Genetic programming is an evolutionary computation technique in which the individuals are programs rather than fixed-length parameter vectors.
GP begins with a population of candidate programs. Each program is evaluated on a target task, and better programs are selected and modified through evolutionary operators. Over generations, the population ends to improve.
Why evolve programs instead of parameters? Some tasks are naturally program-synthesis tasks, such as symbolic regression, classification rules, controller design, signal transforms, and scheduling heuristics. For such problems, choosing the right form of the model is part of the challenge. Thus, GP is powerful when the model structure is unknown or when interpretability matters.
We can also view GP as a heuristic search in the space of programs. Rather than enumerating all possible programs, GP explores the program space adaptively by favoring structures that perform well on the task.
How does GP fit in with other evolutionary computation methods? It’s distinctive because the solution structure itself evolves.
GP can perform well despite massive search spaces because:
- Building-block reuse: useful subtrees can be discovered and reused
- Semantic redundancy: many syntactically different programs share similar semantics
- Selection amplification: even tiny advantages can become dominant over generations
- Compositional search: crossover can assemble larger structures from smaller ones
- Neutrality: Some genotype changes do not immediately harm fitness, allowing exploration
GP might struggle when:
- Bad function set: the function set is properly chosen
- Extreme noise: fitness ranking becomes unreliable
- Reward is too sparse
- Bloat: Size grows faster than useful structure
- Credit assignment difficulty: useful components help only in the larger context, or are too hard to discover compositionally
Components
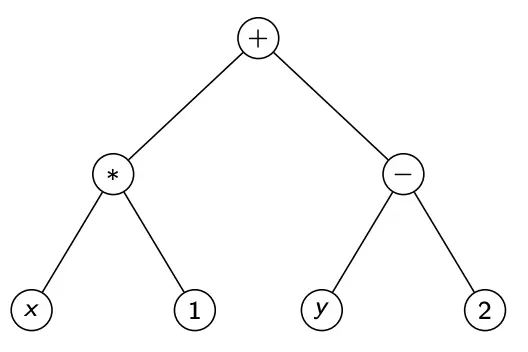
GP manipulates Syntax Tree GP Programs.
Initialization
The initial population determines what the evolution starts with. Good initialization should provide structural diversity, varying tree depths, varied semantics, and manageable initial size. The initialization population affects the amount of reusable building blocks, the initial fitness distribution, and the likely paths available to crossover.
- Too many shallow trees may limit expressiveness: small trees cannot represent complex relationships, so search starts in a restricted part of the search space
- Too many deep trees may cause early bloat: large trees contain unnecessary substructures. Generally, evolution will cause trees to grow even if they are large, so we will have very slow evaluation and poor generalization.
Below we cover some initialization methods.
In the Full method, internal levels are filled with functions, and terminals only appear at maximum depth. This provides regular structure and controlled depth, but has limited shape diversity.
In the Grow method, nodes may become terminals before max depth, such that tree shapes become irregular. This has the advantage of giving us diverse shapes and structural variety. However, many trees may be very small.
The classical GP initialization strategy is Ramped Half-and-Half. We choose several max depth values. For each depth, generate some trees by Full, and generate some with Grow.
Fitness Evaluation
Unlike vector optimization, GP evaluates program behavior. For each individual we execute the program, observe its outputs on problem instances, and compute a task-specific performance measure. For example: regression error, classification accuracy, control survival time, energy consumption.
Selection
Selection determines which programs are more likely to reproduce. If selection pressure is too weak, progress is slow, and poor programs persist. If it is too strong, diversity collapses, and premature convergence becomes likely.
Tournament selection: Sample individuals at random, choose the best among them, repeat to select parents. This is simple, efficient, and easy to control pressure through .
Elitism: Copy small number of best individuals directly into the next generation. This guarantees best-so-far solution is never lost, and so fitness will improve monotonically. However, too much elitism reduces diversity and might prematurely converge. Thus, a small number (1-5%) suffices.
