The goal of semantic segmentation is to assign a label to each pixel according to the object that it belongs to, or no label if that pixel doesn’t correspond to anything in the training set.
Below is the design of a basic semantic segmentation network. The input is a RGB image, and the output is a array that contains the probability of each of 21 possible classes at each position.
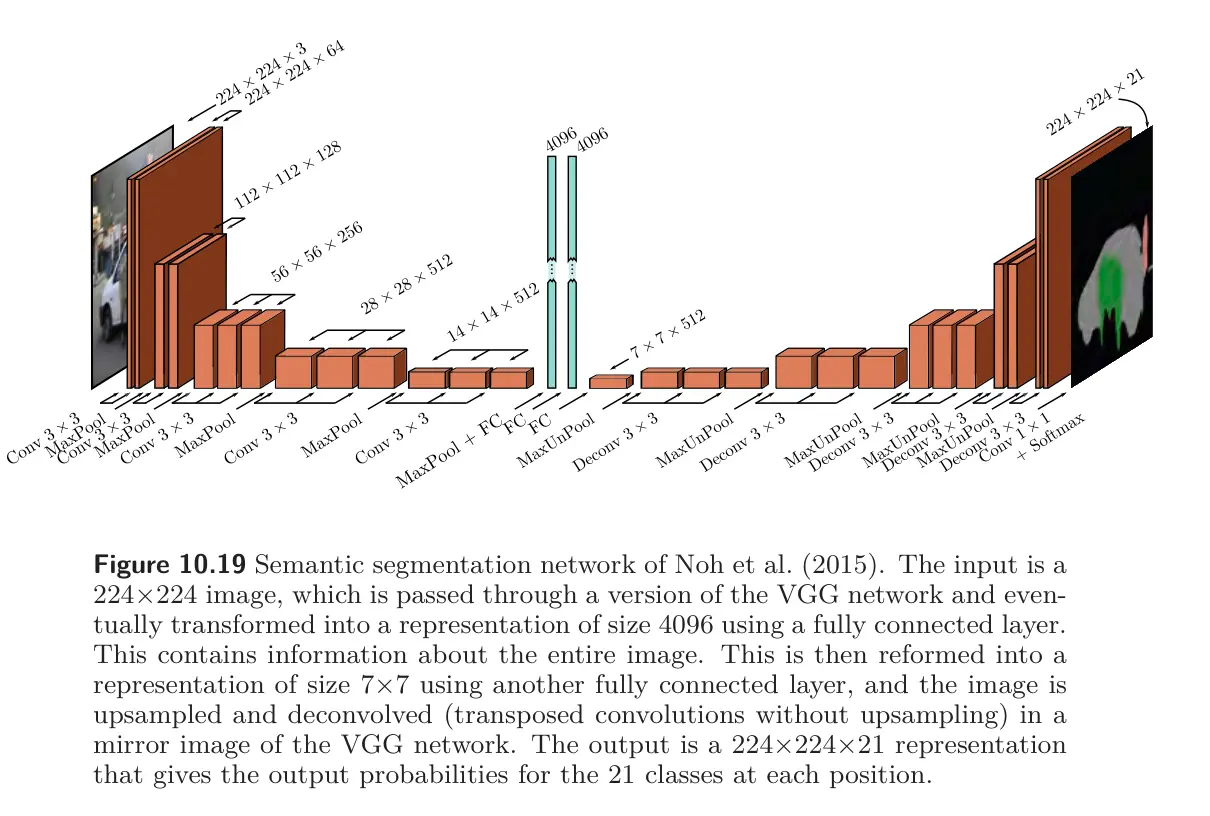
The first part of the network is a smaller version of VGG that contains 13 rather than 16 convolutional layers and downsizes the representation to . There is then one more max pooling operation, followed by two fully connected layers that map to two 1D representations of size 4096. These layers do not represent spatial position but instead combine information from across the whole image.
Then, another FC layer reconstitutes the representation into spatial positions and 512 channels. This is followed by a series of max unpooling layers and deconvolution layers. These are transposed convolutions but in 2D and without the upsampling. Finally, a 1x1 convolution creates 21 channels representing the possible classes, and a softmax operation at each spatial position maps the activations to class probabilities.
The downsampling side of the network is sometimes called an encoder, and the upsampling side a decoder, so networks of this type are sometimes called encoder-decoder networks or hourglass networks.
The final segmentation is generated using a heuristic method that greedily searches for the classes that is most represented and infers its region, taking into account the probabilities but also encouraging connectedness. The next most-represented classes is added where it dominates at the remaining unlabeled pixels. This continues until there is insufficient evidence to add more.
