Definition
We can define logistic regression as optimizing regularized negative log-likelihood for a linear logistic classifier. This can be written as an objective function:
Motivation
For classification, it’s natural to make predictions in and use the 0-1 loss function. However, even for simple linear classifiers, it is very difficult to find values to minimize a simple training error:
This problem is NP-hard, which probably implies that solving the most difficult instances of this problem would require computation time exponential in the number of training examples, . This is due to its lack of smoothness:
- You only have options and so there may be a hypothesis that is close in the parameter space to the optimal parameters, but it makes the same amount of misclassifications as worse hypothesis.
- All predictions are categorical: the classifier can’t express a degree of certainty about whether a particular input should have an associated value .
Formulation
Linear logistic classifiers address the above problem. Instead of making predictions in , they generate real-valued outputs in the interval . A linear logistic classifier has the form:
where denotes the use of the Sigmoid function, which is a smooth function used in place of . This is also called a logistic function in this context. We interpret the output of the sigmoid in this case to be , the probability that is positive.
To make a classifier, we set a prediction threshold of , such that we predict when and vice versa. This is true when , so this is essentially the same as our old linear classifier, just formulated in a way to make optimization easier and get more information from our continuous quantity. We can also set different thresholds.
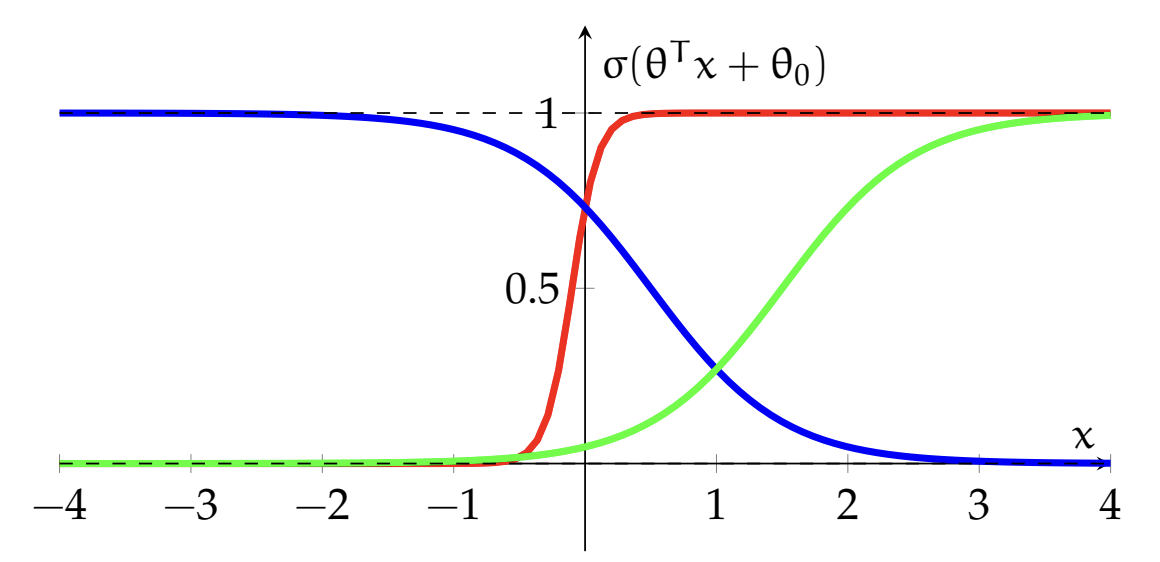
Based on our parameter settings of , we can get differently shaped sigmoid functions.
