We’ve seen that proper weight initialization is critical to ensure that the magnitudes of intermediate values during the forward pass can increase or decrease exponentially. Similarly, gradients during a backward pass can vanish or explode as we move backwards.
He initialization makes it so that the expected variance of the activations (in the forward pass) and gradients (in the backward pass) remains the same between layers. This is done (assuming ReLU activations specifically), by initializing the biases to zero and choosing normally distributed weights with mean zero and variance where is the number of hidden units in the previous layer.
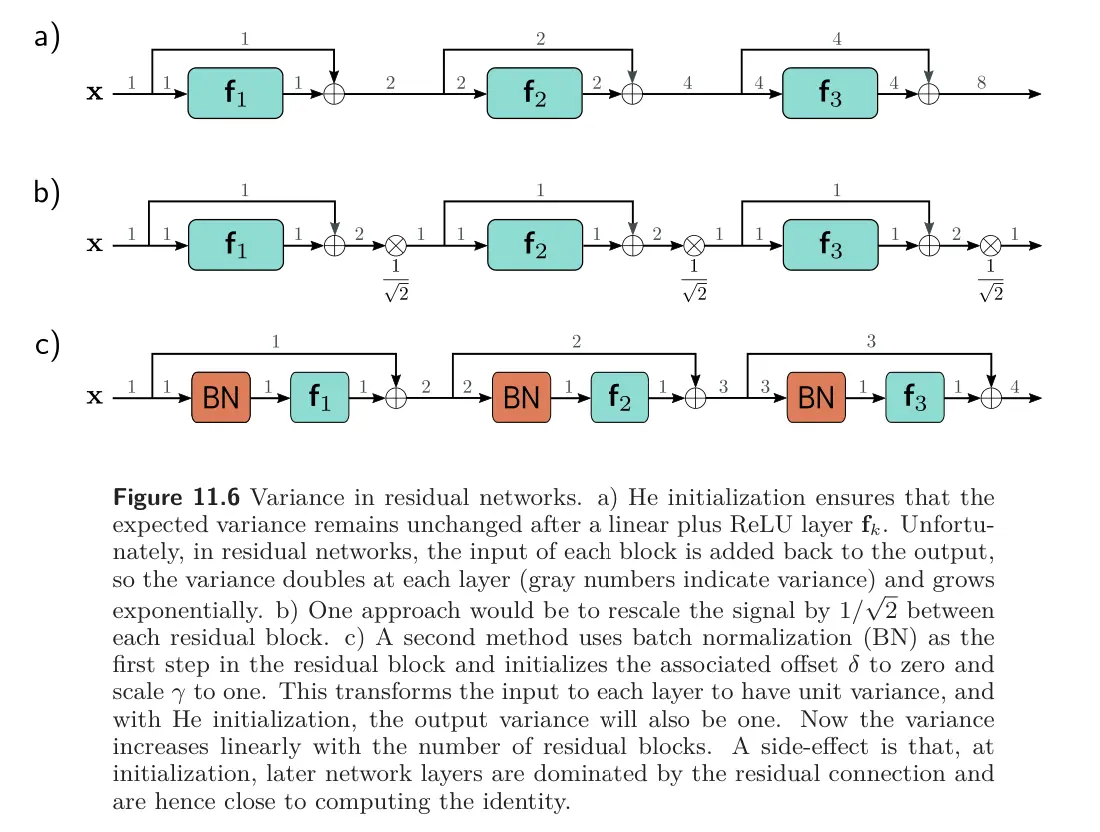
In the case of a residual network, we don’t have to worry about intermediate values or gradients vanishing with network depth, since there’s a direct path whereby each layer contributes to the network output. However, even if we use He initialization inside the residual block, the values in the forward pass increase exponentially as we move through the network.
Why? Consider that we add the result of the processing in the residual block back to the input. Each branch has some (uncorrelated) variability. Thus, the overall variance increases when we recombine them. With ReLU activations and He initialization, the expected variance is unchanged by the processing in each block. Consequently, when we recombine with the input, the variance doubles (11.6a), growing exponentially with the number of residual blocks. This limits the possible network depth before floating point precision is exceeded in the forward pass. A similar argument applies to the gradients in the backward pass of backprop.
One approach that would stabilize the forward and backward passes would be to use He initialization and then multiply the combined output of each residual block by to compensate for the doubling (11.6b). However, we usually instead use BatchNorm to keep the activations/gradients well-scaled.
dl How do we deal with exploding activations or gradients in residual networks?::Batchnorm to keep the activations/gradients well-scaled
Why does variance for activations/gradients grow exponentially with the number of residual blocks?::Each residual block adds its input back to its processed output, which doubles the variance (assuming the branches are uncorrelated)