gradient magnitudes may decrease or increase uncontrollably during the backward pass. These cases are known as the exploding gradient gradient problem, respectively. In the former case, updates to the model become vanishingly small. In the latter case, they become unstable.
Initialization for Forward Pass
Consider the computation between pre-activations and with dimensions and , respectively:
where represents the activations, and represent the weights and biases, and is the activation function.
Purpose
Our aim here is to derive an expression for the variance of the output pre-activations as a function of the variance of the the input layer . Then, we can use this to reason about how we should initialize so that the variance stays stable.
Assume the pre-activations in the input layer have variance . The biases are initialized to zero, and the weights are initialized as normally distributed with mean zero and variance .
Now we derive expressions for the mean of the pre-activations in the subsequent layer.
The mean for each row of the pre-activation :
- This assumes that the distribution over the hidden units and the network weights are independent between the second and third lines.
Using this result, we see that the variance, of the pre-activations is:
where we have used the variance identity . We’ve also assumed again that the distribution of the weights and the hidden units are independent between lines 3 and 4.
Assuming that the distribution of pre-activations at the previous layer is symmetric about zero, half of these pre-activations are clipped by the ReLU function, and the second moment will be half of , the variance of :
This implies that if we want the variance of the subsequent pre-activations to be the same as the variance of the original pre-activations during the forward pass, we should set
where is the dimension of the original layer to which the weights were applied. This is known as He initialization.
Initialization for backward pass
A similar argument establishes how the variance of the gradients changes during the backward pass. During the backward pass, we multiply by the transpose of the weight matrix, so the equivalent expression becomes:
where is the dimension of the layer that the weights feed into.
Initialization for both forward & backward
If the weight matrix is not square (there are different numbers of hidden units in the two adjacent layers, so and differ), then it is not possible to choose the variance to satisfy both and simultaneously.
One possible compromise is to use the mean as a proxy for the number of terms, which gives:
The figure below shows empirically that both the variance of the hidden units in the forward pass and the variance of the gradients in the backward pass remain stable when the parameters are initialized appropriately.