This shows the derivation of the Kalman Filter in one dimension; the goal is intuition and clarity.
Unlike the alpha-beta-gamma filter, the Kalman filter treats measurements, the current state estimate, and the predicted state estimate as normally distributed random variables. Each random variable is described by its mean and variance.
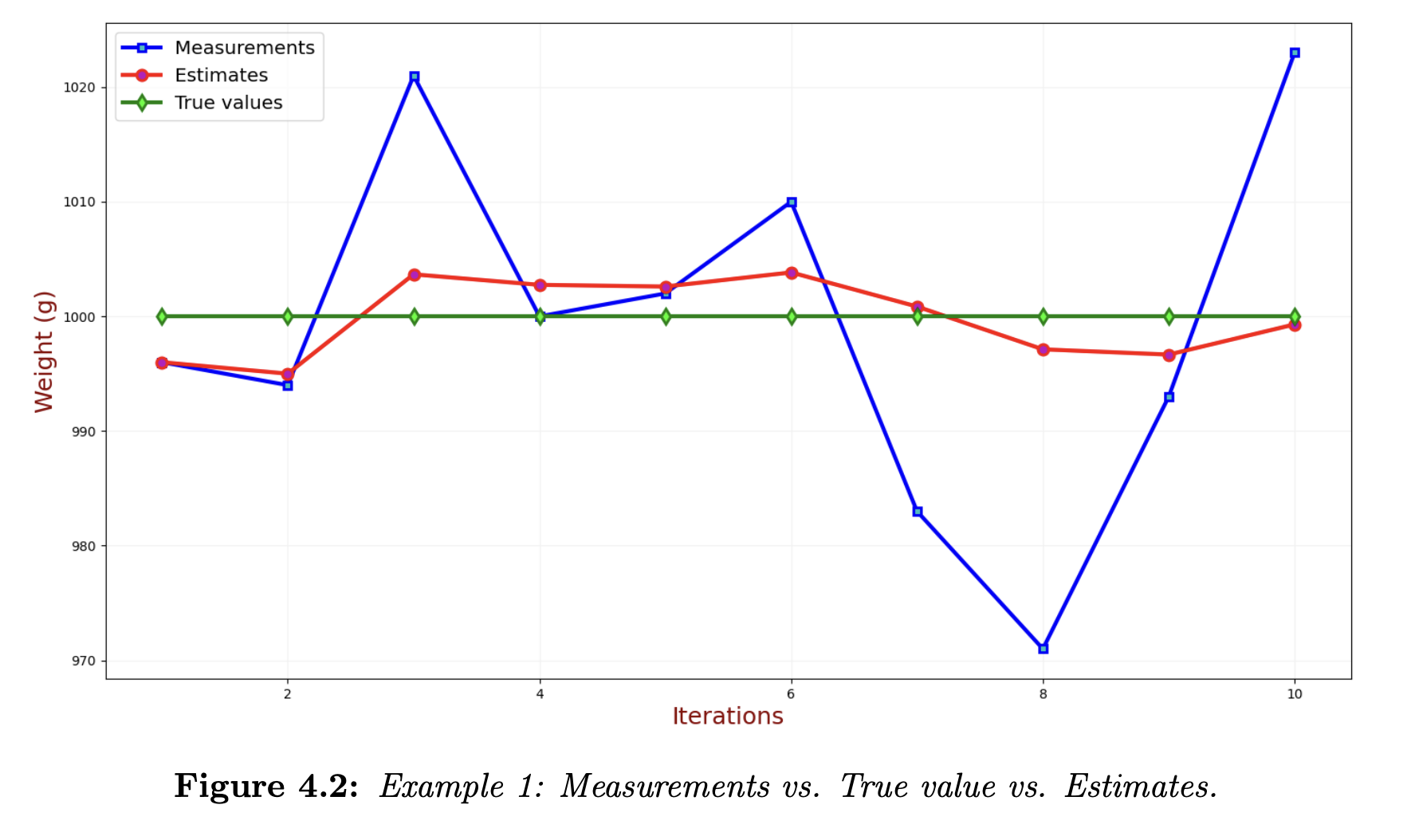
Recall the simple static state estimation example with weighing gold. We made multiple measurements and computed the estimate by averaging. We got the following results:
Estimate as a random variable
The difference between the estimates (red line) and the true values (green line) is the estimate error. The estimate error becomes lower as we make additional measurements, converging to zero, while the estimated value converges toward the true value. We don’t know the estimate error but we can estimate the state uncertainty.
The state estimate variance is denoted by . This is also called the estimate uncertainty.
Measurement as a random variable
The measurement errors are the differences between the measurements (blue samples) and true values (green line). Since measurement errors are random, we can describe them by variance, . The standard deviation of the measurement is the measurement uncertainty.
The measurement variance is denoted by . This is also sometimes called the measurement error.
The variance of the measurement errors could be provided by the measurement equipment vendor, calculated, or derived empirically by a calibration procedure.
Let’s look at the weight measurements probability density function (PDF). The following plot shows 10 measurements of the gold bar weight.
