Problem 8.1
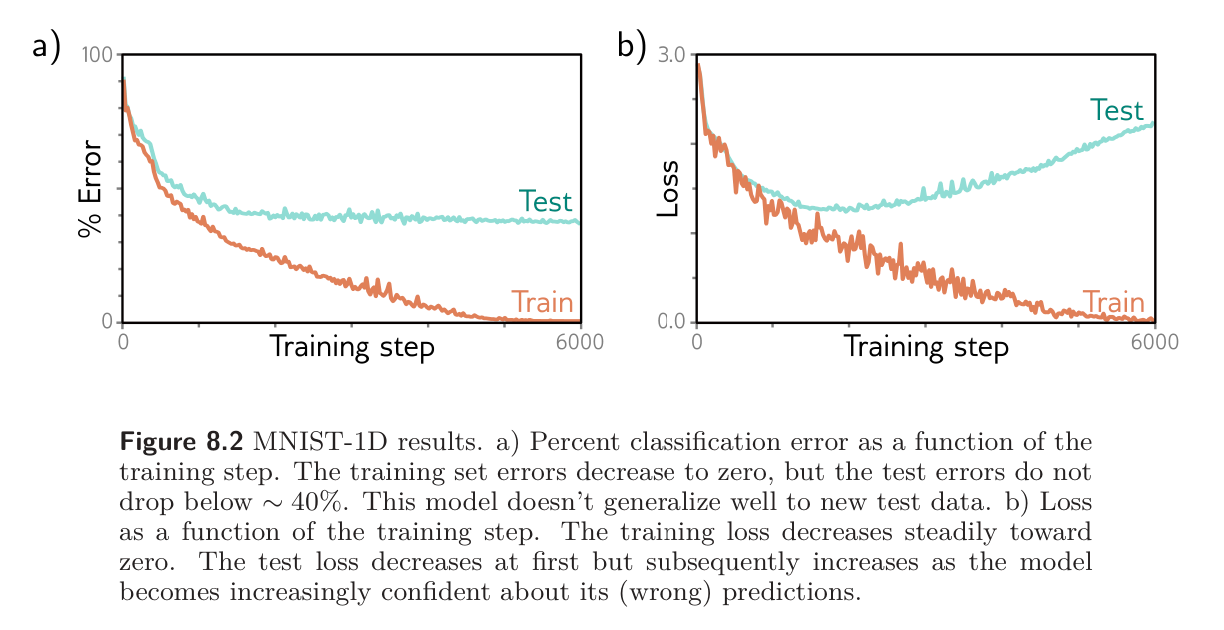
Will the multiclass cross-entropy loss in figure 8.2 ever reach zero? Explain your reasoning.
In multi-class classification, the likelihood that input has label is:
and the loss function is the negative log-likelihood of the training data:
Thus, for the loss to be zero, we need to be . This is impossible as only for . With any finite parameters, we will have . Thus, although we can get arbitrarily close to zero, we will never get exactly zero.
Problem 8.2
What values should we choose for the three weights and biases in the first layer of the model in figure 8.4a so that the hidden unit’s responses are as depicted in figures 8.4b–d?
- The weights should all be .
- First bias:
- Second bias:
- Third bias:
Problem 8.3
Given a training dataset consisting of input/output pairs , show how the parameters for the model in figure 8.4a using the least squares loss function can be found in closed form.
The first part of the network is deterministic since we’ve fixed the weights and the biases between the input and the first hidden layer. Thus, we can compute the activations at the hidden units for any input. Denoting these by , we can write out the output layer now have a linear regression problem:
where indexes the training data. This can be solved in closed form with Ordinary Least Squares for example.
Problem 8.4
Consider the curve in figure 8.10b at the point where we train a model with a hidden layer of size 200, which would have 50,410 parameters. What do you predict will happen to the training and test performance if we increase the number of training examples from 10,000 to 50,410.
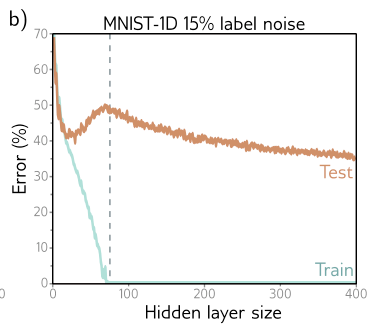
The training performance would be worse than before, as the number of model parameters compared to training examples is less than before, making the training set harder to memorize. However, testing performance may be better; with more data, variance decreases, resulting in less test error. One can also argue that noise, while irreducible, is diluted in this case because the model can rely on more clean samples.
Problem 8.5
Consider the case where the model capacity exceeds the number of training data points, and the model is flexible enough to reduce the training loss to zero. What are the implications of this for fitting a heteroscedastic model? Propose a method to resolve any problems that you identify.
Recall that heteroscedastic means that the uncertainty of the model varies as a function of input data.
In this case, we would typically predict the variance as a model output in the training process. However, if we are overparametrized, there are no residuals to train the variance on, so the variance would always be zero.
Some ways to deal with this would be to compute residuals on held-out predictions and train the variance on those instead of in-sample points. Or, we could constrain by putting some floor variance. The obvious best thing to do would be regularization to keep the model from perfectly fitting but the point here is to overfit I think.
Problem 8.6
Show that two random points drawn from a 1000-dimensional Gaussian distribution are orthogonal relative to the origin with high probability.
Let be independent with , taking . The angle between them is
Gaussian vectors are rotationally invariant. We can rotate coordinates so that the unit vectors in the direction of is . Then
where is a uniform random point on the unit sphere and is its first coordinate. So, the problem reduces to understanding the first coordinate of a random unit vector.
