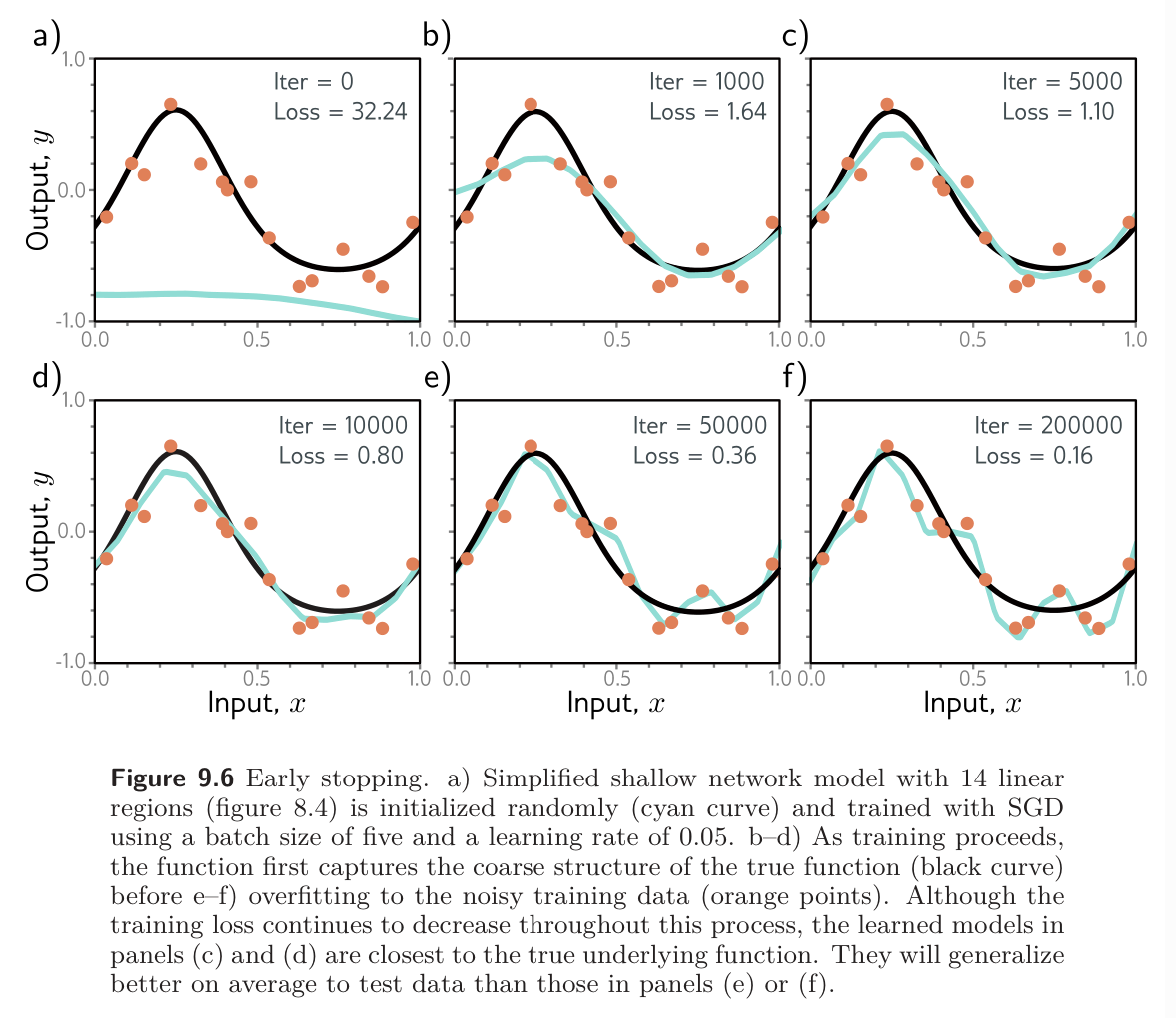
Early stopping is an easy method of regularization where we stop the training procedure before it has fully converged. This can reduce overfitting if the model has captured the coarse shape of the underlying function but has not yet overfit to the noise.
One way to think about this is that since the weights are initialized to small values, they don’t have time to become large, so early stopping has a similar effect to explicit L2 Regularization.
We could also say that early stopping reduces the effective model complexity; we move back down the bias-variance tradeoff curve from the critical region, and the performance improves.
The idea is to train on our training set, but at every epoch (pass through entire training set), we evaluate loss of our current weights on a validation set. Generally, training loss will consistently decrease, while validation loss initially decreases but begins increasing again due to overfitting. Once we see that the validation loss is systematically increasing, we can stop training and return the weights that had the lowest validation error.
We could also simply specify a hyperparameter for the number of steps after which learning is terminated. This is chosen empirically using a validation set. However, for early stopping, the hyperparameter can be selected without the need to train multiple models. The model is trained once, the performance on the validation set is monitored every iteration or every iterations, and the associated parameters are stored. The stored parameters where the validation performance was best are selected.