Consider applying gradient descent to an 1D linear regression model. The model maps a scalar input to a scalar output and has parameter , which represents the -intercept and the slope:
Given a dataset containing input/output pairs, we choose the least squares loss function:
where the term is the individual contribution to loss from the -th training example.
The derivative of the loss function with respect to the parameters can be decomposed into the sum of the derivates of the individual contributions:
where these are given by:
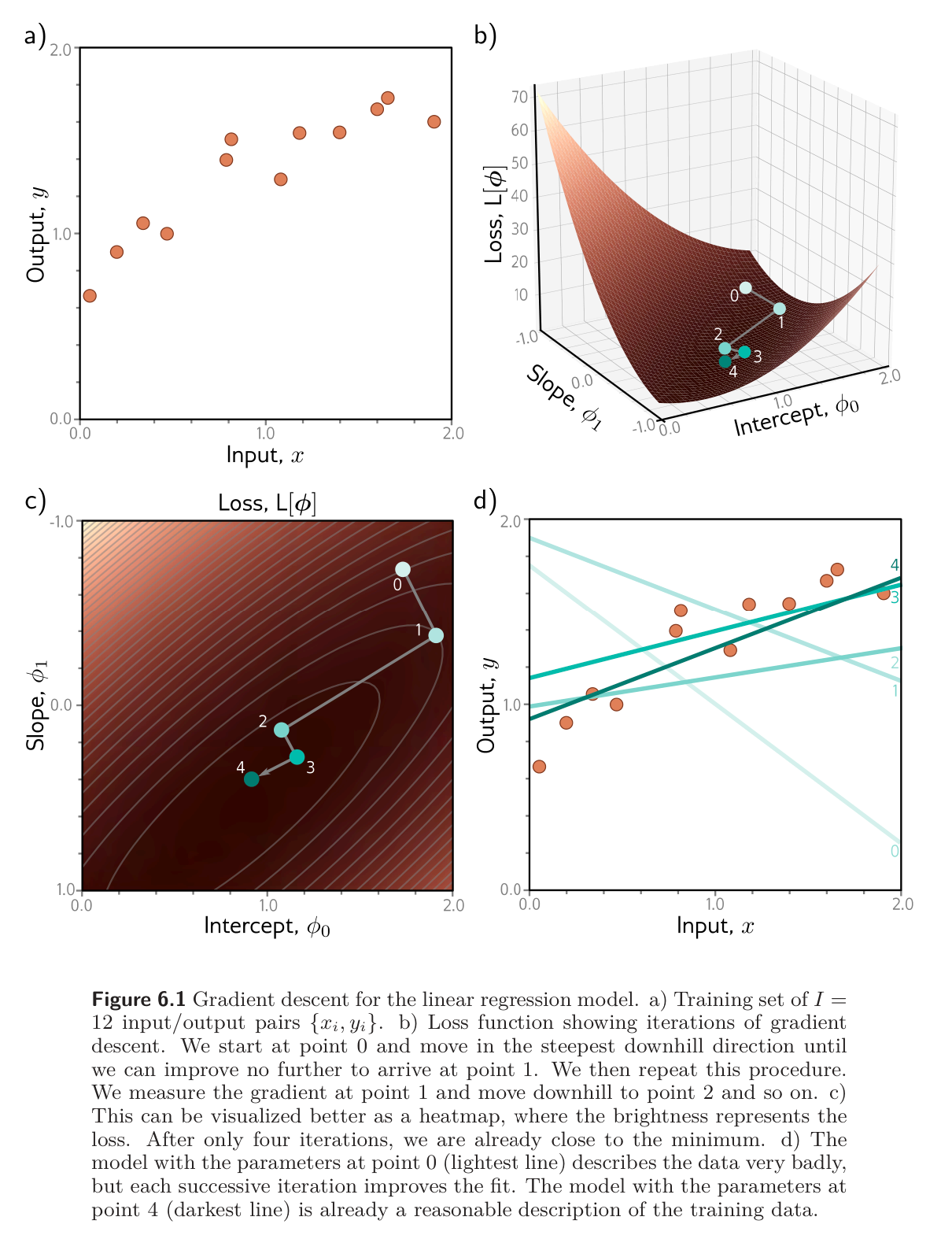
The figure below shows the progression of this algorithm as we iteratively compute the derivatives according to the equations above and update them. In this case, we have used a line search procedure to find the value of that decreases the loss the most at each iteration.