By symmetry, . Also, since and all coordinates are identically distributed,
Thus
Thus, a typical size of is . For , that’s about , so the two points are nearly orthogonal.
Problem 8.7
The volume of a hypersphere with radius in dimensions is:
where is the Gamma Function. Show using Stirling’s Formula that the volume of a hypersphere of diameter one (radius ) becomes zero as dimension increases.
Let be the dimension and . Write . The volume is
Using Stirling’s formula gives us:
Hence:
As , we will have . Therefore:
Problem 8.8
Consider a hypersphere of radius . Find an expression for the proportion of the total volume that lies in the outermost 1% of the distance from the center (i.e., in the outermost shell of 0.01). Show that this becomes one as the dimension increases.
The volume is given by:
Volume of a hypersphere of radius is given by:
The proportion in the last percentage is hence:
We have as .
Problem 8.9
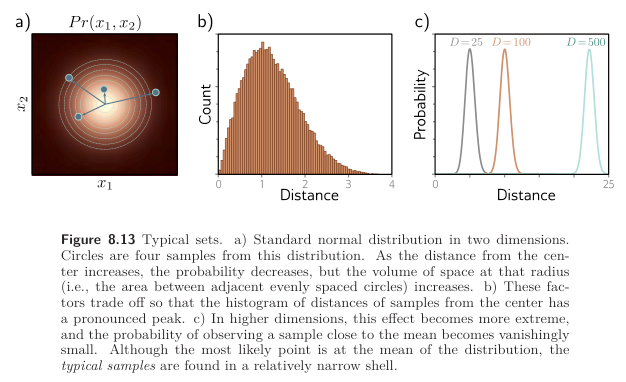
Figure 8.13c shows the distribution of distances of samples of a standard normal distribution as the dimension increases. Empirically verify this finding by sampling from the standard normal distributions in 25, 100, and 500 dimensions and plotting a histogram of the distances from the center. What closed-form probability distribution describes these distances?
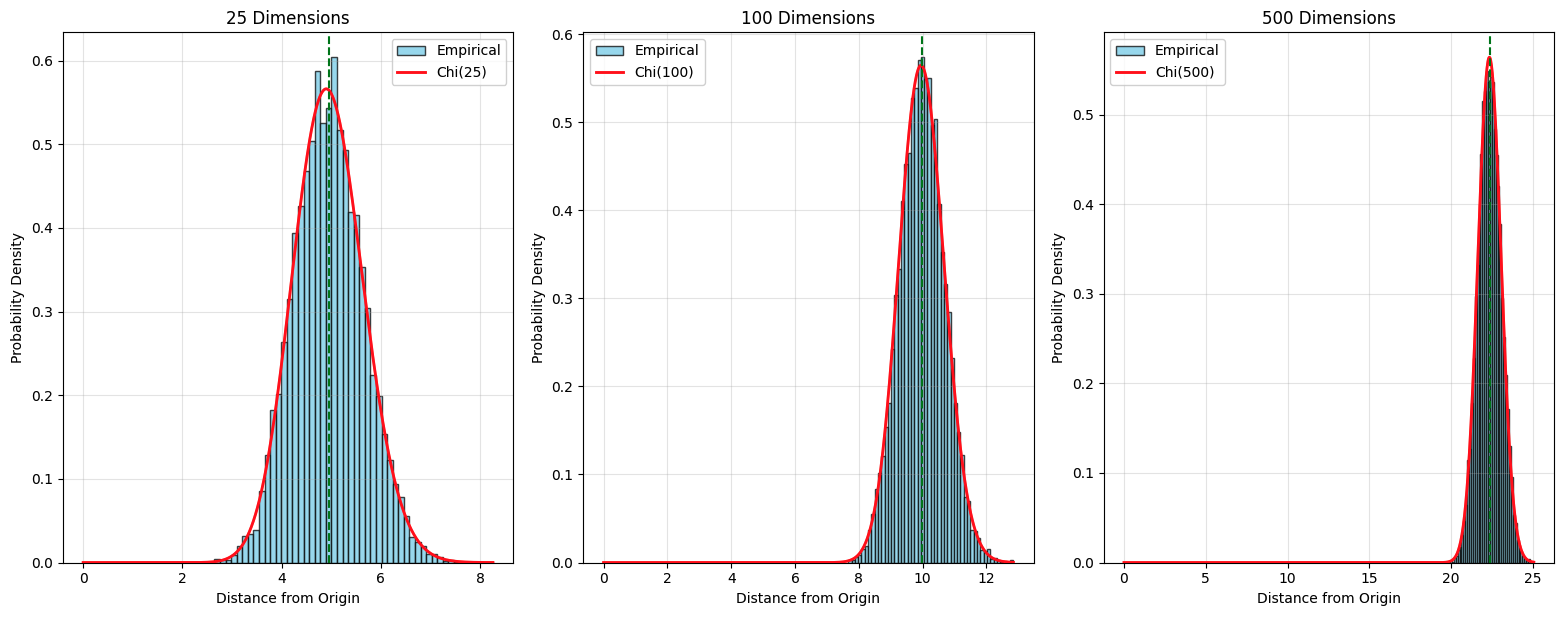
25 Dimensions:
- Mean distance: 4.9506
- Std distance: 0.7010
- Theoretical mean: 6.2666
100 Dimensions:
- Mean distance: 9.9846
- Std distance: 0.7034
- Theoretical mean: 12.5331
500 Dimensions:
- Mean distance: 22.3492
- Std distance: 0.7029
- Theoretical mean: 28.0250
The distances from the origin of samples from standard normal distributions follow a Chi distribution with degrees of freedom equal to the number of dimensions.
Key properties:
- Mean for large
- The distribution becomes more concentrated around as increases
- This is the theoretical foundation for the curse of dimensionality.