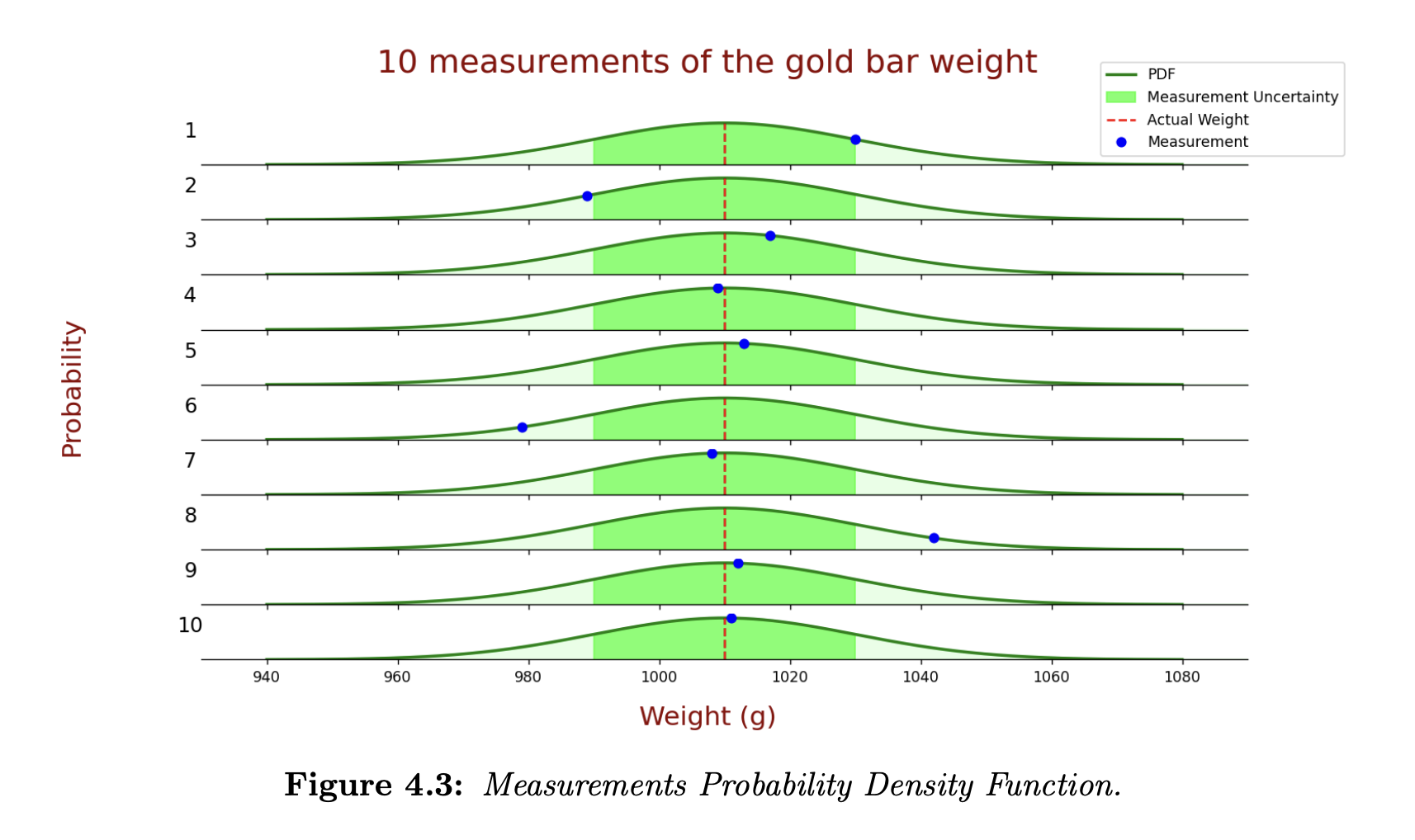
- The blue circles describe the measurements.
- The true values are at the red dashed line.
- The green line describes the probability density function of the measurement.
- The bold green area is the standard deviation of the measurement – there is a probability of 68.26% that the measurement value lies within this area. 7 out of 10 the measurements are within the area.
State Prediction
In our simple static example of gold bar measurement, the weight of the gold bar is constant:
In the second example of constant velocity aircraft tracking, we extrapolated the current state (target position and velocity) to the next state using motion equations:
Thus, we can see that the dynamic model equation depends on the system. Since the Kalman Filter treats the estimate as a random variable, we must extrapolate the estimate variance, , to the next state as well.
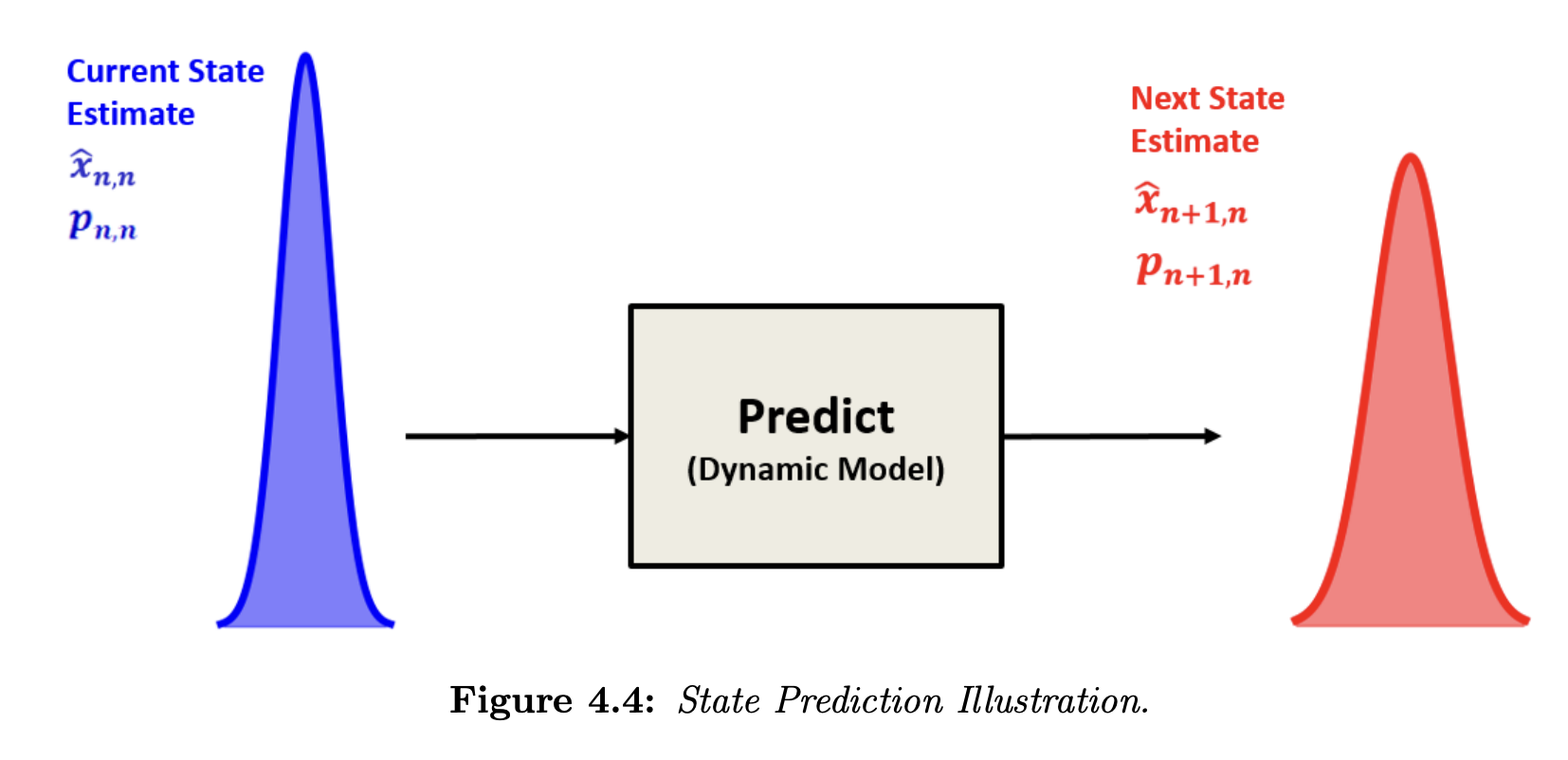
In the first static example, the dynamic model of the system is constant; thus, the estimate uncertainty extrapolation would be:
where is the estimate variance of the gold weight.
