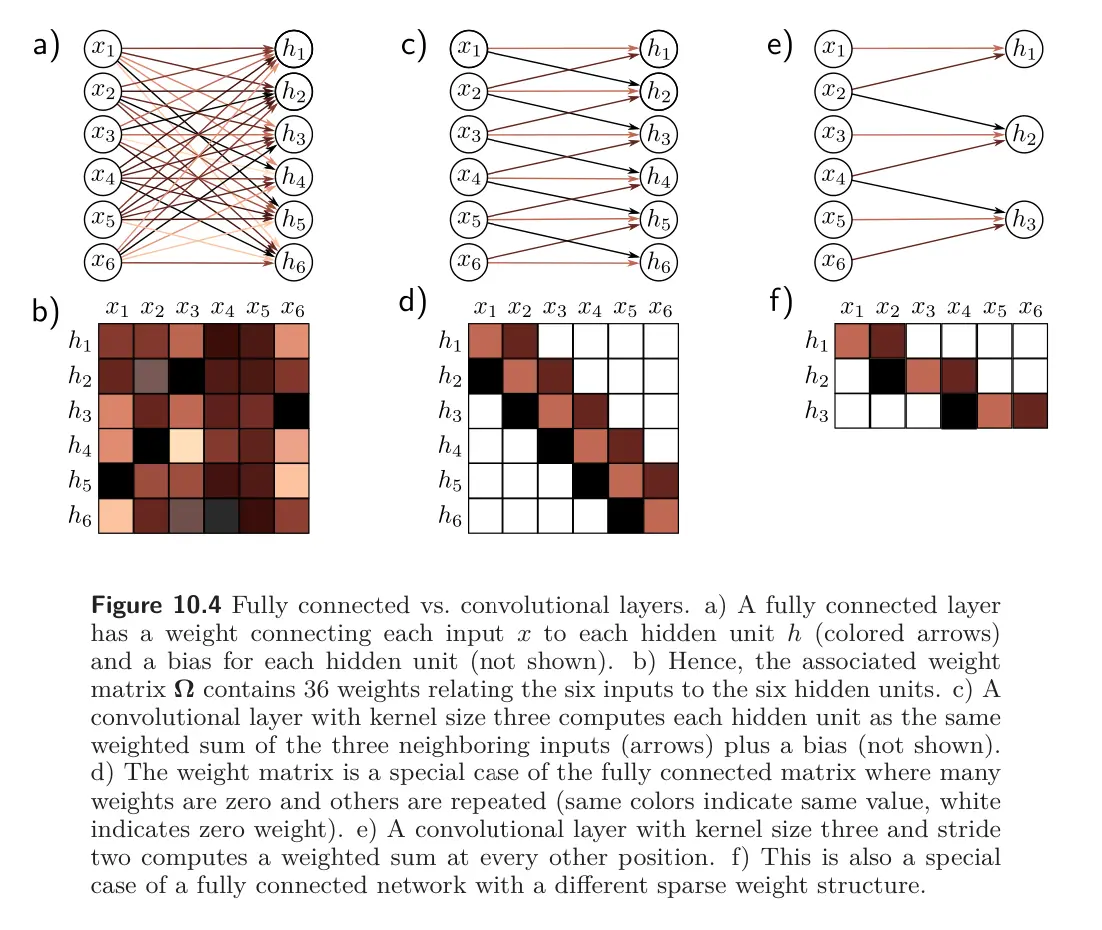
Convolutional layers are network layers that perform the convolution operation. In 1D, a convolution transforms an input vector into an output vector so that each output is a weighted sum of nearby inputs. The same weights are used at every position and are collectively called the convolution layer or filter.
A convolutional layer computes its output by convolving the input, adding a bias , and passing each result through an activation function.
For example, with kernel size 3, stride 1, dilation rate 1, the -th hidden unit would be computed as:
where the bias and the kernel weights are trainable weights, and we treat the input as zero when it is out of the valid range (zero padding).
Convolutional vs. fully-connected layers
We can view this as a special case of a fully connected layer that computes the -th hidden unit as:
If there are inputs and hidden units , this fully connected layer would have weights and biases . The convolutional layer only uses 3 weights and 1 bias. A fully connected weight can reproduce this if most weights are set to zero and others are constrained to be identical.
Convolutions as image filter banks
Each 2D convolution operation performs as an Image Filter. We can stack multiple convolutions on top of each other (channels), such that we lose less information while being much more efficient than a FC layer in terms of number of weights.
The goal is to have each filter (conv kernel) of an Image Filter Bank correspond to a single neural network layer. Each filter corresponds to one output feature map (channel).
The same weights are used many many times in the computation of each layer. This weight sharing means that we can express a transformation on a large image with relatively few parameters; it also means we’ll have to take care in figuring out exactly how to train it.
A convolution layer/filter layer is formally defined with:
- Number of filters
- Size of one filter is (plus 1 bias value for this kernel)
- Stride is the spacing at which we apply the filter to the image
- Input tensor size
- Padding is how many extra pixels (usually with value ) are added around the edges of the input. For an input of size , our new effective input size with padding becomes
This layer will produce an output of size , where
Any bias terms are simply applied with element-wise addition.