As an entrypoint to deep neural networks, we first consider composing two shallow neural networks so that the output of the first becomes the input of the second.
Consider two shallow networks with 3 hidden units each.

The first network takes an input and returns output and is defined by:
and
The second network takes as input and returns and is defined by:
and
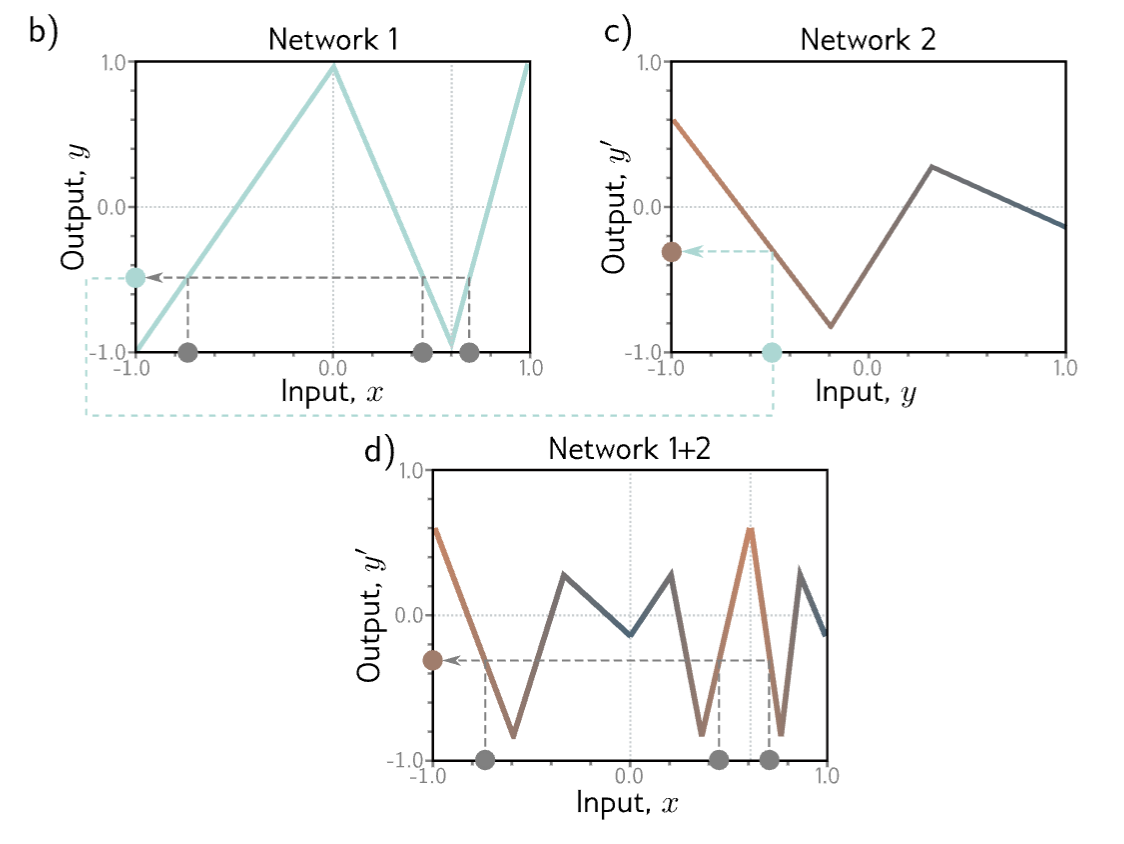
- The first network maps inputs to outputs using a function comprising three linear regions that are chosen so that they alternate the sign of their slope (4th linear region is outside range of graph). Multiple inputs (gray circles) now map to the same output (cyan circle).
- The second network defines a function comprising three linear regions that takes and returns (i.e. the cyan circle is mapped to the brown circle).
- The combined effect of these 2 functions when composed is that three different inputs are mapped to any given value of by the first network and are processed the same way by the second network.
- The result is that the function defined by the second network in panel (c) is duplicated three times, variously flipped and rescaled according to the slope of the regions of panel (b).
With ReLU activations, this model also describes a family of piecewise linear functions. However, the number of linear regions is potentially greater than for a shallow network with 6 hidden units. To see this, consider choosing the first network to produce three alternating regions of positive and negative slope (panel b above). This means that three different ranges of are mapped to the same output range , and the subsequent mapping from this range of to is applied three times. The overall effect is that the function defined by the second network is duplicated three times to create nine linear regions.
