GPT-3 is an example of a decoder model. The basic architecture is similar to encoder models like BERT, where we have a series of transformer layers that operate on learned word embeddings. However, the encoder aimed to build a representation of the text that could be fine-tuned to solve a variety of specific NLP tasks, whereas the decoder has only one purpose: to generate the next token in a sequence.
Autoregressive language modeling
GPT-3 is an autoregressive language model. Consider the sentence “It takes great courage to let yourself appear weak.” For simplicity, let’s assume that the tokens are full words. The probability of the full sentence can be factored as:

An autoregressive model predicts the conditional distributions of each token given all the prior tokens, and hence indirectly computes the joint probability of all tokens:
Thus, the autoregressive next-token prediction objective is exactly equivalent to maximizing the joint probability of the token sequence.
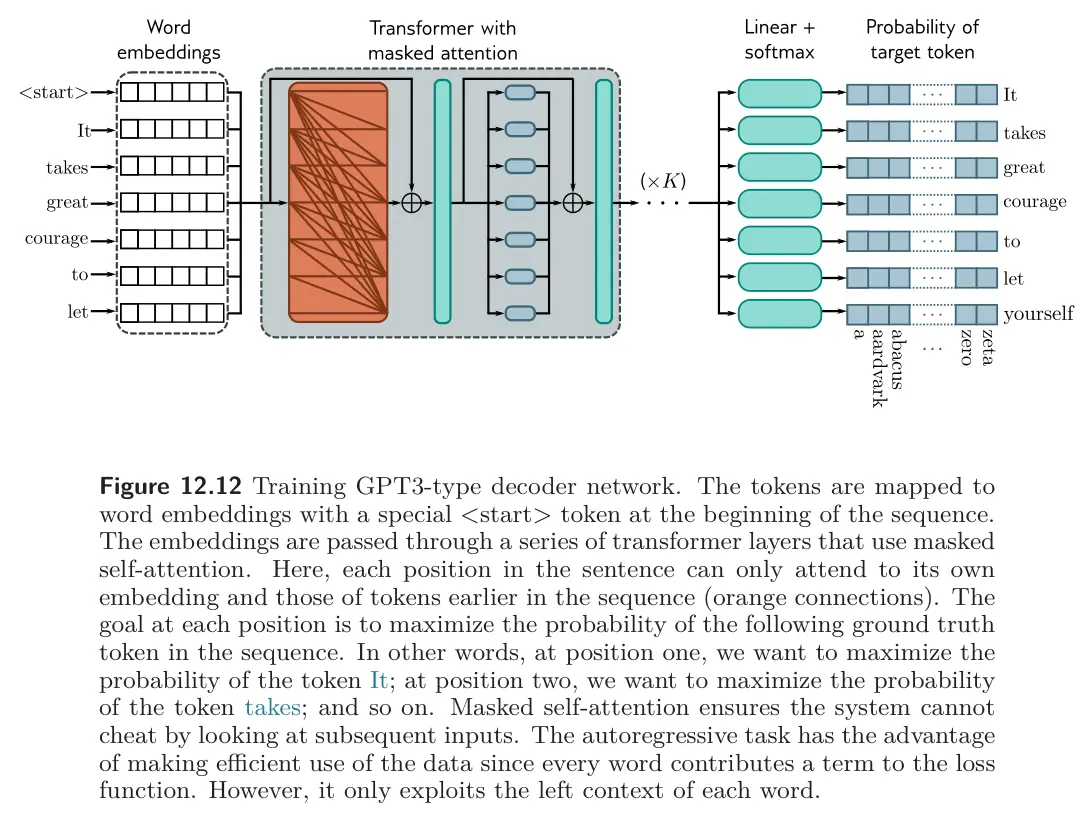
Decoder training
To train a decoder, we seek parameters that maximize the log probability of the input text under the autoregressive model (maximize the sum of the log conditional probability terms). Ideally, we would pass in the whole sentence and compute all the log probabilities and gradients in the same forward pass, rather than doing a forward pass for each token in the sentence. To do this, we use masked self-attention, which ensures that tokens don’t incorporate future information; furthermore, it lets us train on all positions in the sequence simultaneously in a single forward pass.
The entire decoder network operates as follows.
- The input text is tokenized, and the tokens are converted to embeddings.
- The embeddings are passed into the transformer network, but now the transformer layers use masked self-attention so that they can only attend to the current and previous tokens.
- Each output embedding represents the partial sentence up to that position. It is then used to predict the next token in the sequence.
- Thus, after the transformer layer produces the embeddings, a single linear layer maps each output embedding to the size of the vocabulary, followed by a softmax function that converts these values to probabilities.
- During training, we aim to maximize the sum of the log probabilities of the next token in the ground truth sequence at every position using a standard multiclass cross-entropy loss.
Generating text from a decoder
Autoregressive language models are generative models. Since it defined a probability model over text sequences, it can be used to sample new examples of plausible text.
To generate from the model, we start with an input sequence of text (which might just be a <start> token) and feed this into the network, which then outputs the probabilities over possible subsequent tokens. We can then either pick the most likely token or sample from this probability distribution. The new extended sequence can be fed back into the decoder network to yield the probability distribution over the next token. By repeating this process, we can generate large bodies of text. While we do have to do a new forward pass every time, we can save some work by noting that the representations of earlier tokens do not depend on subsequent ones due to the masked self-attention. Thus, we do not need to re-compute the representations of earlier tokens for each forward pass, so the earlier computation can be recycled as we generate subsequent tokens.
Many strategies can make the output text more coherent than completely random sampling or greedily choosing the most likely word at each step.
- Beam Search keeps track of multiple possible sentence completions to find the overall most likely sequence of words.
- Top- sampling randomly draws the next word from only the top- most likely possibilities to proven the system from accidentally choosing from the long tail of low-probability tokens and leading to an unnecessary linguistic dead-end.
GPT-3
GPT-3 applies the above ideas at a large scale. In GPT3, the sequence lengths are 2048 tokens long, with a total batch size of 3.2 million tokens. There are 96 transformer layers (some of which implement a sparse version of attention), each processing a word embedding of size 12288. There are 96 heads in the self-attention layers, with Q/K/V dimensions of 128. In total, it’s trained with 300 billion tokens and contains 175 billion parameters.
Large language models are considered few-shot learners; they can learn to do novel tasks based on just a few examples without fine-tuning. This is demonstrated in the grammar example below, but extends to many tasks. However, performance can be erratic, and the extent to which it is extrapolating from learned examples rather than merely interpolating or copying verbatim is unclear.
