Problem 4.1
Consider composing the two neural networks in figure 4.8. Draw a plot of the relationship between the input and output for .
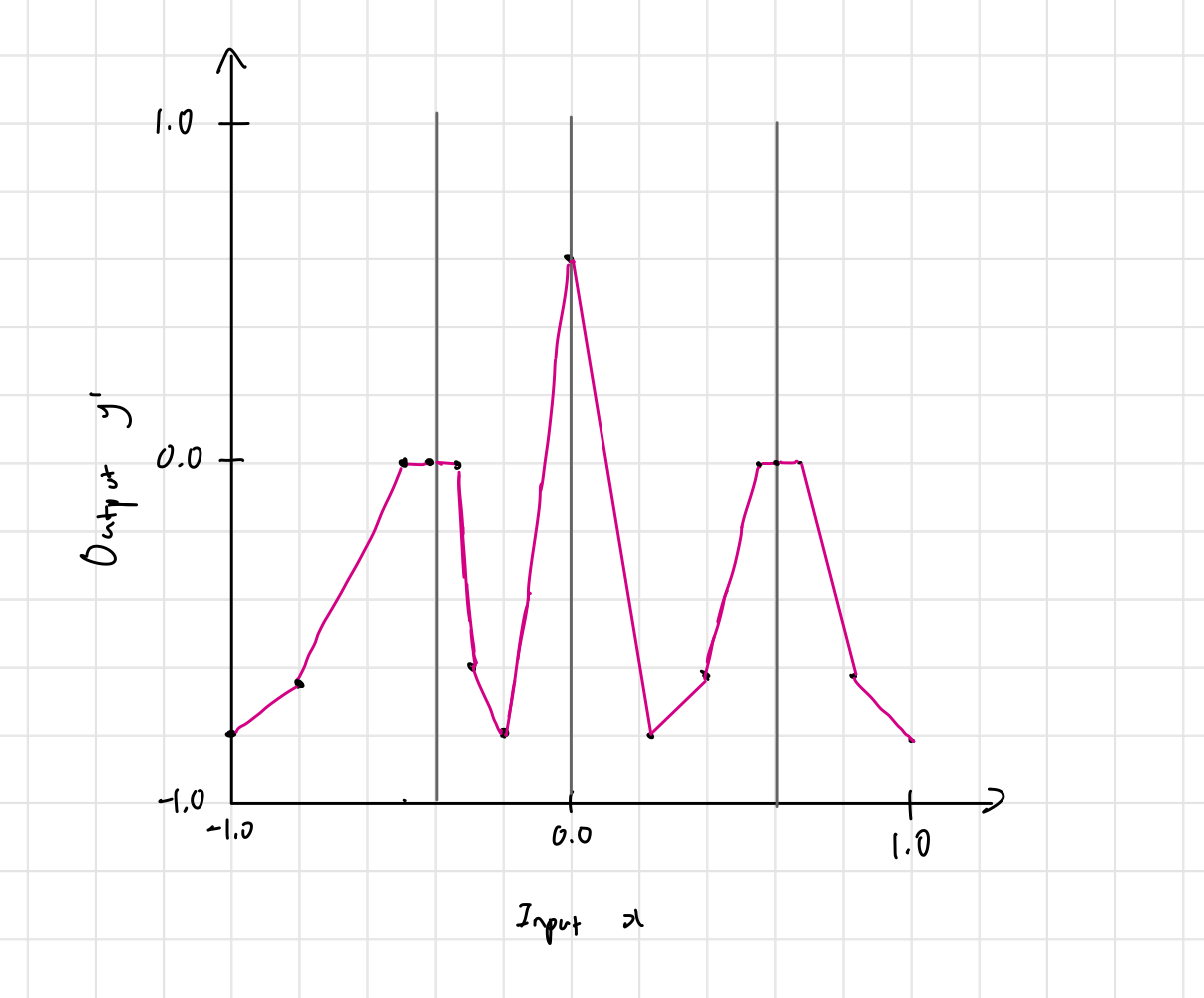
Problem 4.2
Identify the four parameters in figure 4.6.
Problem 4.3
Using the non-negative homogeneity property of the ReLU function (see problem 3.5), show that:
where and are non-negative scalars. From this, we see that the weight matrices can be rescaled by any magnitude as long as the biases are also adjusted, and the scale factors can be re-applied at the end of the network.
The non-negative homogeneity property states that:
We have
as desired.
Problem 4.4
Write out the equations for a deep neural network that takes inputs, outputs and has three hidden layers of sizes , , and , respectively, in both the forms of equations 4.15 and 4.16. What are the sizes of each weight matrix and bias vector ?