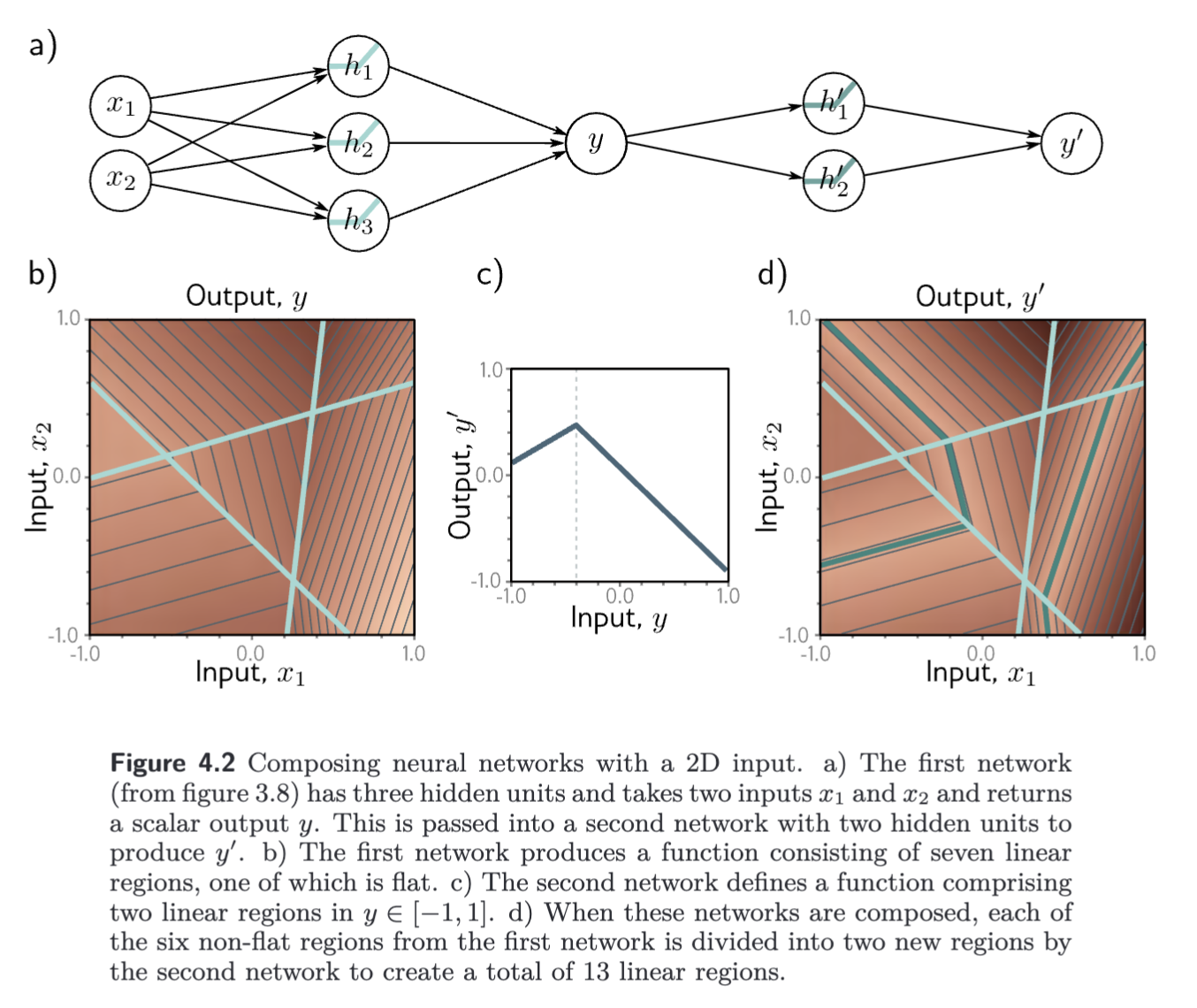
The same principle applies in higher dimensions as well.
A different way to think about composing networks is that the first network “folds” input space onto itself so that multiple inputs generate the same output. Then the second network applies a function, which is replicated at all points that were folded on top of one another.
