Regression problems can be expressed in terms of error minimization, such as Ordinary Least Squares. We can also view it as a probabilistic maximum likelihood estimation problem.
The goal in the regression problem is to make predictions for the target variable given some new value of the input variable . This is done by using a set of training data comprising input values, and their corresponding values .
We can express our uncertainty over the value of the target variable using a probability distribution. Given a value of , the corresponding has a Gaussian distribution with a variance , and a mean equal to , such that:
Thus, we have:
This is shown in the diagram below. Instead of predicting a point with the function , we’re predicting a distribution where is the mean.
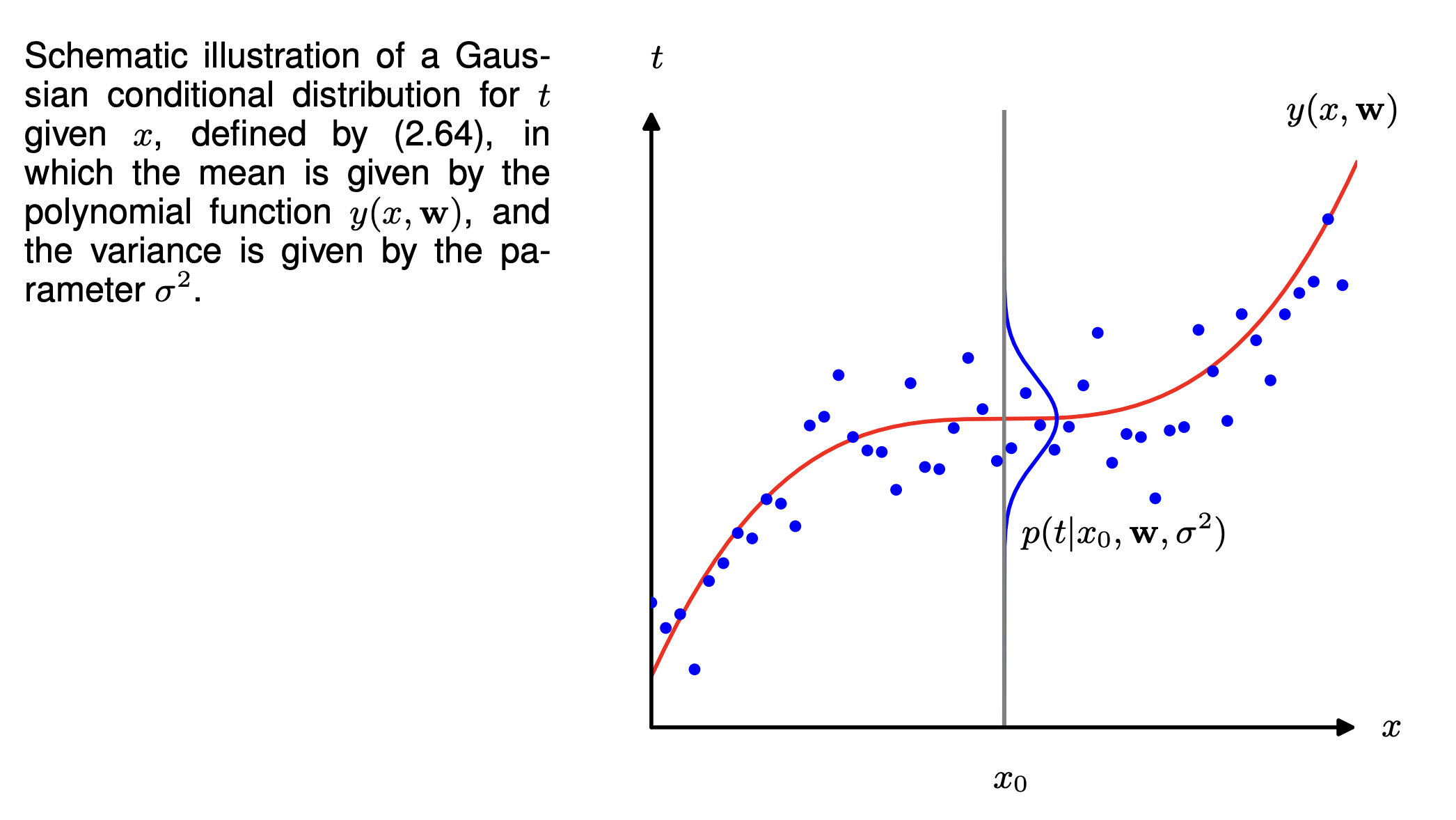
We can then use our training data and labels to determine the values of the unknown parameters and by maximum likelihood. If the data is drawn independently the distribution, the likelihood function is:
Like our Gaussian MLE example, we can maximize the logarithm of the likelihood function:
Now, we would want to maximize the above expression with respect to :
- We can ignore the 2nd and 3rd term because they don’t depend on .
- Scaling the log likelihood by a positive constant coefficient doesn’t change the location of the maximum with respect to , so we can replace with just .
- Minimizing the negative log likelihood is equivalent to maximizing the log likelihood.
Thus, our MLE is equivalent, as far as is concerned, to minimizing the sum-of-squares error defined by:
(The square is added to guarantee positive values).
Thus, we’ve shown how the sum-of-squares error function arises as a consequence of maximizing the likelihood under the assumption of a Gaussian noise distribution.
We can also use maximum likelihood to determine . Maximizing the logarithm of the likelihood function with respect to gives:
We can first determine the parameter vector governing the mean, and subsequently use this to find the variance as was the case for the Gaussian MLE.
Since we have determined the parameters and , we can now make predictions for new values of . Our model is probabilistic, so these are expressed in terms of the predictive distribution that gives the probability distribution over , rather than simply a point estimate. These distributions can be obtained by substituting the maximum likelihood parameters into our original distribution expression to get: