In a CNN, if we only apply a single convolution to the input, information will be lost; we are averaging nearby inputs, and the ReLU activation function clips results that are less than zero. Thus, we usually compute several convolutions in parallel. Each convolution produces a new set of hidden variables, termed a feature map or channel.
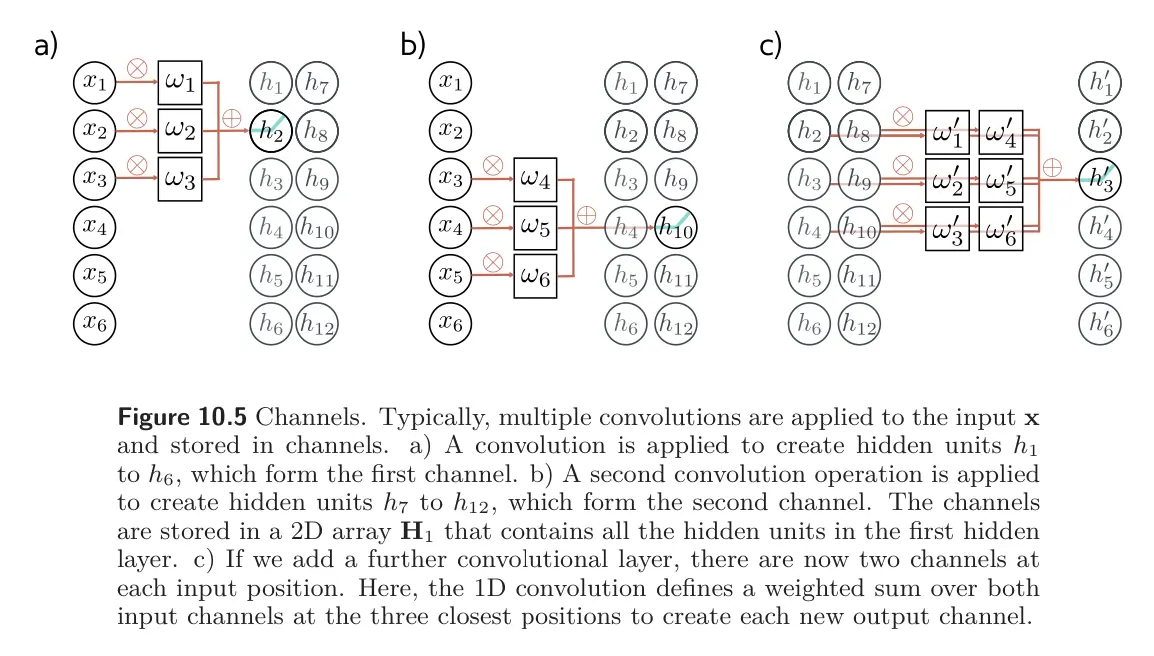
Part (a) and (b) of the figure shows this with two convolution kernels of size 3 and with zero padding.
- The first kernel computes a weighted sum of the nearest three pixels, and passes the results through the activation to produce results to . These comprise the first channel.
- The second kernel computes a different weighted sum of the nearest three pixels, adds a different bias, and passes the results through the activation function to create hidden units to . These comprise the second channel.
In general, the input and the hidden layers all have multiple channels (part (c) of figure). If the incoming layer has channels and we select a kernel size per channel, the hidden units in each output channel are computed as a weighted sum over all channels and kernel entries using a weight matrix and one bias. Hence, if there are channels in the next layer, then we need weights and biases.