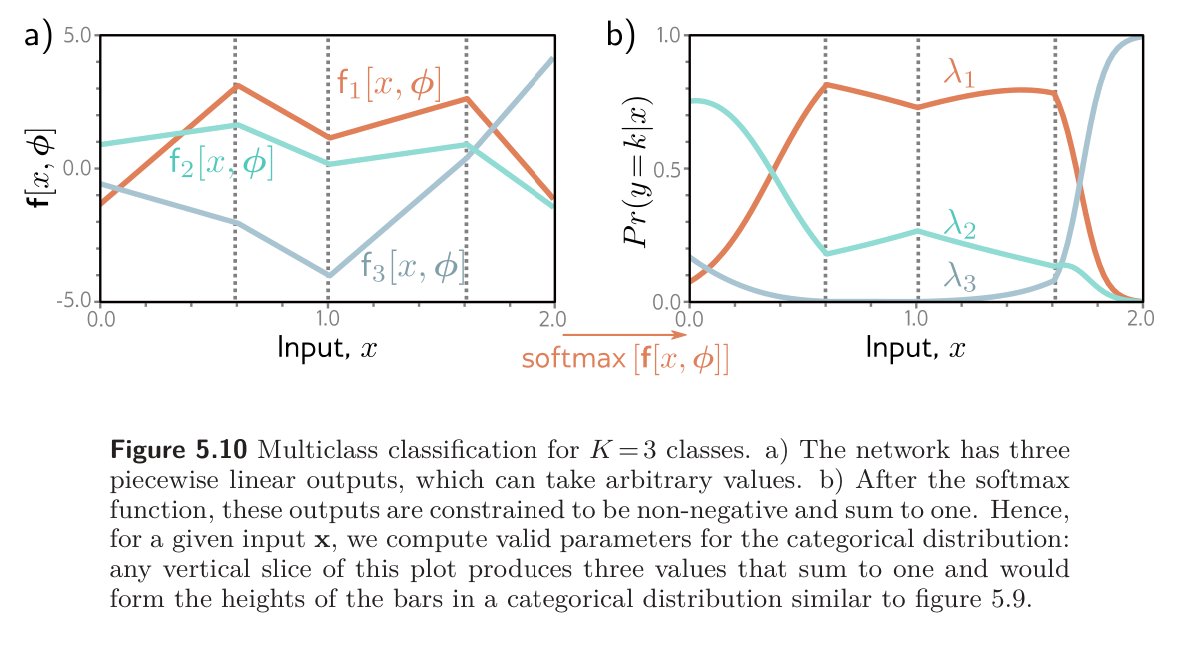
The goal of multi-class is to assign an input data example to one of classes, so .
Examples:
- Predicting which of digits is present in an image of a handwritten number
- Predicting which of possible words follows an incomplete sentence
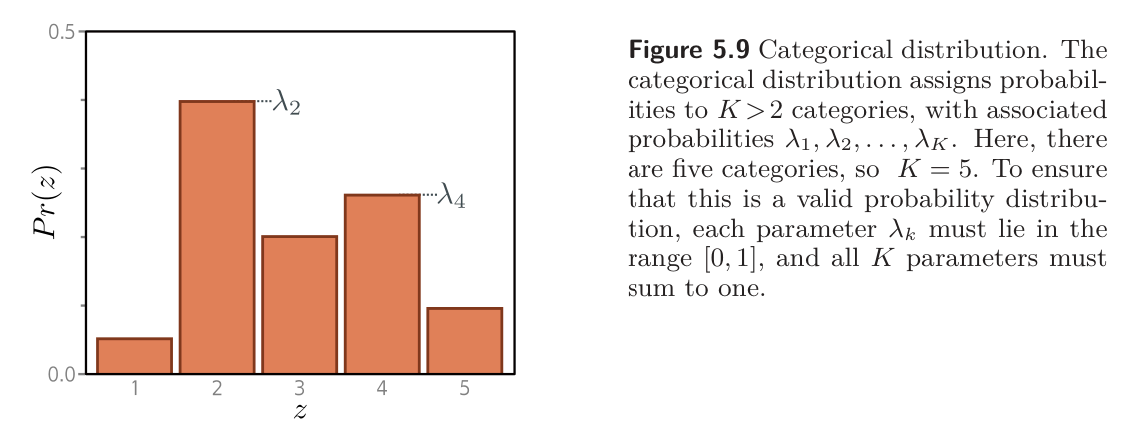
Following the loss function recipe, we first choose a distribution over the prediction space . In this case, we have , so we choose the categorical distribution, which is defined on this domain. This has parameters , which determine the probability of each category:
- Constraints: Each is in the range and they sum to .
Then, we use a network with outputs to compute these parameters from input . Unfortunately, the network outputs do not necessarily obey the aforementioned constraints; thus, we pass them through a function that ensures these constraints are respected. This is usually a softmax function.
The softmax takes an arbitrary vector of length and returns a vector of the same length but where the elements are now in the range and sum to . The -th output of the softmax function is
where the exponential functions ensure positivity, and the sum in the denominator ensures that the numbers sum to one.
The likelihood that input has label is hence:
The loss function is the negative log-likelihood of the training data:
where and denote the -th and -th outputs of the network respectively. This is called multiclass cross-entropy loss.
The transformed model output represents a categorical distribution over possible classes . For a point estimate, we take the most probable category . This corresponds to whichever curve is highest for that value of in the figure below.