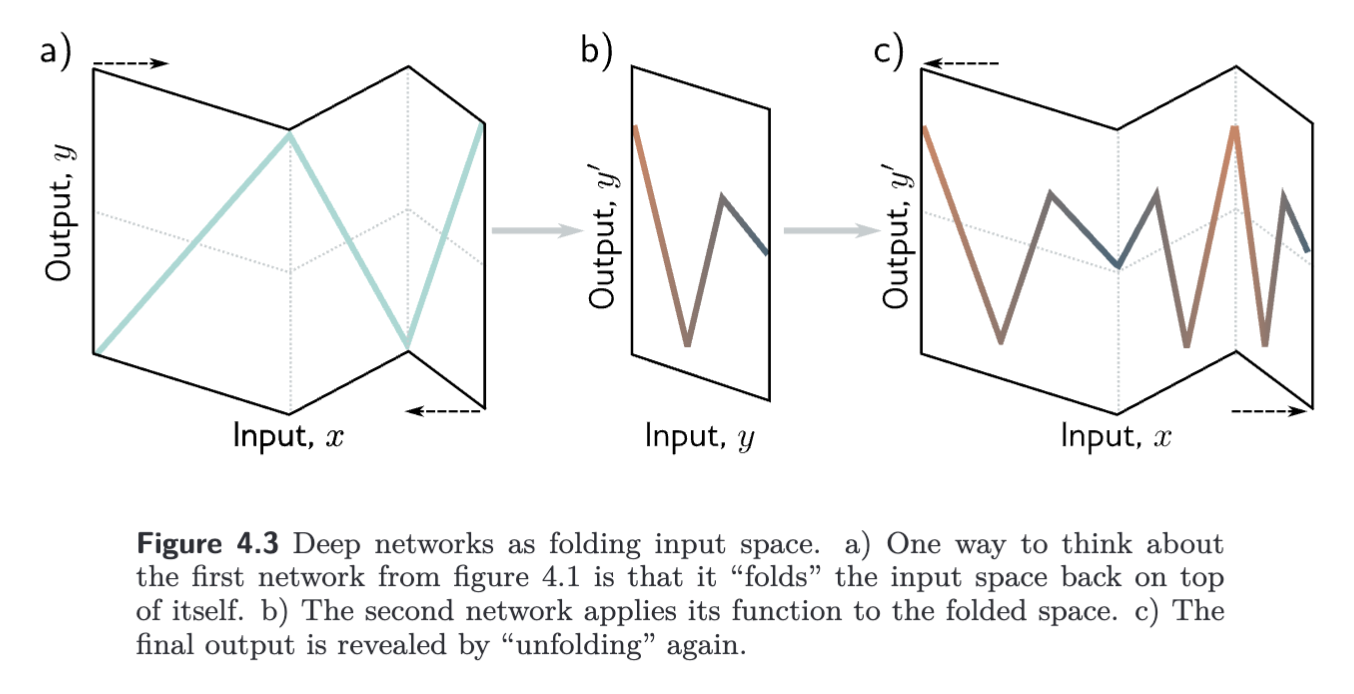
From composing networks to deep networks
We can show that our composition of networks is a special case of a Deep Neural Network with two hidden layers. The first layer is defined by
The output of the first network () is a linear combination of the activations of the hidden units. The first operations of the second network () are linear in the output of the first network. Applying one linear function to another yields another linear function.
Substituting the expression for in the calculation of hidden units in the second network gives:
which can be re-written as:
where and so on. Finally we can define the output by:
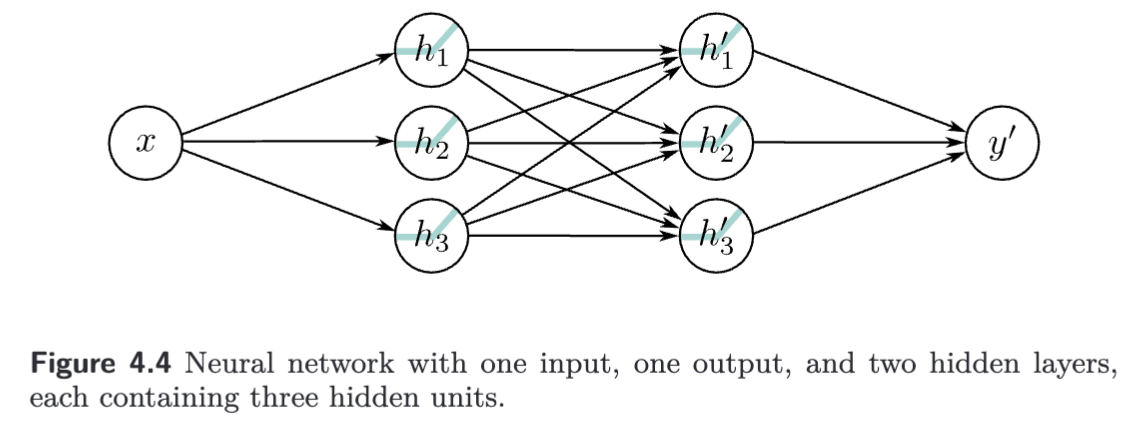
The result is a network with two hidden layers.
It follows that a network with two layers can represent the family of functions created by passing the output of one single-layer network into another. It represents a broader family, because the nine slope parameters, can take arbitrary values, whereas the original parameters are constrained to be the outer product .
