BERT is an encoder transformer model.
- Vocabulary of 30,000 tokens.
- Input tokens are are converted to 1024-dimensional word embeddings and passed through 24 transformer layers.
- Each transformer layer contains a multi-head self-attention mechanism with 16-heads.
- The queries, keys, and values for each head are of dimension 64, such that the matrices are of .
- The dimension of the single hidden layer in the fully connected network is 4096.
- This totals to about 340 million parameters.
BERT uses transfer learning. During pre-training, the parameters of the transformer are learned using self-supervision from a large corpus of text. The goal is for the model to learn general information about the statistics of language. During fine-tuning, the network is adapted to solve a particular task using a smaller body of labelled training data.
Pre-training
To pre-train with self-supervision, BERT predicts missing words from sentences from a large internet corpus. It also uses a secondary task of predicting whether two sentences were originally adjacent in the text, but this only marginally improves performance.
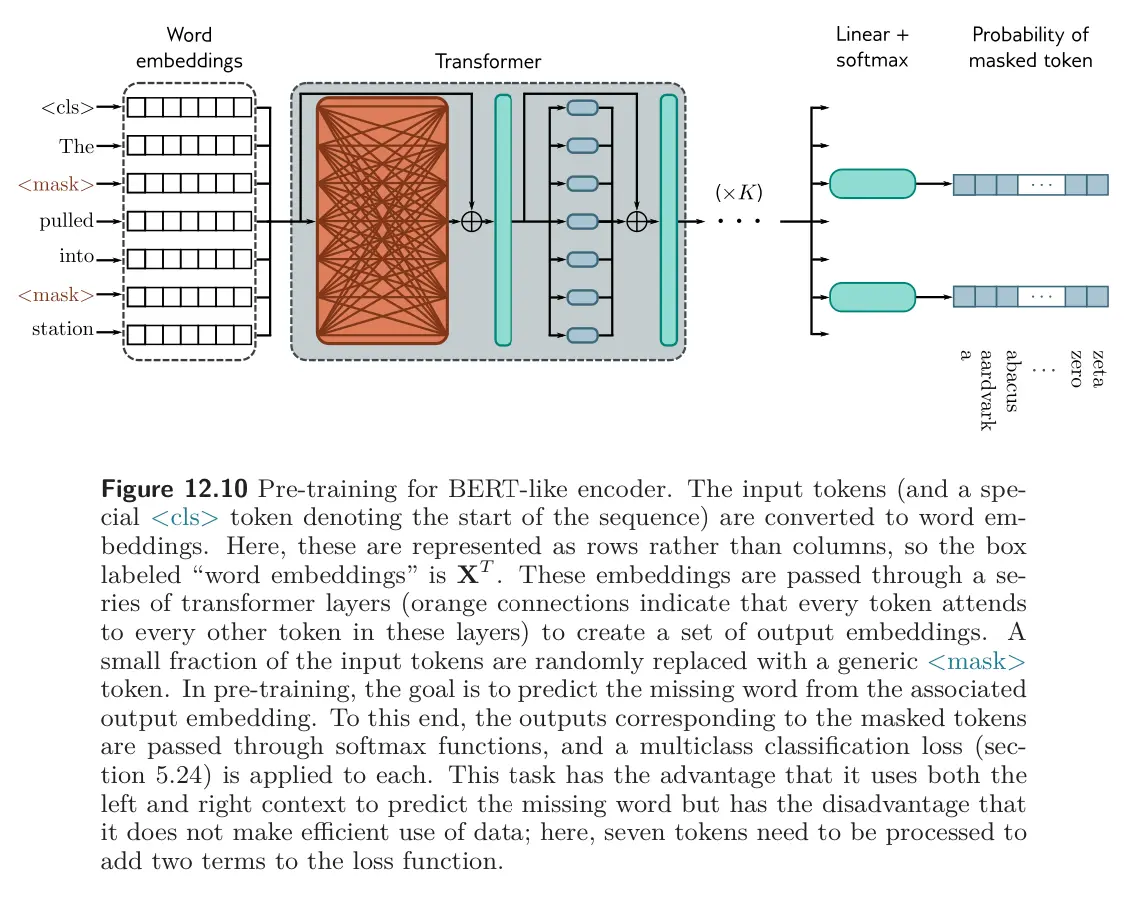
During training, the maximum input length is 512 tokens, the batch size is 256. The system is trained for a million steps.
Predicting missing words forces the transformer network to gain some understanding of syntax. For example, it might learns that:
- An adjective like “red” is often found before nouns like house or car but not before a verb like “shout”
- Some superficial common sense, like assigning higher probability to the missing word “train” in the sentence “The
<mask>pulled into the station” than it would to the word “peanut”.
Fine-tuning
In the fine-tuning stage, the model parameters are adjusted to specialize the network to a particular task. An extra layer is appended onto the transformer network to convert the output vectors to the output format.
