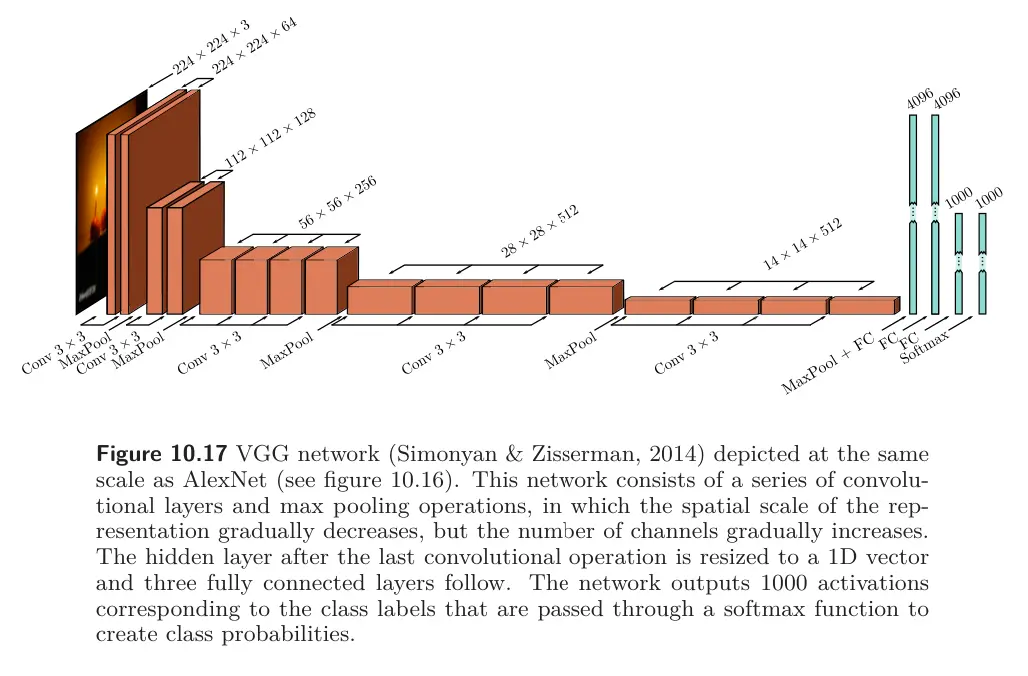
VGG (named after Visual Geometry Group at Oxford) is an image classification network targeted for the ImageNet task, achieving a better performance compared to AlexNet. Similar to AlexNet, it was composed of a series of interspersed convolutional and max pooling layers, where the spatial size of the representation gradually decreases, but the number of channels increase. VGG was also trained using data augmentation, weight decay, and dropout.
Although there were minor differences in the training regime, the most important change between AlexNet and VGG was the depth of the network. The latter used 19 hidden layers and 144 million parameters (vs. 8 hidden layers and 60 million parameters). There was a general trend for several years for performance on ImageNet improving as the depth of the networks increased, providing evidence that depth is important in neural networks.