The rectified linear unit is a standard activation function; it returns the input when it is positive and zero otherwise:
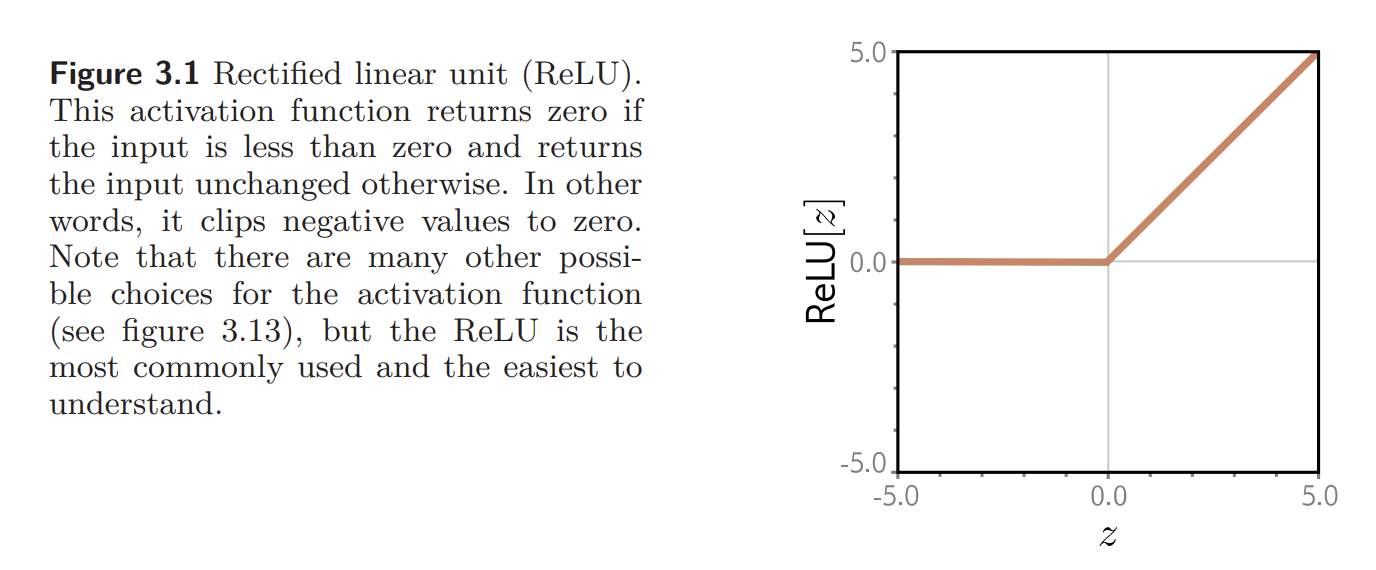
The ReLU has a nice property that the derivative of the output with respect to the input is always one for inputs greater than zero. This contributes to the stability and efficiency of training, unlike sigmoid activation functions, which saturate (become close to zero) for large positive and large negative inputs.
The non-negative homogeneity property of the ReLU function states that:
for .