Crossover
Subtree crossover is the main GP operator. The procedure is as follows:
- Choose one parent subtree from parent 1
- Choose one parent subtree from parent 2
- Swap them
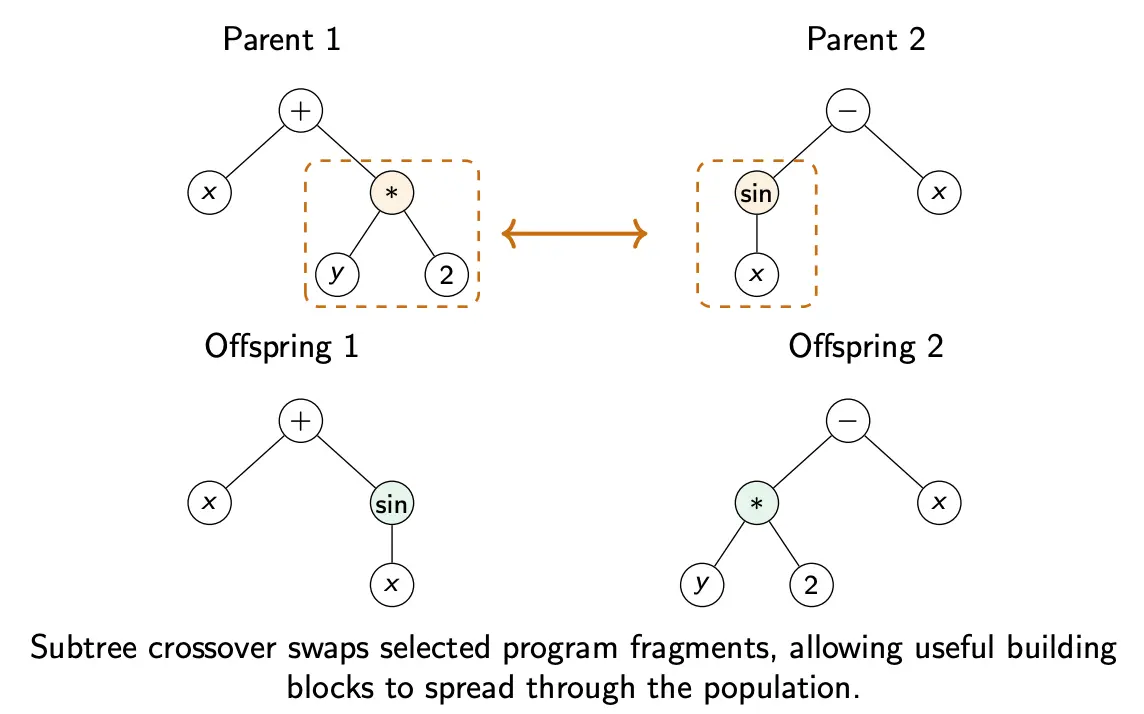
This essentially banks on the assumption that some program fragments are useful building blocks.
Mutation
In subtree mutation, we:
- Select a random node
- Delete the subtree rooted there
- Replace it with a newly generated random subtree
This introduces structural novelty that crossover alone may never generate.
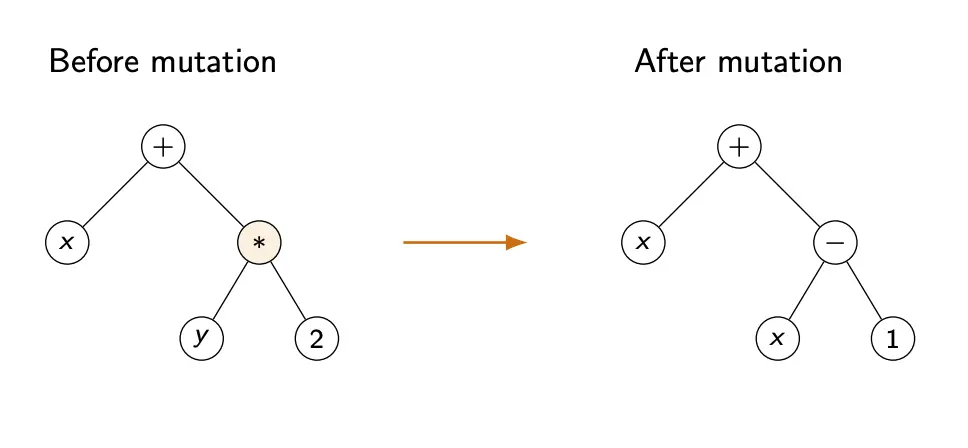
Some other mutation options:
- Point mutation: change a node label while preserving arity
- Hoist mutation: Replace the whole tree by one of its internal subtrees
- Shrink mutation: Replace a subtree with a simpler subtree or terminal.
Operator Probabilities
Like we did for GA, at each reproduction step, we choose how to generate a new individual based on some probabilities:
- Apply crossover with probability
- Apply mutation with probability
- Apply elitism/copy with probability
Crossover is the most dominant because it combines useful subtrees, driving most of the search.
Implementation
Sample implementation code




Bloat
GP trees often grow larger and larger over generations, even when fitness barely improves. This phenomenon is called bloat. This is bad also because of slower evaluation and harder interpretation. One possible reason is structural bias: there are more large trees than small ones, and variations tend to increase tree size.
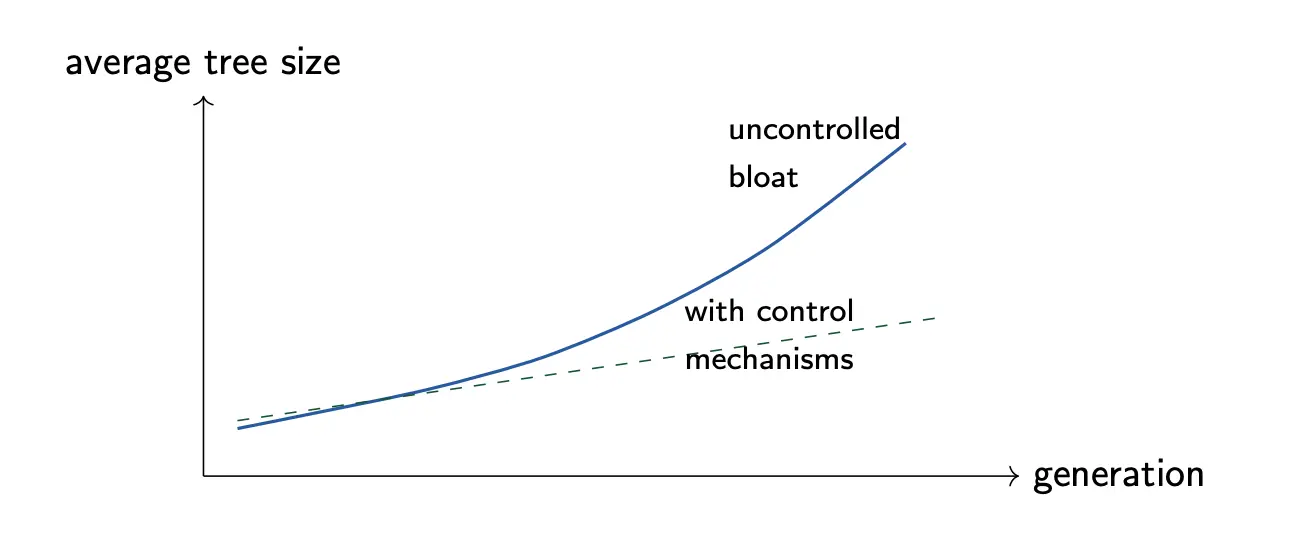
Another reason for bloat might be because of introns, which is neutral code that has little or no effect on the output. For example, is redundant. These may survive because they make crossover less likely to damage critical subtrees, acting as protective padding. However, changing them also often does not change fitness, so trees grow without penalty.
To control bloat, we can penalize complexity through parsimony pressure. Specifically, the modified fitness becomes:
for minimization, or with a minus for maximization. Parsimony pressure encourages smaller programs, simpler explanations, and faster evaluation.