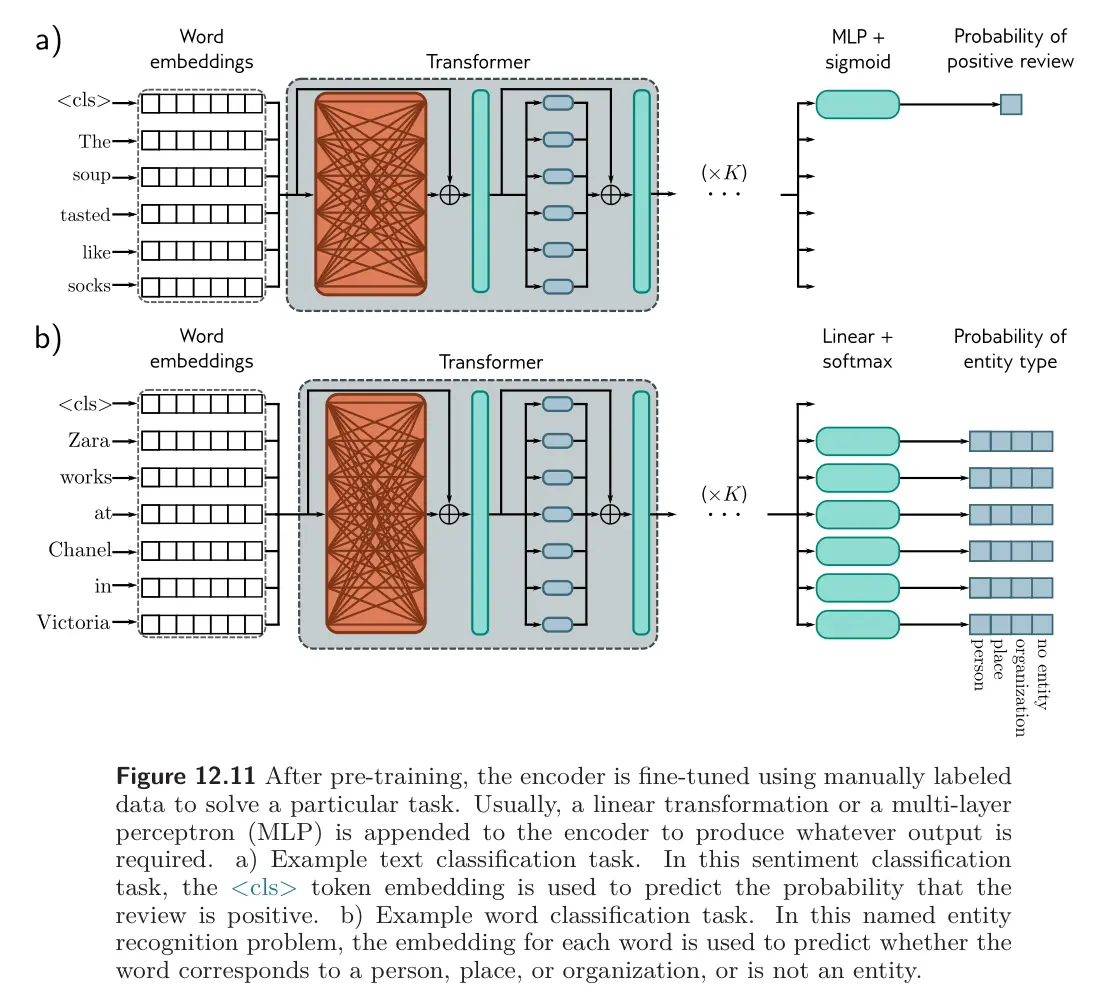
Text classification: A special <cls> token is placed at the start of each input during pre-training. After the transformer processes the sequence, the output embedding corresponding to the <cls> token has attended to all other tokens and serves as a representation of the entire input. For tasks like sentiment analysis, a linear layer is trained to map this embedding to a single logit, which is passed through a logistic sigmoid to predict the probability of a class (e.g., positive sentiment). The prediction is compared with the ground-truth label using the binary cross-entropy loss.
Word classification: The goal of named entity recognition is to identify each word as an entity type (e.g., person, place, organization, etc). To this end, each input embedding is mapped to an vector where the entries correspond to entity types. This is passed through a softmax function to create probabilities for each class, which contribute to a multiclass cross-entropy loss.
Text span prediction: In the SQuAD 1.1 question answering task, the question and a passage from Wikipedia containing the answer are concatenated and tokenized. BERT then predicts the text span in the passage that contains the answer. Each token maps to two numbers indicating how likely it is that the text span begins and ends at this location. The resulting two sets of start logits and end logits are put through two softmax functions. The likelihood of any text span being the answer can be derived by combining the probability of starting and ending at the appropriate places.