Individual equations (like 4.15):
One equation (like 4.16):
Sizes:
Problem 4.5
Consider a deep neural network with inputs, output, and hidden layers containing hidden units each. What is the depth of this network? What is the width?
- Depth is 20 (number of hidden layers)
- Or 21 if we count the output layer? In this case, the definition we’re using is “number of layers with parameters” instead of number of hidden layers
- Width is 30 (number of hidden units in each layer)
Problem 4.6
Consider a network with input, output, and layers, with hidden units in each. Would the number of weights increase more if we increased the depth by one or the width by one?
Original:
- Input to :
- Between 9 hidden layers:
- Last hidden to output:
- Each hidden layer has 10 biases:
- Output layer: bias
- Total:
Increase depth by 1:
- Input to :
- Between 9 hidden layers:
- Last hidden to output:
- Each hidden layer has 10 biases:
- Output layer: bias
- Total:
Increase width by 1:
- Input to :
- Between 9 hidden layers:
- Last hidden to output:
- Each hidden layer has 10 biases:
- Output layer: bias
- Total:
Problem 4.7
Choose values for the parameters for the shallow neural network in equation 3.1 (with ReLU activation functions) that will define an identity function over a finite range .
The function is:
We want it to be the identity function, such that
If we have:
We would get , which only equals and has slope instead of .
Instead, we need
which expands to
If we have:
- , both ReLUs are 0 so
- , the first ReLU is active, so we have
- , both ReLUs are active, so we have
Problem 4.8
Figure 4.9 shows the activations in the three hidden units of a shallow network (as in figure 3.3). The slopes in the hidden units are , , and , respectively, and the “joints” in the hidden units are at positions , , and .
- Find values of , and that will combine the hidden unit activations as to create a function with four linear regions that oscillate between output values of zero and one. The slope of the leftmost region should be positive, the next one negative, and so on.
- How many linear regions will we create if we compose this network with itself?
- How many will we create if we compose it with itself times?
Region 1:
- Only is active. Its joint is at , so the pre-activation for is .
- We need:
- Solving the system of equations gives .
Region 2:
- and are active, which means that the region has a slope of .
- To get the output back down from to , we need a slope of .
- Since we have , this gives .
Region 2:
- , are active, so the slope will be .
- To get the output back up from to , we need slope of .
- Since we have , we have .
Region 4:
- and are active, so the slope will be .
- To get the output down from to , we need a slope of .
- We already achieve this with an .
If we compose the network with itself once, we will get regions; each region in the second network is replicated four times.
If we compose the network with itself times, we will get regions.

Problem 4.9
Following problem 4.8, is it possible to create a function with three linear regions that oscillates back and forth between output values of zero and one using a shallow network with two hidden units? Is it possible to create a function with five linear regions that oscillates in the same way using a shallow network with four hidden units?
It is not possible to create a function with three linear regions that oscillates back and forth between output values of 0 and 1 using a shallow network with two hidden units. At best it can rise and fall once, producing only two linear pieces with opposite slopes.
- Each hidden ReLU unit can change the output slope once—at the joint where that ReLU switches on or off.
- for 0-1-0-1 (or ), we would need two segments that have positive slope, but this isn’t possible because a ReLU only activates once, so the positive hidden unit can only turn on/off once.
- Because one unit’s jump adds a positive amount to the slope and the other unit’s jump subtracts a positive amount, the slope can go up-then-down, down-then-up, but never up-down-up (two flips) or down-up-down.
However, it is possible to create a function with five linear regions that oscillates in the same way using a shallow network with four hidden units, and generally, for hidden units it’s possible to make a function that oscillates back and forth times.
- Four units provide four independent slope jumps, letting you enforce the sign pattern .
- That yields five alternating linear pieces , so the five-region oscillation is achievable with a shallow network that has four hidden units.
Problem 4.10
Consider a deep neural network with a single input, a single output, and hidden layers, each of which contains hidden units. Show that this network will have a total of parameters.
- Input to first hidden layer has weights and biases –
- Between hidden layers we connect units to units
- weights, biases
- This happens times
- Total:
- Last hidden layer and output: weights and bus –
Total:
which is the same thing as .
Problem 4.11
Consider two neural networks that map a scalar input to a scalar output . The first network is shallow and has hidden units. The second is deep and has layers, each containing hidden units. How many parameters does each network have? How many linear regions can each network make (see equation 4.17)? Which would run faster?
The first network has:
The second network has:
For the shallow network, since there is just one input, each hidden unit creates one joint, for a total of 95 joints separating 96 linear regions.
The number of linear regions for the deep network is given by equation 4.17:
In principle, the shallow network will be faster to run on modern hardware as the computation is more parallel.