Often, we want to have our network map multivariate inputs to multivariate output predictions .
Multivariate Outputs
To extend the network to multivariate outputs , we simply use a different linear function of the hidden units for each output. So, a network with a scalar input , four hidden units , and a 2D multivariate output would be defined as
and
The two outputs are two different linear functions of the hidden units.
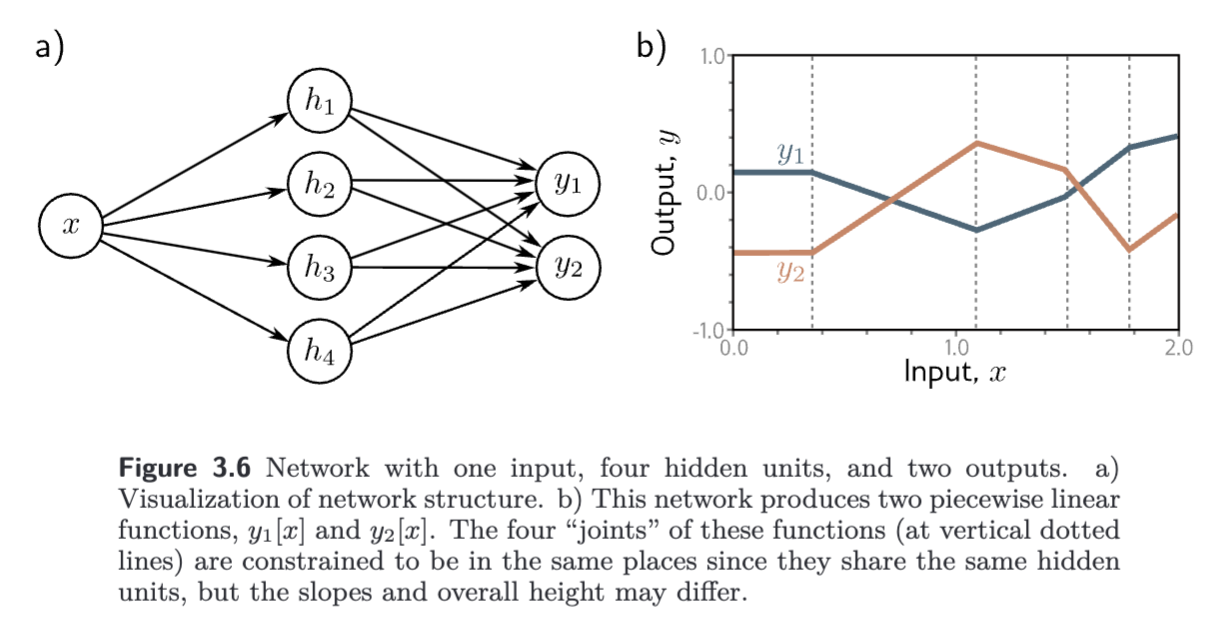
- Recall (from Shallow Neural Network) that the joints in the piecewise functions depend on where the initial functions are clipped by the ReLU functions at the hidden units.
- Since both outputs and are different linear functions of the same four hidden units, the four joints are at the same places.
- However, the slopes of the linear regions and the overall vertical offset can differ, since these are applied after the ReLU.
Multivariate Inputs
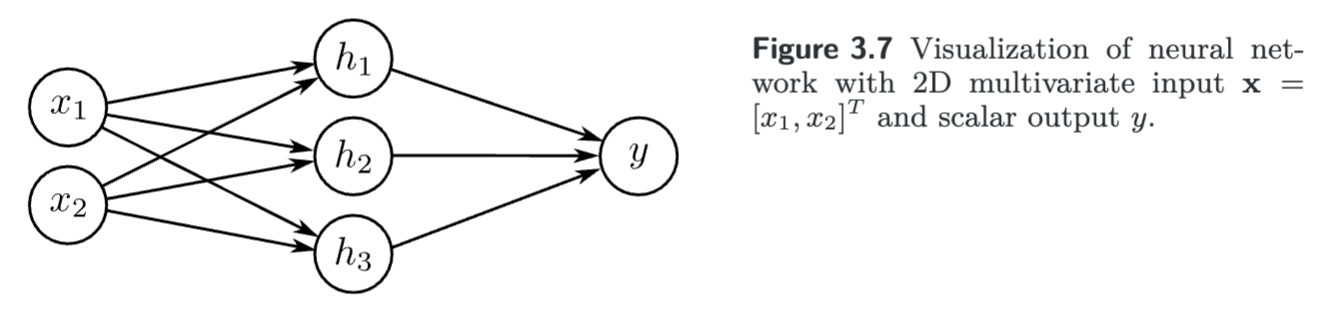
