Consider a model with eight scalar parameters that consists of a composition of functions and :
and a least squares loss function with individual terms:
where is the -th training input, and is the -th training output. You can think of this as a simple neural network with one input, one output, one hidden unit at each layer, and different activation functions and between each layer.
We aim to compute the derivatives of with respect to each of the eight parameters:
Of course, we could find expressions for these derivatives by hand and compute them directly. However, some of these expressions are quite complex. Such expressions are awkward to derive and code without mistakes and do not exploit the inherent redundancy.
Backpropagation is an efficient method for computing all of these derivatives at once. It consists of a forward pass, in which we compute and store a series of intermediate values and the network output, and a backward pass, in which we calculate the derivatives of each parameter, starting at the end of the network, and re-use previous calculations as we move toward the start.
Forward Pass
We treat the computation of the loss as a series of calculations:

We compute and store the values of the intermediate variables and .
Backward pass 1
We now compute the derivatives of with respect to these intermediate variables, but in reverse order.

The first one is very straightforward:
The next derivative can be calculated using the chain rule:
- The left side asks how changes when changes
- The right side says we can decompose this into (i) how changes when changes and (ii) how changes when changes. In the original equations, changes , which changes , and the derivatives represent the effects of this chain. Notice that we already computed the first derivative and the other is just the derivative of with respect to .
We can continue this way:
In each case, we already calculated the quantities in the brackets in the previous step, and the last term has a simple expression. These equations embody Observation 2 we made in Backpropagation Intuition; we can reuse the previously computed derivatives if we calculate them in reverse order.
Backward pass 2
Finally, we consider how the loss changes when we change the parameters and .
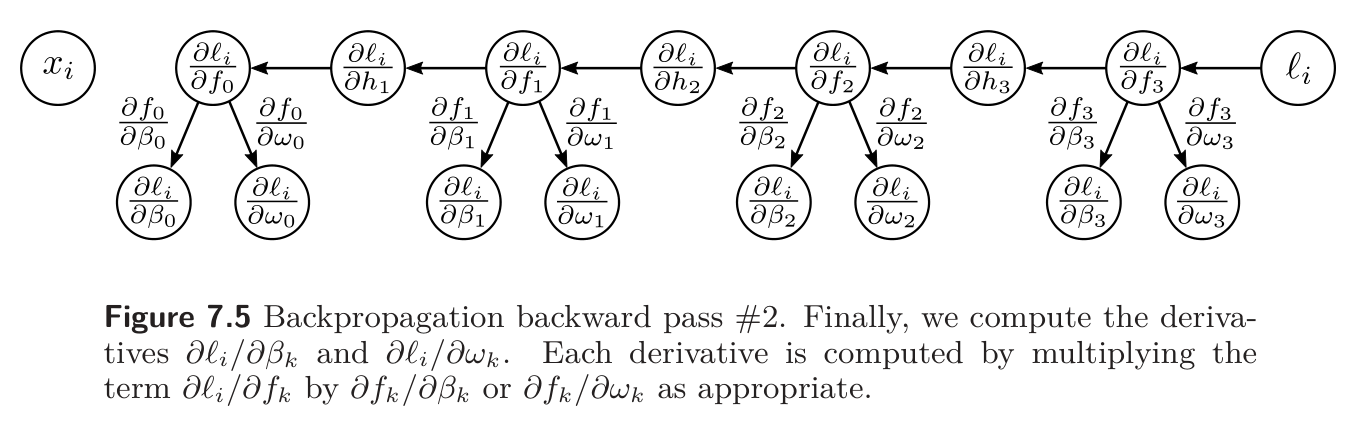
Once again, we apply the chain rule:
In each case, the first term on the right side was already computed above. When , we have = , so
This is consistent with Observation 1 from Backpropagation Intuition; the effect of a change in the weight is proportional to the value of the source which was stored in the forward pass. The final derivatives from the term are:
Backpropagation is both simpler and more efficient than computing the derivatives individually.