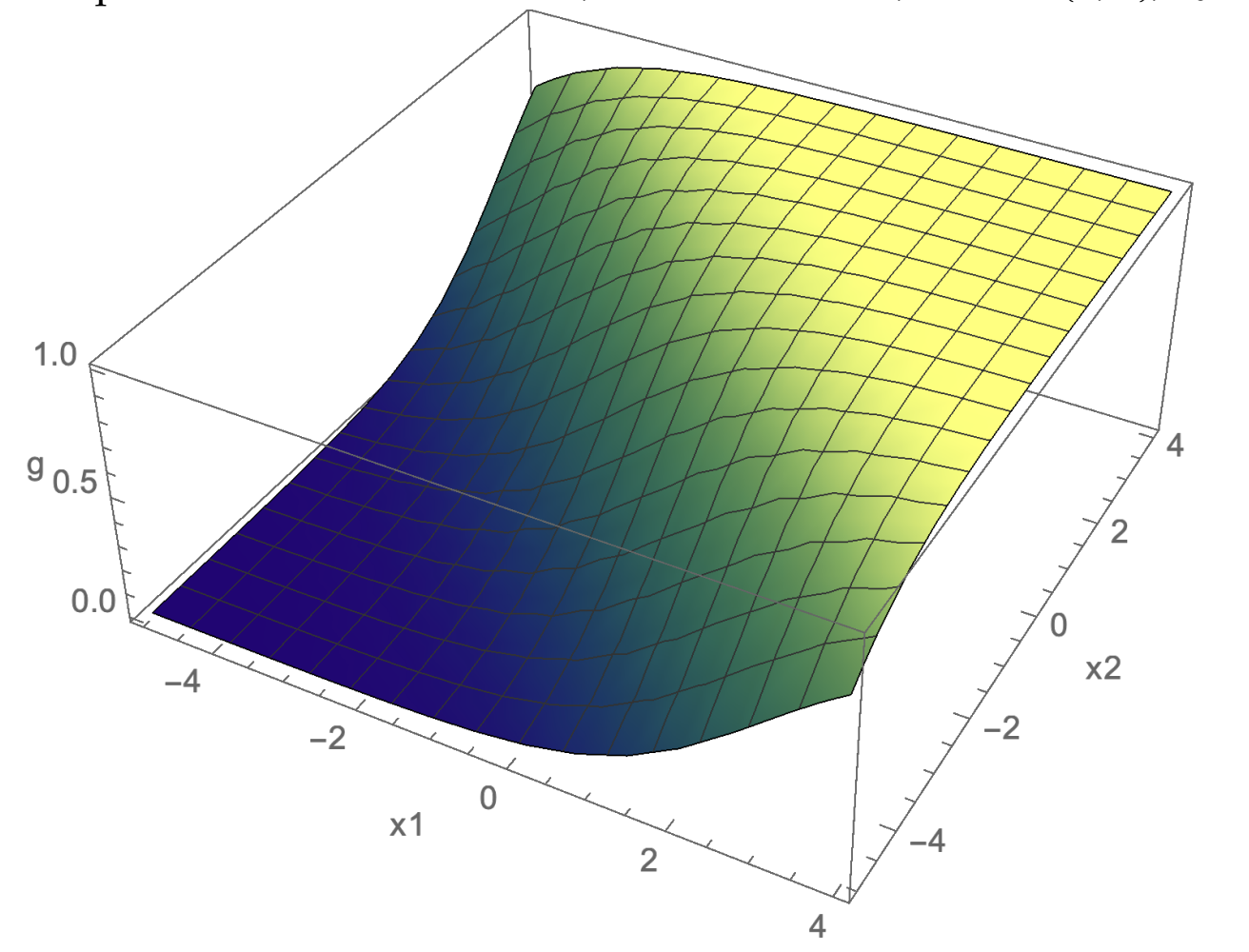
In 2D, our inputs lie on a 2D space with axes and , and the output of the linear logistic classifier is a surface:
Loss Function
We have defined the linear logistic classifier to have probability outputs in but have training data with values in . How do we define a loss function?
We want to define a loss function on our data that is inversely related to the probability assigns to the data. This would mean that we have low loss if we have high probability of it being correct. We also want to have low loss if we assign a low probability to the incorrect class. This can be done using a Binary Cross-Entropy Loss loss function.