For multi variate inputs , we extend the linear relations between the input and the hidden units. So, a network with two inputs and a scalar output might have 3 hidden units defined by:
where there is now one slope parameter for each input. The hidden units are combined to form the output in the usual way:
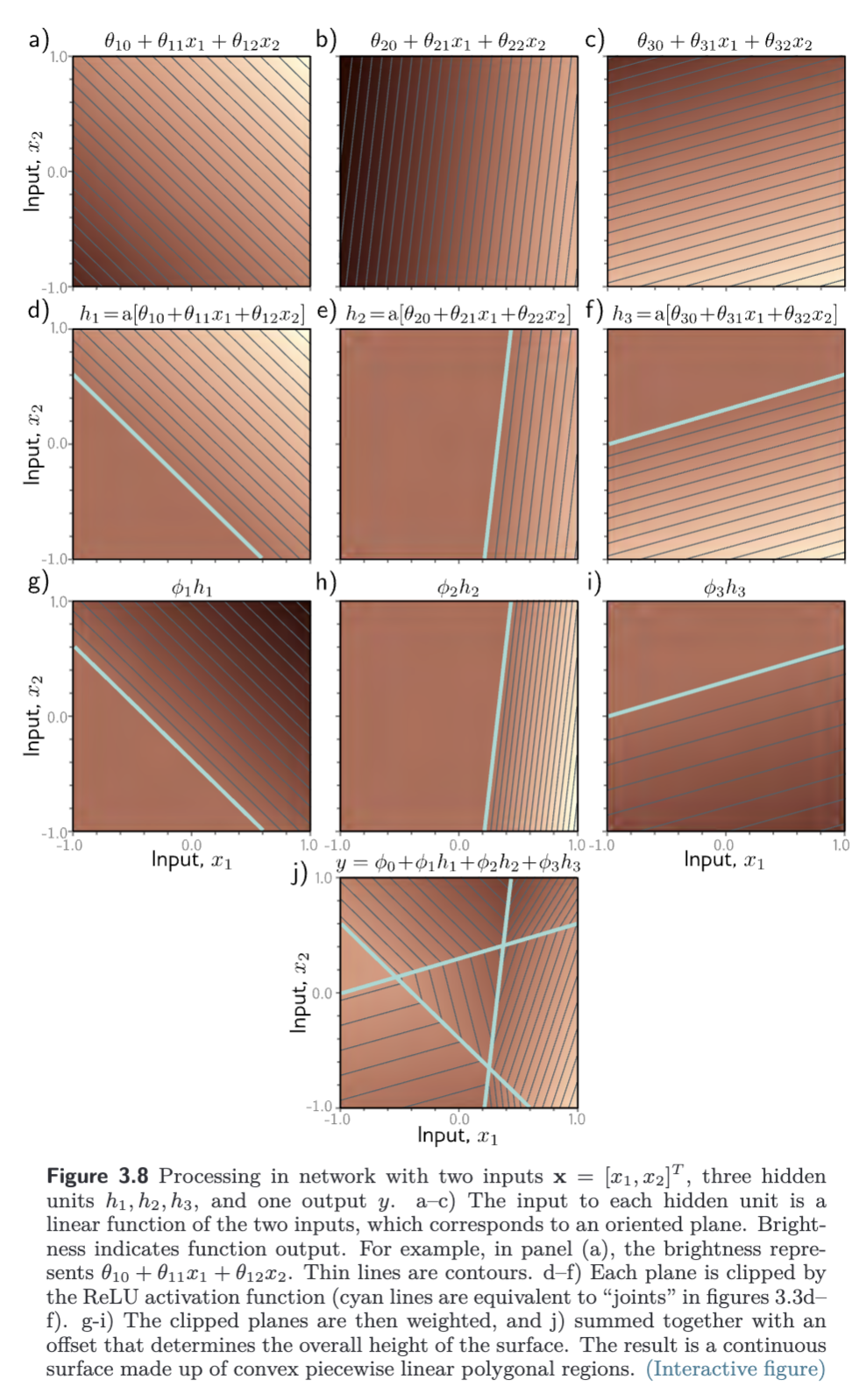
- Each hidden unit receives a linear combination of the two inputs, which forms an oriented plane in the 3D input/output space.
- The activation function clips the negative values of these planes to zero.
- The clipped planes are then recombined in a second linear function to create a continuous piecewise linear surface consisting of convex polygonal regions.
- Each region corresponds to a different activation pattern. For example, in the central triangular region, the 1st and 3rd hidden units are active, with the 2nd inactive.
With more than 2 inputs, the visualization becomes difficult, but the interpretation is similar; the output is just a continuous piecewise linear function of the output, where the linear regions are now convex polytopes in the multi-dimensional input space.