In the second constant velocity example, the estimate uncertainty extrapolation would be:
where is the position estimate variance and is the velocity estimate variance.
Why is it ? Note that for a normally distributed random variable with variance , is normally distributed with variance . Therefore, the time term in the uncertainty extrapolation equation is squared.
State Update
To estimate the current state of the system, we combine two random variables:
- The prior state estimate (current state estimate predicted at the previous state)
- The measurement
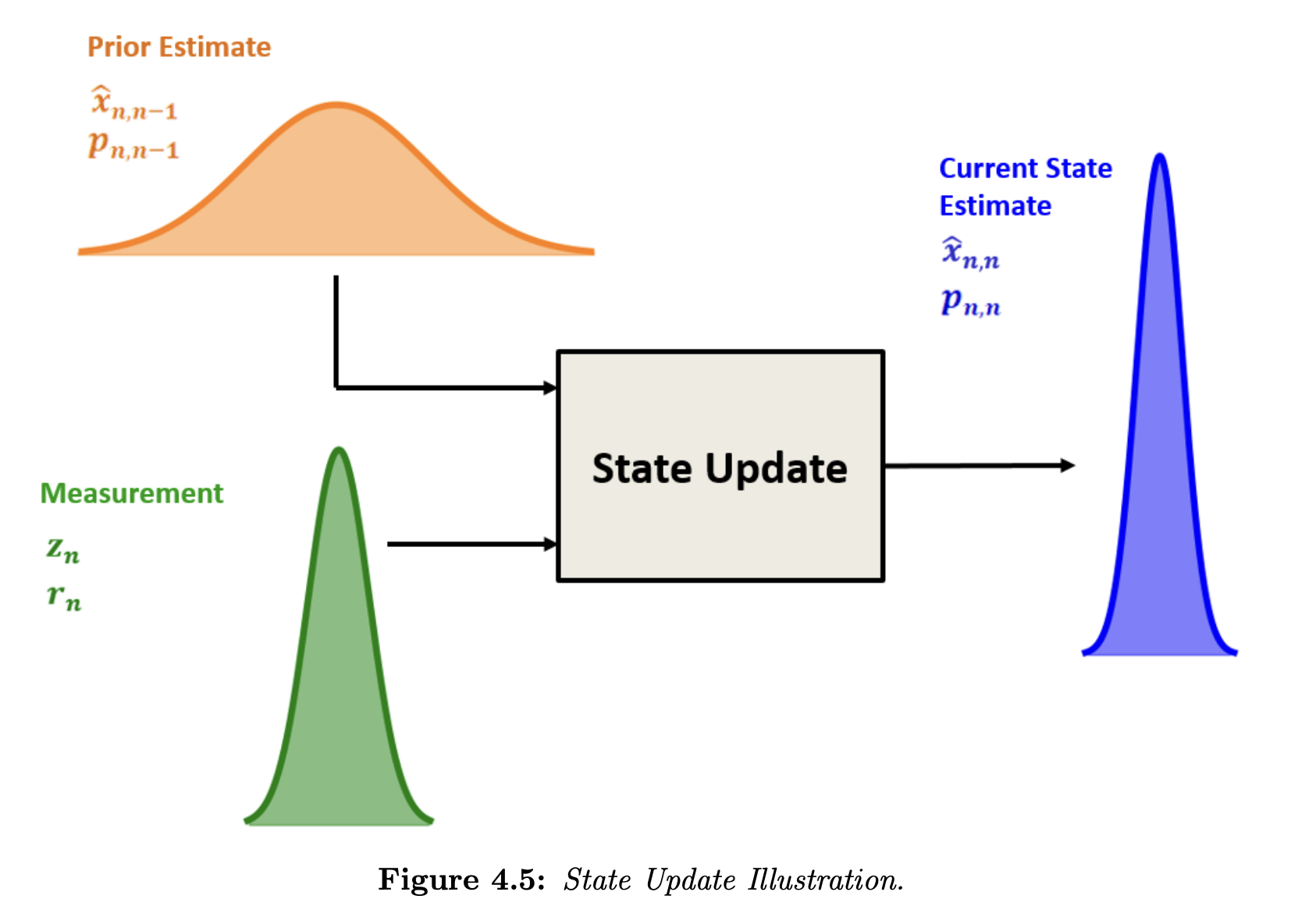
The Kalman filter is an optimal filter. It combines the prior state estimate with the measurement in a way that minimizes the uncertainty of the current state estimate.
The current state estimate is a weighted mean of the measurement and the prior state estimate:
where are weights of the measurement and the prior state estimate . Alternatively, we can write it as:
The relationship between the variances is given as:
where:
- is the variance of the optimal combined estimate
- is the variance of the prior estimate
- is the variance of the measurement
To find the that minimizes , we differentiate with respect to and set the result to zero:
Solving:
Substituting into our current state estimation equation :
State Update Equation
Recall that the innovation is . The weight of the innovation is the Kalman Gain:
The Kalman Gain is a number between and :
Finally, we need to find the variance of the current state estimate. We’ve seen that the relation between variances is given by:
where
Then, we can re-write the relation between variances as:
This is the Covariance Update Equation:
Covariance Update Equation
It is clear from the equation that the estimate uncertainty is constantly decreasing with each filter iteration, since .
- When the measurement uncertainty is high, the denominator of is large, resulting in a low Kalman Gain. Therefore, the convergence of the estimate uncertainty would be slow.
- On the other hand, the Kalman gain is high when the measurement uncertainty is low. Therefore, the estimate uncertainty would quickly converge toward zero.
Putting it all together
We combine the above pieces into a single algorithm.
The filter inputs are:
- Initialization: The initialization is only performed once. It provides two parameters:
- Initial system state,
- Initial state variance,
- Measurement: The measurement is performed for every filter cycle, and it provides two parameters:
- Measured system state,
- Measurement variance,
The filter inputs are:
- System state estimate,
- Estimate variance,
The following summarizes the five Kalman Filter equations.
State Update
State Predict
State
Constant system dynamics:
Constant velocity:
Covariance
Constant system dynamics:
Constant velocity:
Note that the equations above don’t include the process noise. Process noise is added here.
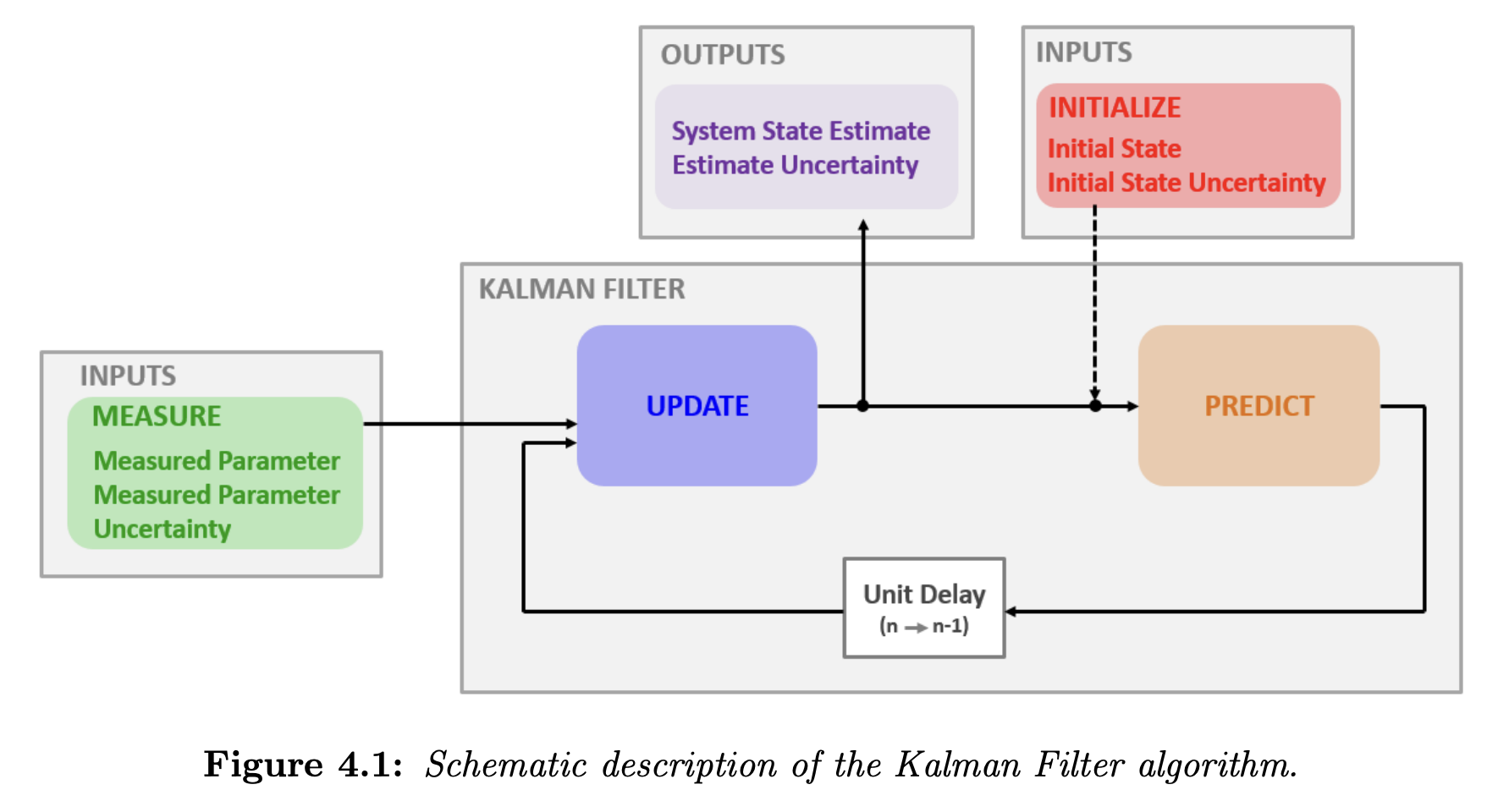
Block Diagram
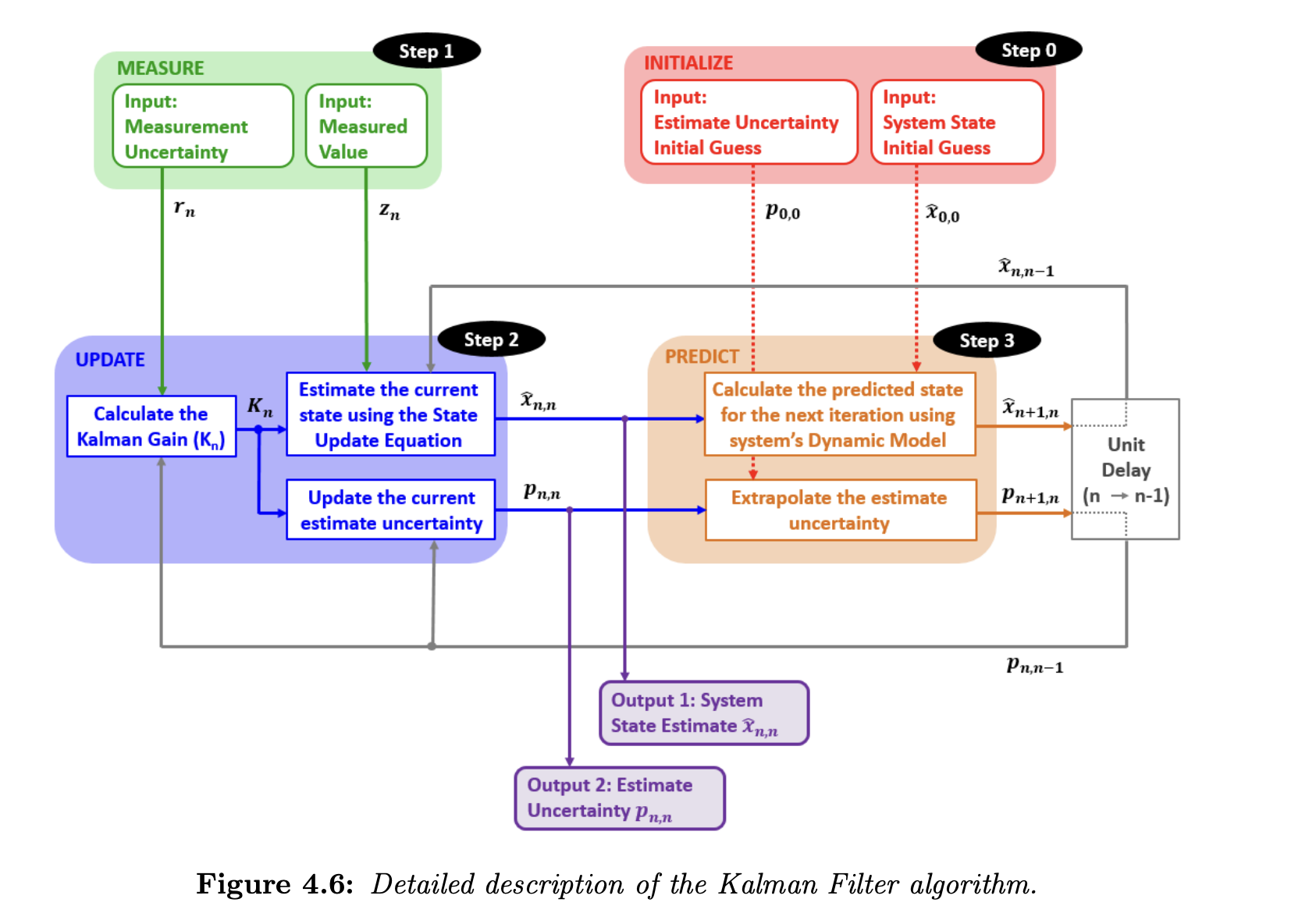
The general steps are described below.
Initialize. The initialization is performed only once, and it provides two parameters:
- Initial system state,
- Initial state variance,
Measure. The measurement provides the following parameters:
- Measured system state,
- Measured variance,
State update. The state update process is responsible for the state estimation of the current state of the system:
- Measured value,
- Measurement variance,
- A prior predicted system state estimate,
- A prior predicted system state estimate variance,
Based on the inputs, the state update process calculates the Kalman Gain and provides two outputs:
- Current system state estimate,
- Current state estimate variance,
Predict. The prediction process extrapolates the current system state estimate and its variance to the next system state based on the dynamic model of the system. At the first filter iteration, the initialization is treated as the prior state estimate and variance. The prediction outputs are used as the prior (predicted) state estimate and variance on the following filter iterations.
Example: Estimating Building Height
In this example, we would like to estimate the height of a building using an imprecise altimeter.
We know that the building height doesn’t change over time (at least during the short measurement process).
Information given:
- The true height of the building is 50 meters.
- The altimeter measurement error (standard deviation) is 5 meters.
- The 10 measurements are: 49.03m, 48.44m, 55.21m, 49.98m, 50.6m, 52.61m, 45.87m, 42.64m, 48.26m, 55.84m.
Iteration 0
Initialization: The estimated height of the building based on the human eye we start from is:
A human estimation error is about . So, the variance is , so we have:
Prediction: Now, we predict the next state based on the initialization values. Since our system model is constant (the building doesn’t change height), we just have
The predicted variance also doesn’t change:
Iteration 1
Measurement: The first measurement is . Since the standard deviation of the altimeter measurement is 5, the variance is . Thus, the measurement uncertainty is .
Update: We first calculate the Kalman Gain with:
Estimating the current state:
Updating the current estimate covariance:
Predict: Since the dynamic model of our system is constant, i.e., the building doesn’t change its height, we have
The extrapolated estimate variance also doesn’t change:
Iteration 2
After a unit time delay, the predicted estimate from the previous iteration becomes the prior estimate in the current iteration:
The extrapolated estimate becomes the prior estimate variance:
Measure: The second measurement is . The measurement variance is .
Update: The Kalman Gain calculation is
Estimating the current state:
Updating the current estimate variance:
Predict: Since the dynamic model of our system is constant, i.e., the building doesn’t change its height, we have
The extrapolated estimate variance also doesn’t change:
Results & Analysis
First of all, we want to ensure Kalman Filter convergence. The Kalman Gain should gradually decrease until it reaches a steady state. When Kalman Gain is low, the weight of the noisy measurements is also low. The following plot describes the Kalman Gain for the first one hundred iterations of the Kalman Filter.
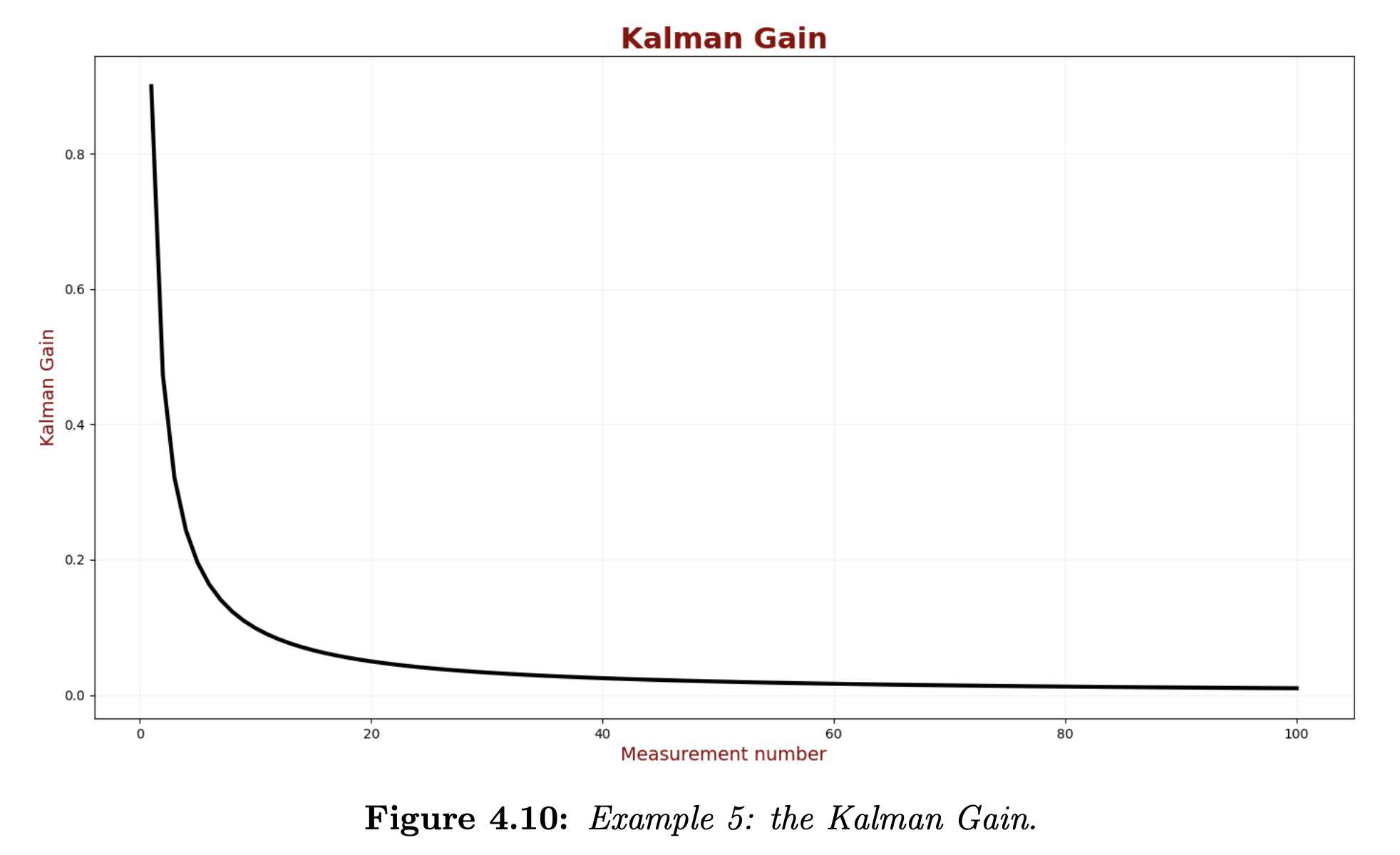
We can see a significant reduction in the Kalman Gain in the first 10 iterations; a steady state is hit after about 50 iterations.
The estimation error is the difference between the true values (the green line) and the KF estimates (the red line). We can see that the estimation errors of our KF decrease in the filter convergence region.
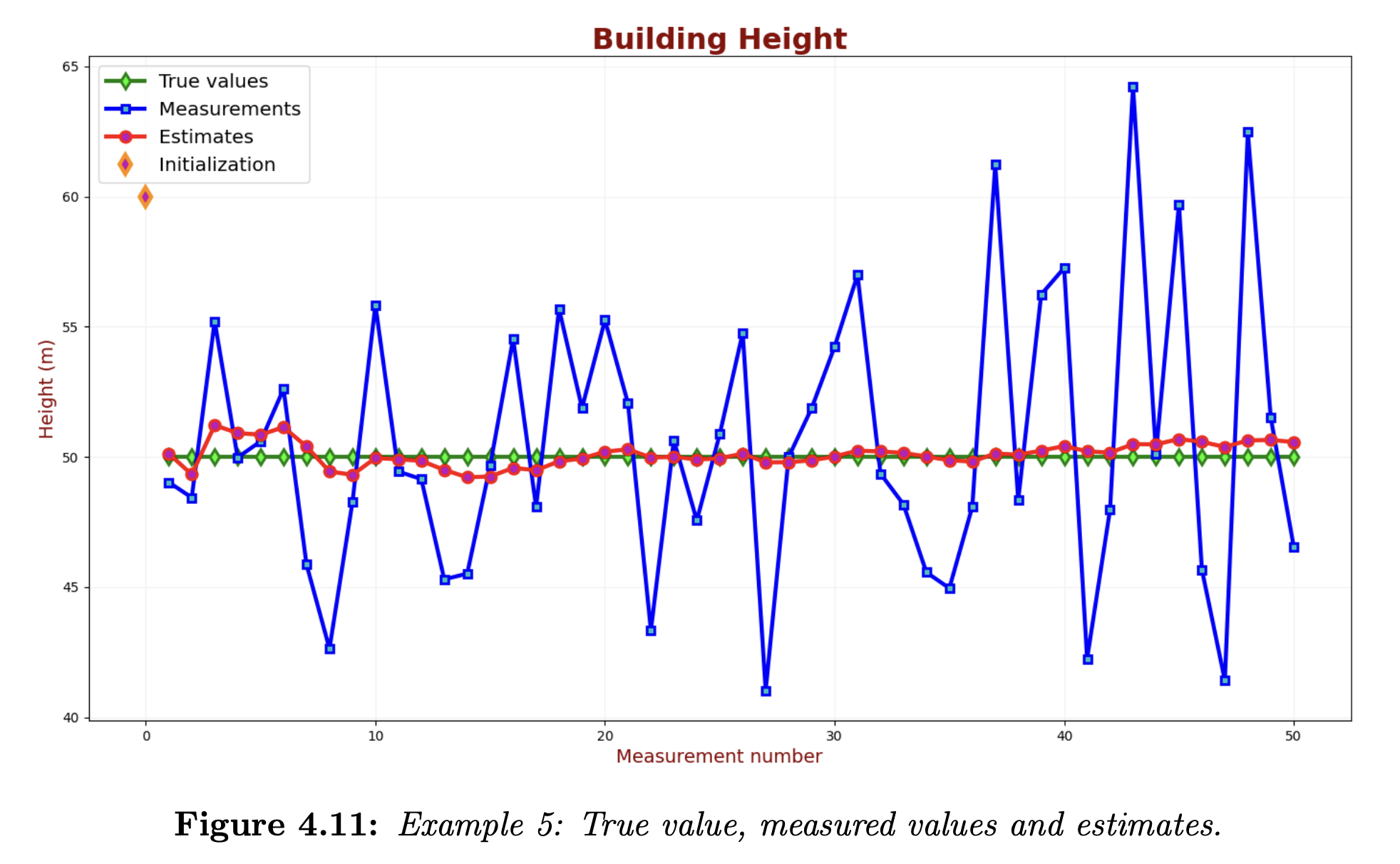
The typical accuracy criteria are maximum error, mean error, and root mean square error.
Another important parameter is estimation uncertainty. We want the Kalman Filter (KF) estimates to be precise; therefore, we are interested in low estimation uncertainty.
Assume that for a building height measurement application, there is a requirement for 95% confidence. The following chart shows the KF estimates and the true values with 95% confidence intervals.
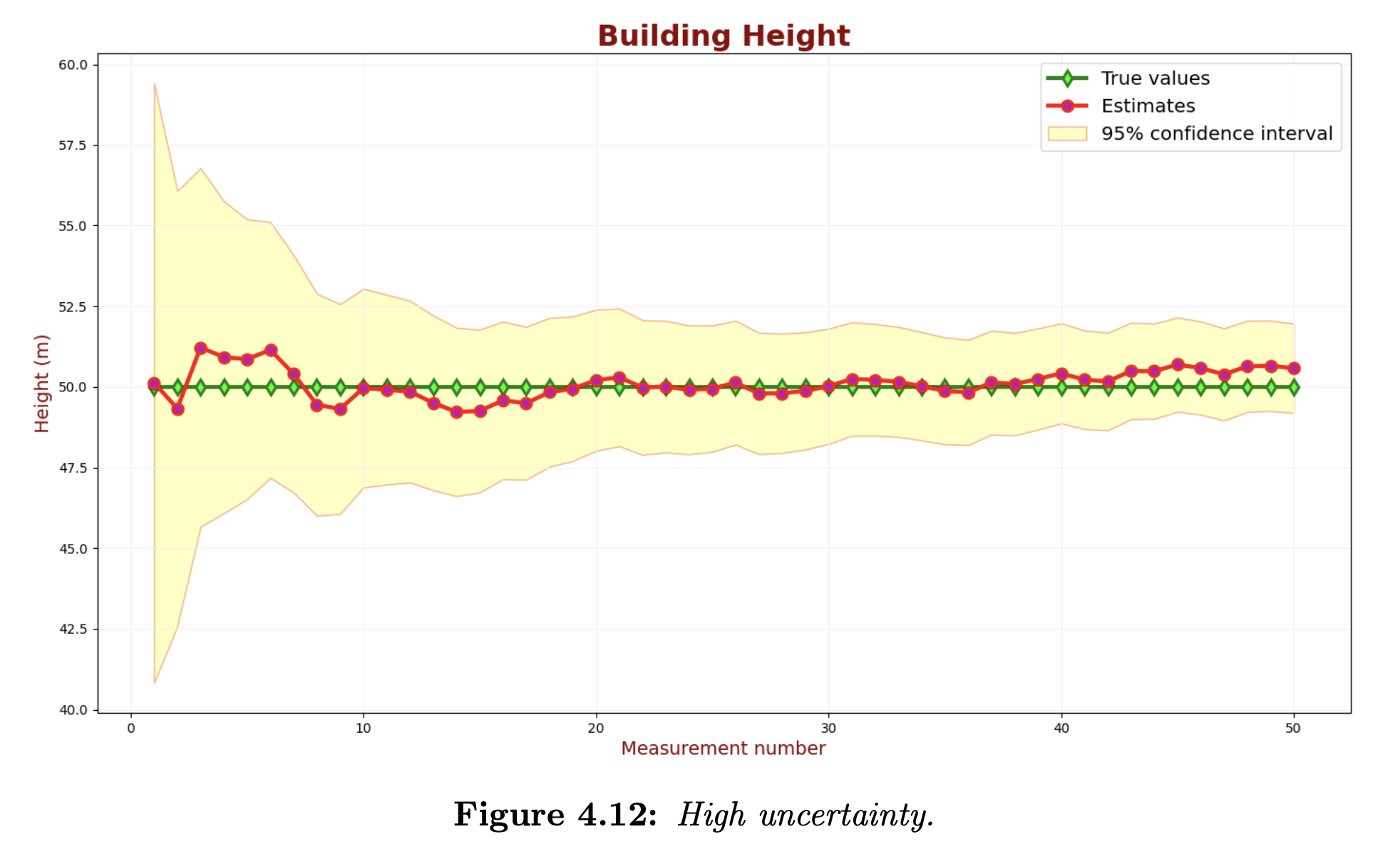
In the above chart, the confidence intervals are added to the estimates (the red line). 95% of the green samples should be within the 95% confidence region.
We can see that the uncertainty is too high. Let us decrease the measurement uncertainty. The following chart describes the KF output for a low measurement uncertainty parameter.
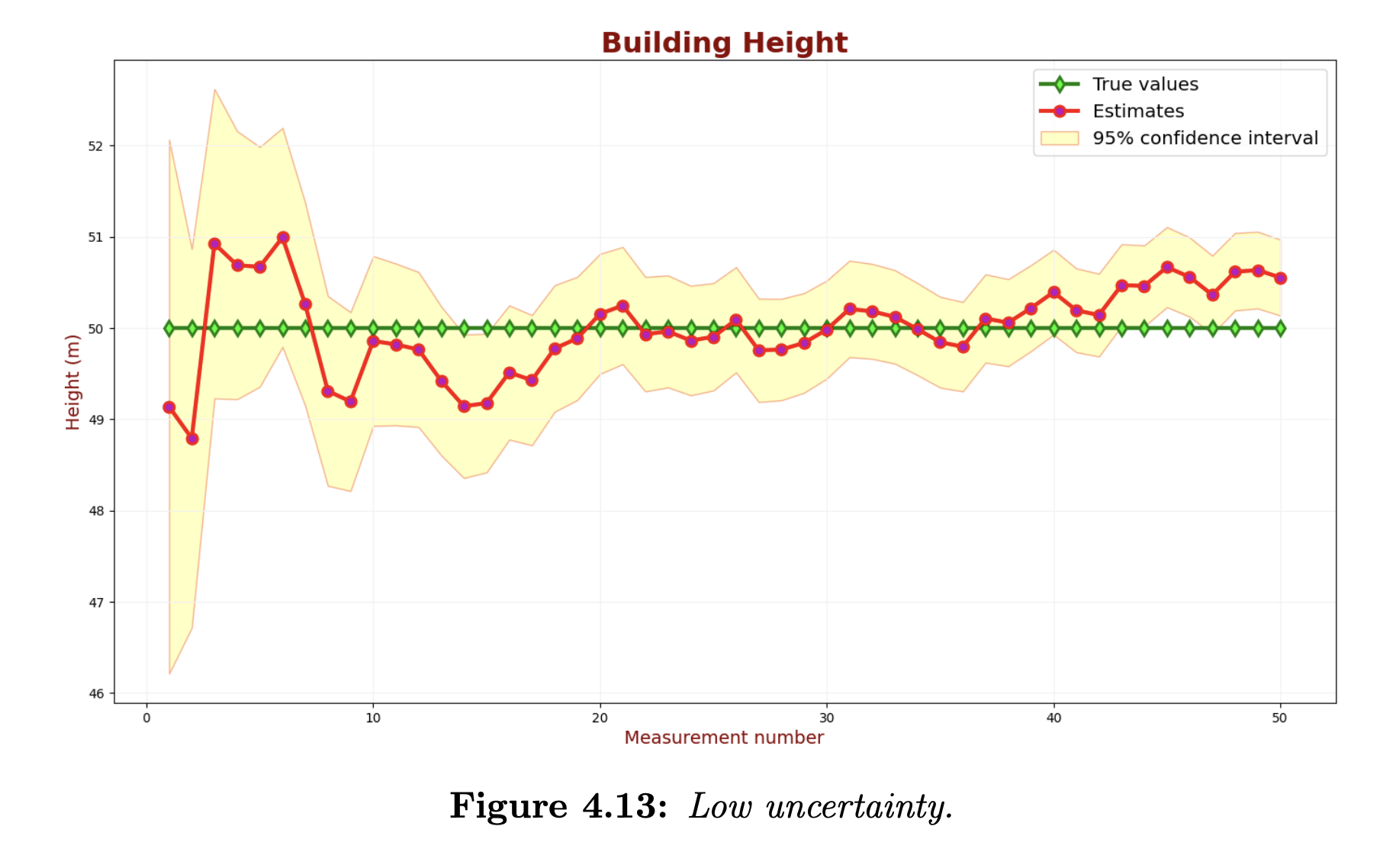
Although we’ve decreased the uncertainty of the estimates, many green samples are outside the 95% confidence region. The Kalman Filter is overconfident and too optimistic about its accuracy.
Let us find the measurement uncertainty that yields the desired estimate uncertainty.
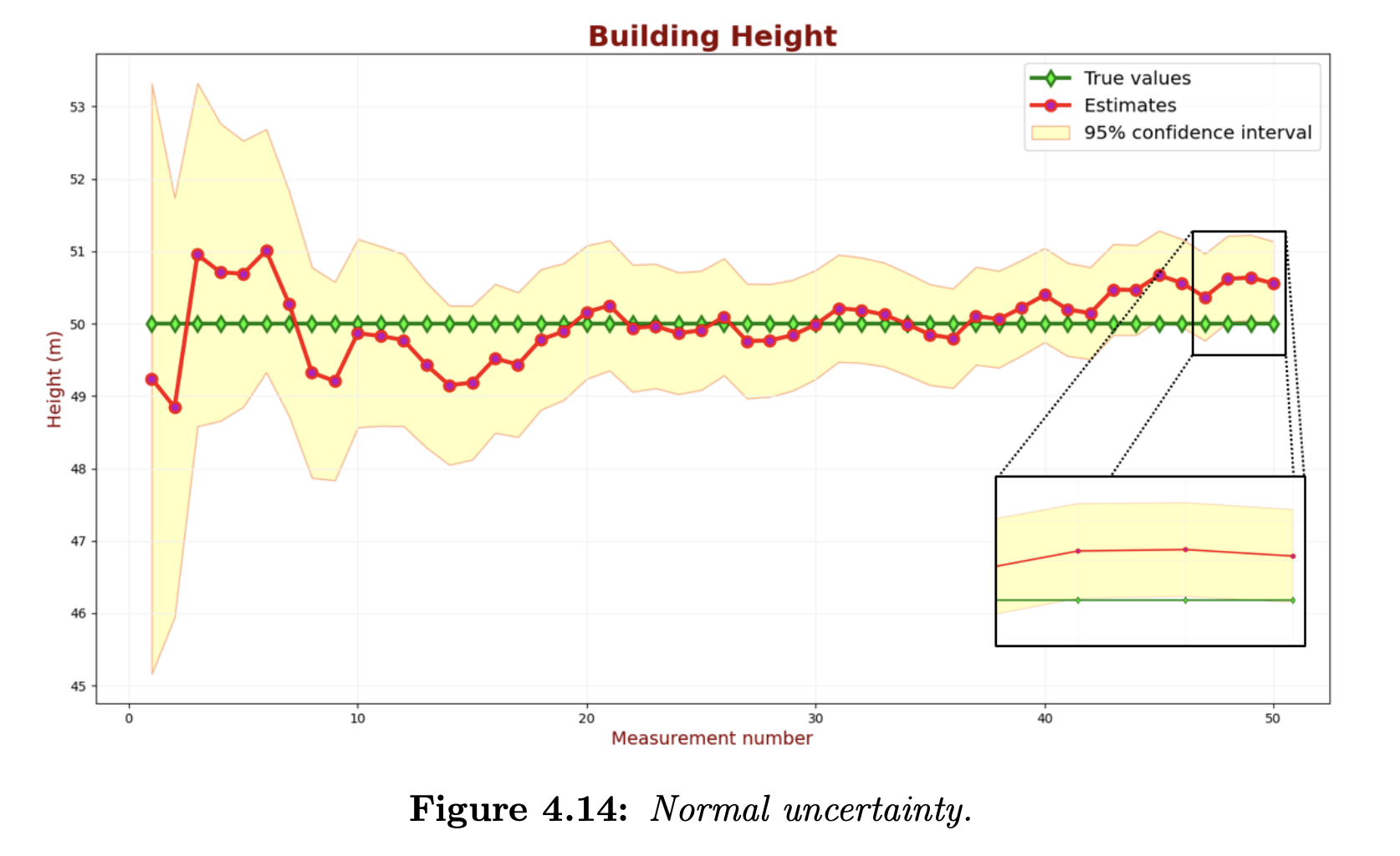
The above chart shows that 2 out of 50 samples slightly exceed the 95% confidence region. This performance satisfies our requirements.