Another simple anti-bloat method is to impose max depth, max node count, and restricted subtree sizes during variation. But this can be sensitive: too lose and we will bloat, too strict and we will not have enough expressiveness.
Variations
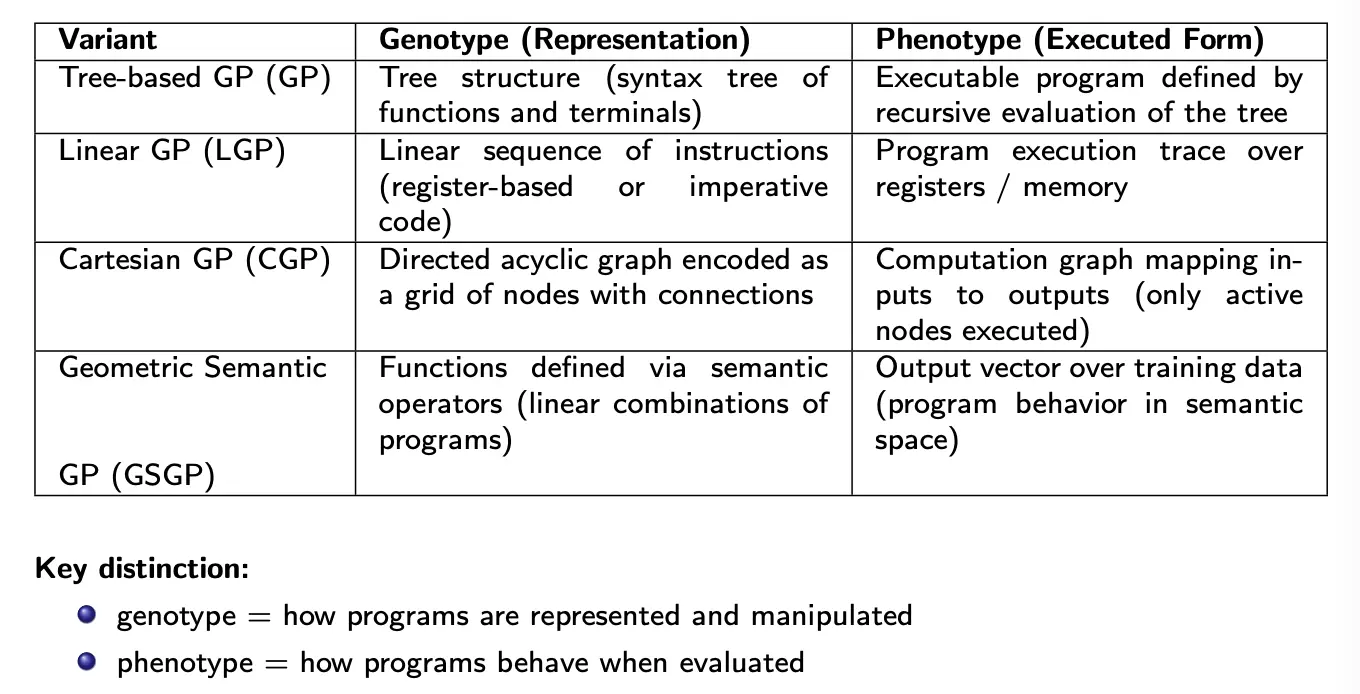
In Linear Genetic Programming, a program is a sequence of instructions executed step by step (similar to a simple program or assembly code). The representation is a list of instructions operating on registers, where each instruction updates a register value. This is natural for imperative programming.
In Cartesian Genetic Programming, programs are represented as directed acyclic graphs laid out on a grid. This supports node reuse, and so the graph structure can be more compact than trees.
In Grammar-Guided Genetic Programming, we restrict the search space using production rules. For example:
This means we can embedded domain knowledge, and easily enforce syntactic correctness.
Geometric Semantic Genetic Programming tries to act more directly on behavior instead of acting on syntax. This is basically the idea of syntactic vs. semantic idea we saw in Search Space.
In Multiobjective Genetic Programming, we optimize more than one criterion.