Shallow neural networks are functions with parameters map multi-dimensional inputs to a multi-dimensional output using hidden units. Each hidden unit is computed as:
which are combined linearly to create an output.
Intuition
We can illustrate the main ideas using an example network that maps a scalar input to a scalar output , using ten parameters . This is defined such that:
This calculation can be broken down into three parts:
- We compute three linear functions of the input data, , and
- We pass the three results through an activation function
- We weight the three resulting activations with , and , sum them, and then add an offset .
Equation characterizes a family of functions where the particular member of the family is characterized by the parameters . Given these parameters, we can perform inference to predict by evaluating the equation on a given . Given a data set , we can define a loss function and use it to measure how effectively the model describes the data set for this given set of parameters . To train the model, we search for the values that minimize loss.
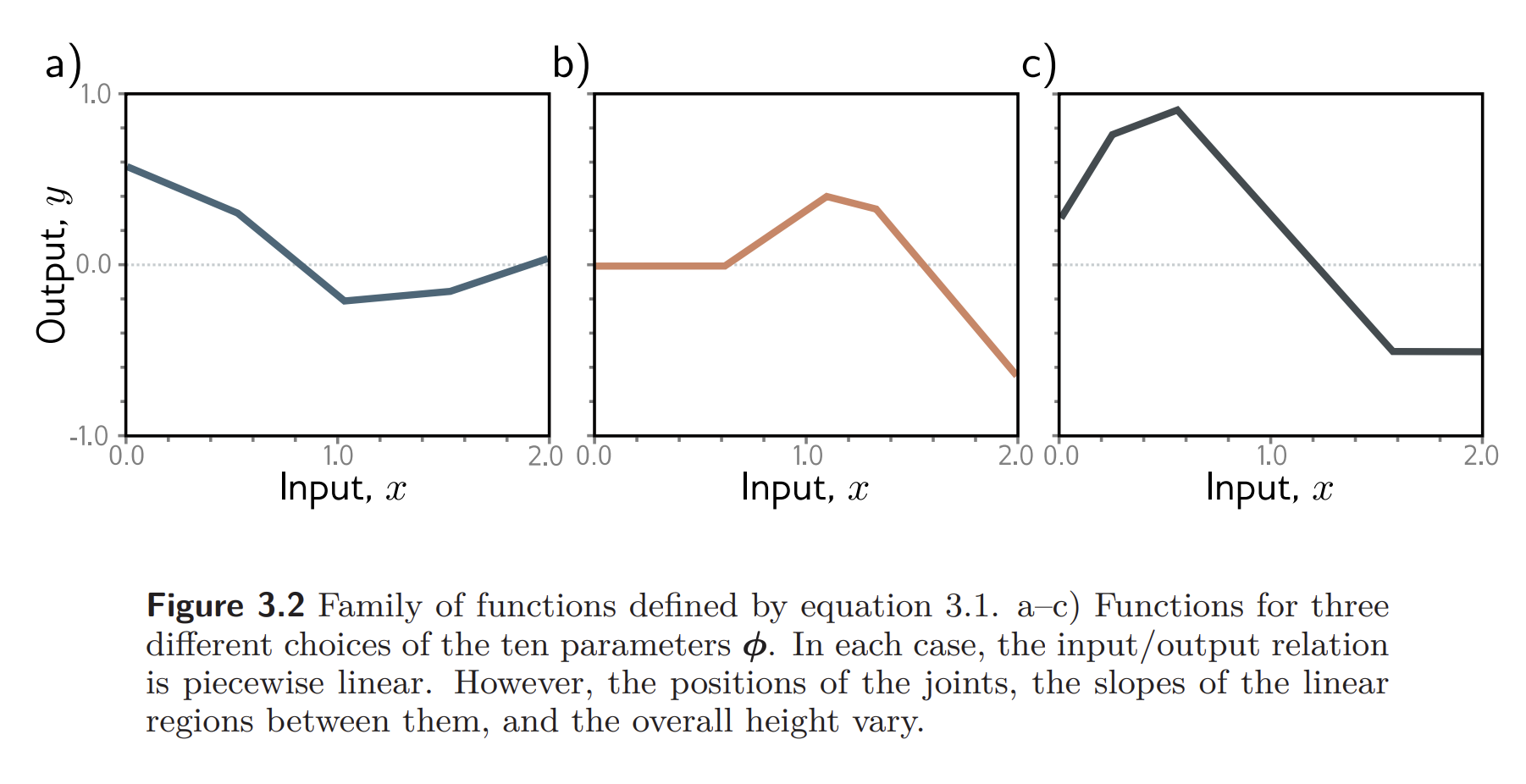
To gain more intuition, we can think about what equation actually represents. It is a family of piecewise functions with up to four linear regions. This can be easily seen by splitting up the quantities, which we call hidden units:
The output of then be found by combining these hidden units with a linear function:
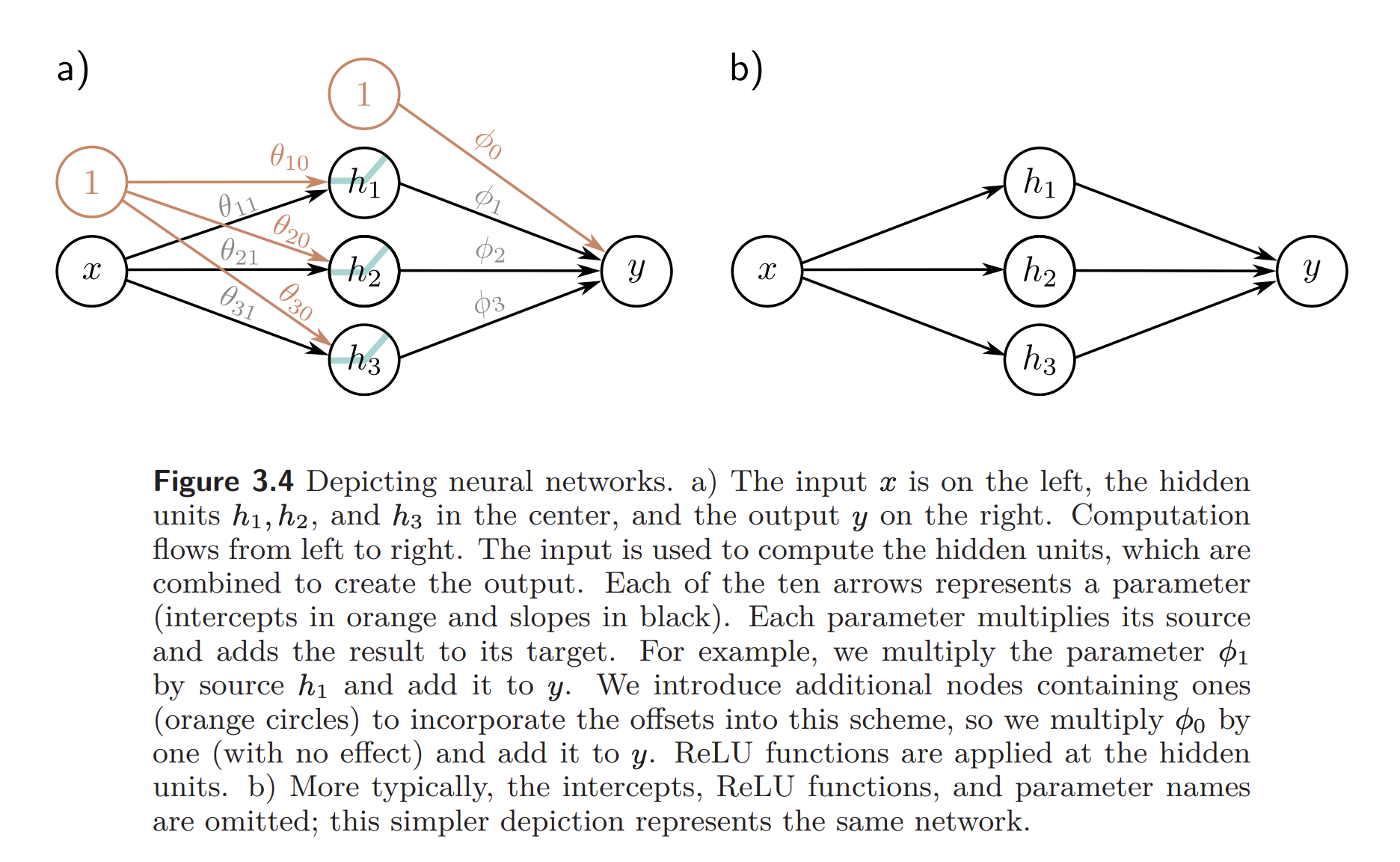
The flow of computation is shown here:
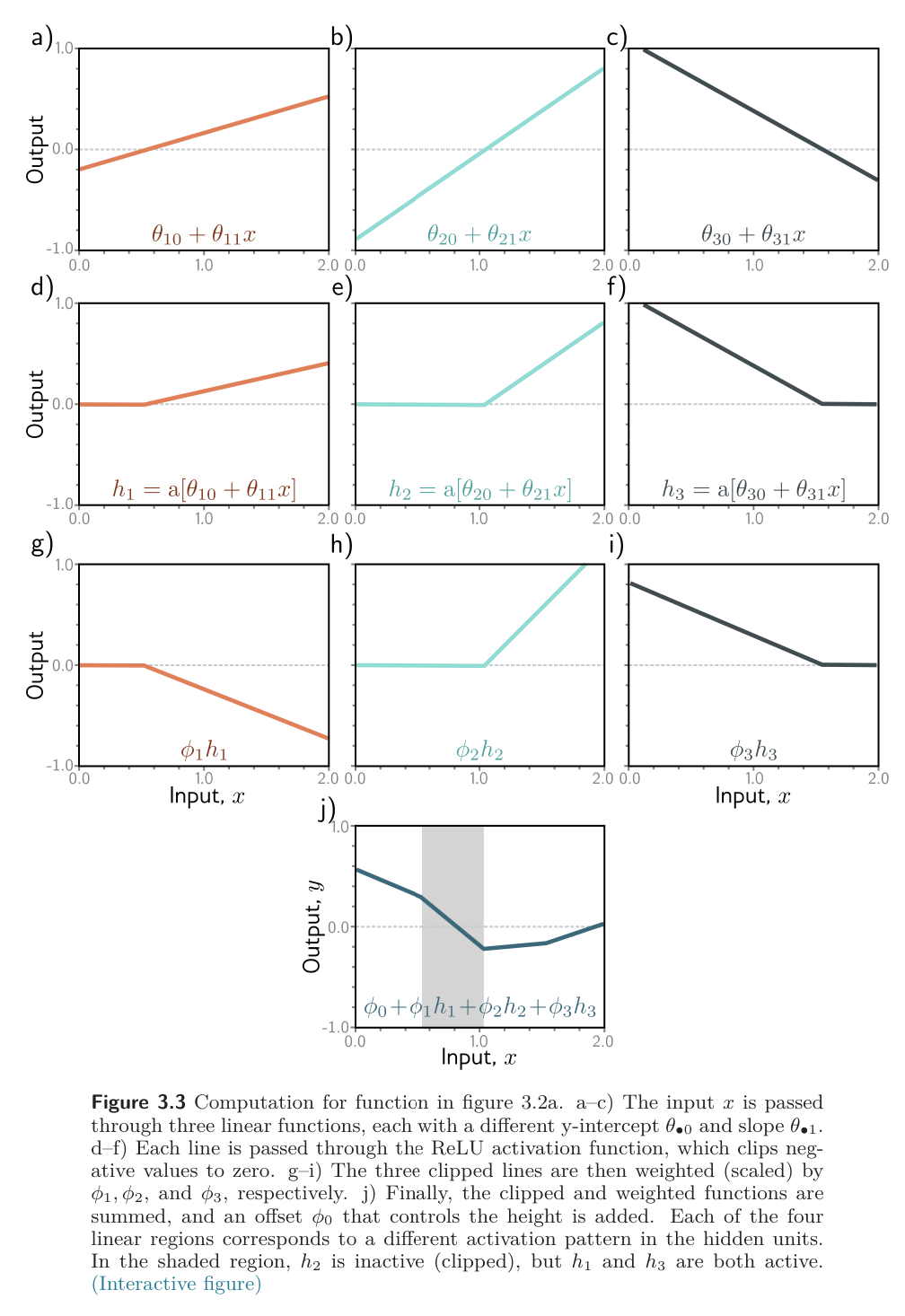
- Each hidden unit contains a linear function .
- This line is clipped by the ReLU below zero.
- The positions where the three lines cross zero become the “joints” in the output.
- The three clipped lines are then weighted by .
- Finally, the offset is added.
Each linear region corresponds to a different activation pattern in the hidden units. When a unit is clipped, its referred to as inactive; when it’s not clipped, we say it’s active.
- For example, the shaded region above has and active, while is inactive.
The slope of each linear region is determined by the original slopes and the weights that were subsequently applied.
- For example, the slope in the shaded region is , where the first term is the slope in panel (g) and the second is the slope in panel (i).
Each hidden unit contributes one “joint” to the function, so with three hidden units, there can be four linear regions. However, only three of the slopes of these regions are independent; the fourth is either zero (if all the hidden units are inactive in this region) or is a sum of slopes from the other regions.
A network may also have multivariate inputs and outputs.
Network Visualization
The network we’ve been discussing has one input, one output, and three hidden units. This can be depicted as such: