Here is the form of a typical convolutional network:
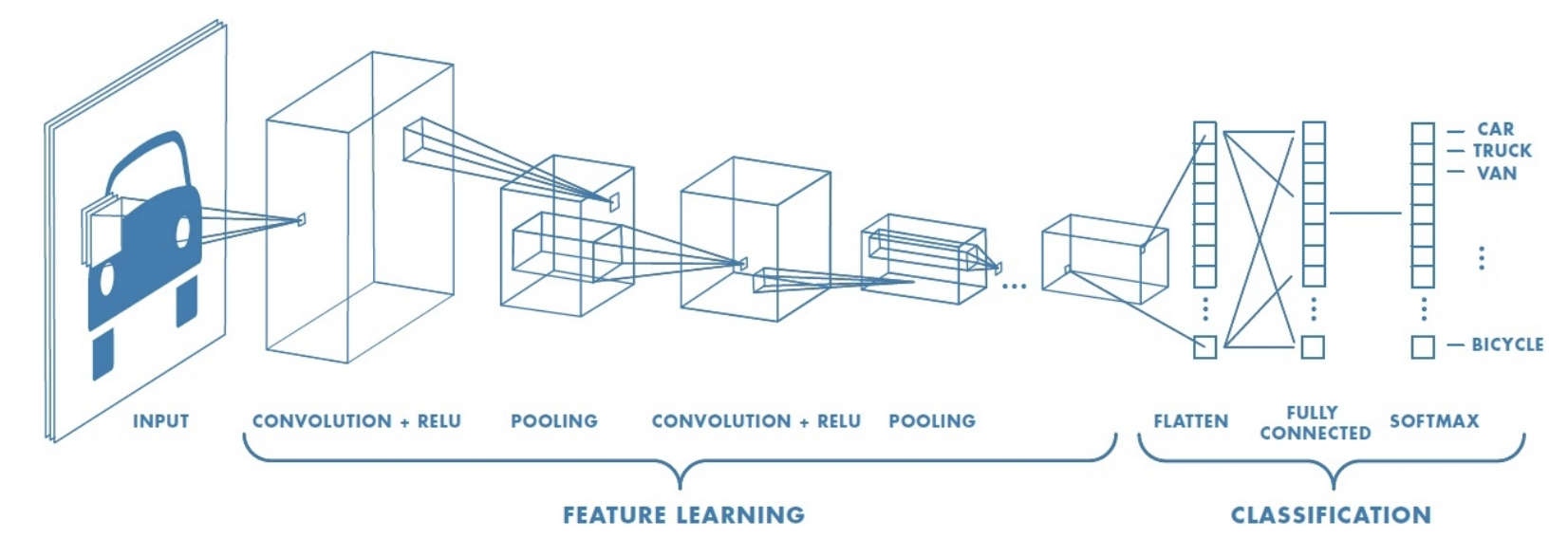
Generally:
- Each Convolutional Layer is accompanied by a ReLU layer
- Usually there are multiple filter/ReLU layers, then a max pooling layer, then some more filter/ReLU layers, then max pooling again
- Once the output is down to a relatively small size, there is typically a last fully-connected layer, leading into an Activation Function such as softmax that produce the final output.
The exact design of these structures is an art—there is not currently any clear theoretical (or even systematic empirical) understanding of how these various design choices affect overall performance of the network.
The critical point for us is that this is all just a big neural network, which takes an input and computes an output. The mapping is a differentiable function of the weights, which means we can adjust the weights to decrease the loss by performing gradient descent, and we can compute the relevant gradients using backpropagation.
Backpropagation Example
Let’s work through a very simple example of how back-propagation can work on a convolutional network. The architecture is shown below.
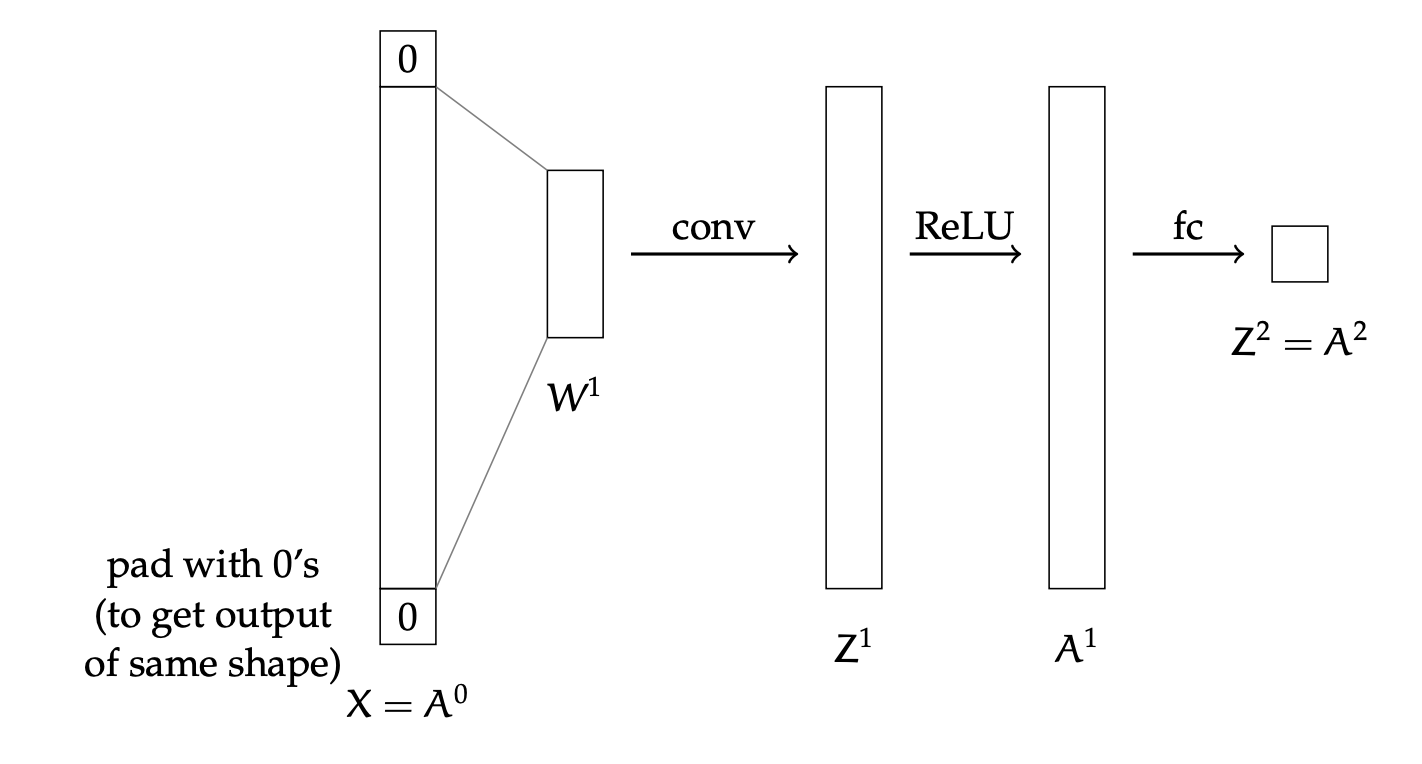
Assume we have a one-dimensional single-channel image, of size and a single filter (where we omit the filter bias) in the first convolutional layer. Then we pass it through a ReLU layer and a fully-connected layer with no additional activation function on the output.
For simplicity, assume is odd. Let the input image , and assume we are using squared loss. Then we can describe the forward pass as follows:
How do we update the weights in filter ?
We have:
- is the matrix such that .
- So, for example, if , which corresponds to column 10 in this matrix, which illustrates the dependence of pixel 10 of the output image on the weights, and if , then the elements in column 10 will be .
- is the diagonal matrix such that:
-
- This is an vector
Multiplying these components together gives us the desired gradient, with dimensions .