It’s more common for the actual horizon of a problem to be unknown. If we tried to take our definition of from Finite-horizon MDP Solutions and set , values for all actions could be infinite, and there would be no way to select one over the other.
There are 2 standard ways to deal with this problem:
- Take the average over all time-steps
- Take a discounted infinite horizon.
In the discounted infinite horizon, we select a discount factor . On each step, our life might with a probability of , giving us an expected lifetime of . Unlike Finite-horizon MDP Solutions, we don’t need a different policy for a different horizon; if we survive today, our expected future lifetime is just as long as yesterday.
Instead of trying to find a policy that maximizes expected finite-horizon undiscounted value,
we will try to find one that maximizes infinite-horizon discounted value:
Unlike finite-horizon and it’s use of (horizon), the indices here are not the number of steps to go, but the number of steps forward from the starting state (there is no notion of “steps to go” in the infinite horizon case).
Why do we do discounting? Two reasons:
- In economic terms, you’d generally rather have some money today than that same amount of money next week (because you could use it now or invest it).
- Think of the whole process terminating, with probability 1 − γ on each step of the interaction. This value is the expected amount of reward the agent would gain under this terminating model.
Finding an optimal policy
The best way of behaving in an infinite-horizon discounted MDP is not time-dependent. At every step, your expected future lifetime, given that you have survived until now, is .
An important theorem about MDPs is: there exists a stationary optimal policy (there may be more than one) such that for all and all other policies , we have
Value iteration
Define to be expected infinite-horizon discounted value of being in state s, executing action a, and executing an optimal policy thereafter. Using similar reasoning the recursive definition of (see Policy Evaluation), we can express this value recursively as
This is also a set of equations, one for each pair. If we knew the optimal action-value function, then we could derive an optimal policy as
We can iteratively solve for the values with the value iteration algorithm:
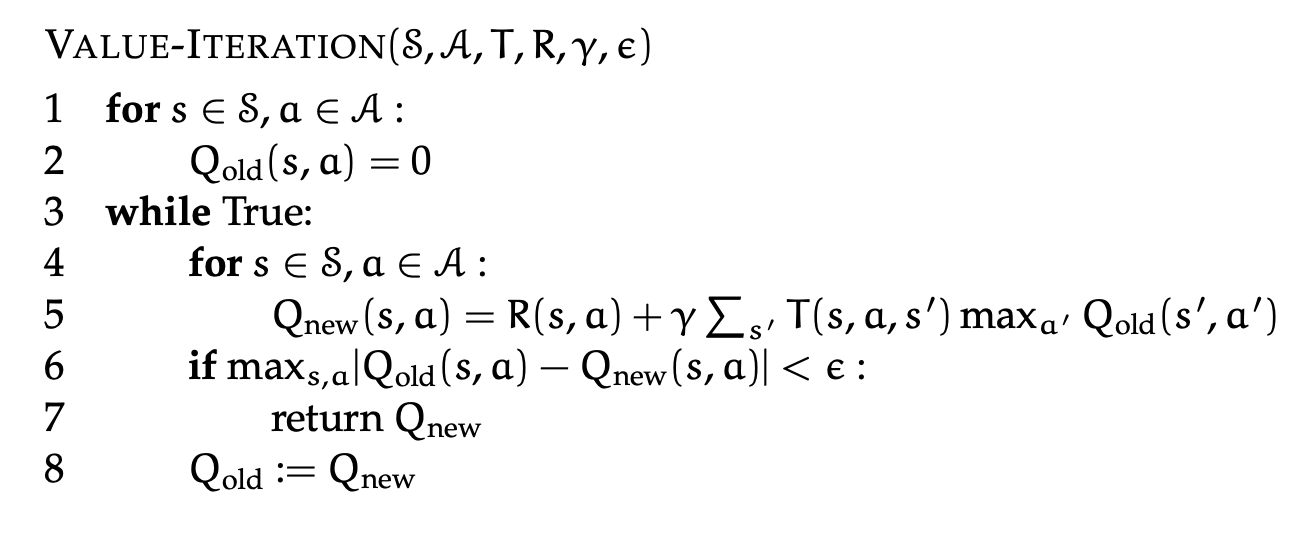
This is essentially just executing the above equation over and over again until we converge to optimal -values! Super simple.
Value Iteration Theory
There are a lot of nice theoretical results about value iteration. For some given (not necessarily optimal) function, define .
- After executing value iteration with parameter , .
- There is a value of such that
- As the algorithm executes, decreases monotonically on each iteration
- The algorithm can be executed asynchronously, in parallel: as long as all pairs are updated infinitely often in an infinite run, it still converges to optimal value.