Considering the above equations leads to another way of thinking about how the network constructs an increasingly complex function:
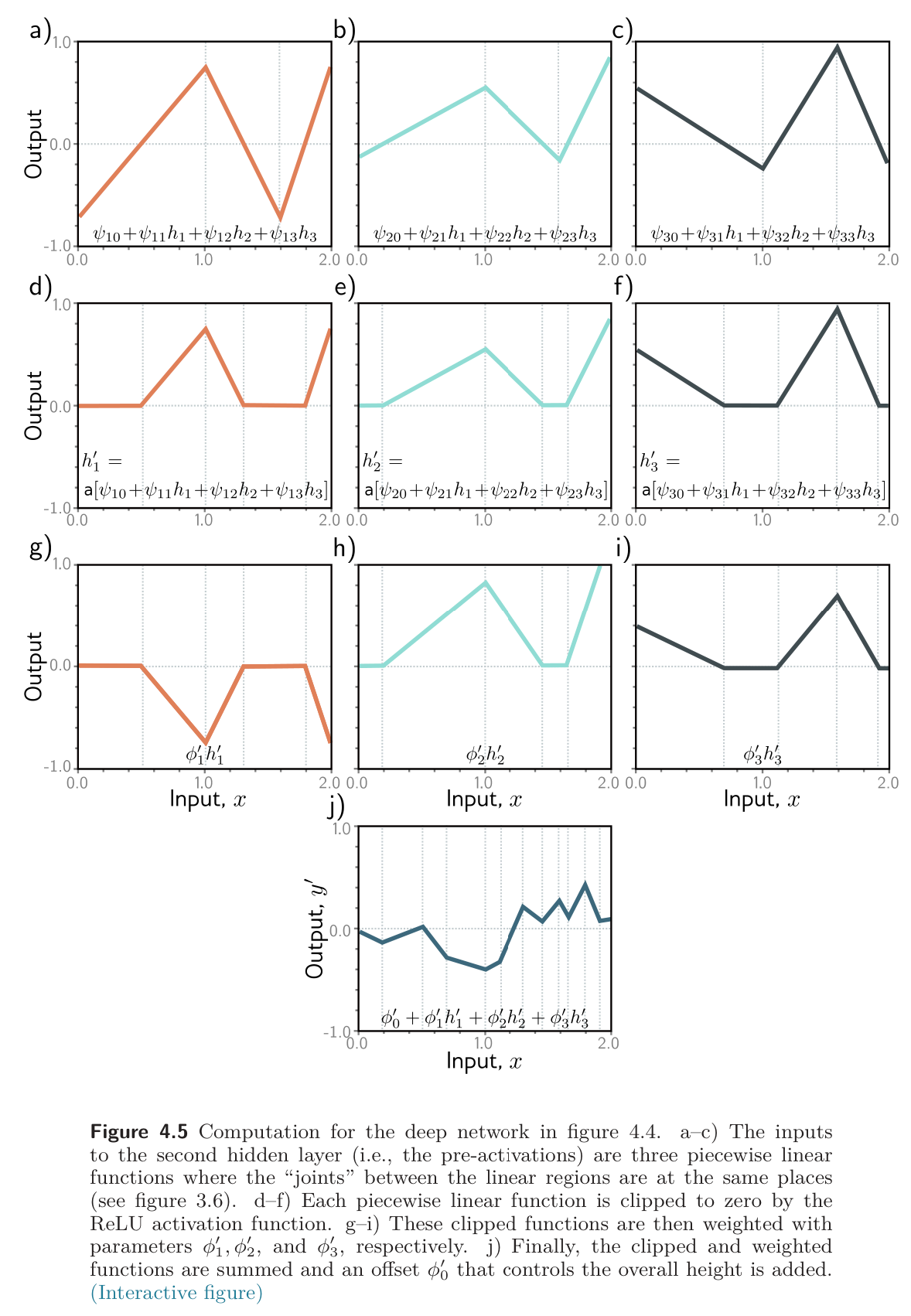
- The three hidden units and in the first layer are computed as usual by forming linear functions of the input and passing these through ReLU activation functions.
- The pre-activations at second layer are computed by taking three new linear functions of these hidden units. At this point, we effectively have a shallow network with three outputs; we have computed three piecewise linear functions with the “joints” between linear regions in the same places.
- At the second hidden layer, another ReLU function is applied to each function, which clips them and adds new “joints” to each.
- The final output is a linear combination of these hidden units.
We can think of each layer as “folding” the input space or as creating the new functions, which are clipped (creating new regions) and then recombined. The former view emphasizes the dependencies in the output, but not how clipping creates new joints, and the latter has the opposite emphasis. Both only provide partial insight into how deep neural networks operate.
It’s important to not lose sight of the fact that this is still merely an equation relating input to output . We can combine all the equations to get one expression:
Matrix Notation
We can describe our composition above in matrix notation as:
and
and
or even more compactly as
where, in each case, the function applies the activation function separately to every element of its vector input.