Backpropagation is used in training a feedforward Multi-layer Neural Network. The idea is that, for a given data sample, we first do a forward pass to compute all the and values at all the layers, and finally the actual loss on this example. Then, we can work backward and compute the gradient of the loss with respect to the weights in each layer, starting at layer and going back to layer 1.
To keep our notation simple, we will only focus on computing the contribution of one data point to the gradient of the loss with respect to the weights. This is the method for Stochastic Gradient Descent, which considers one random point at a time; to do batch gradient descent we can just sum up the gradient over all the points.
To do SGD for a training example , we need to compute , where represents all the weights in all the layers . This can be done using the chain rule. Remember that we are always computing the gradient of the loss function with respect to the weights for a particular value of . That tells us how much we want to change the weights, in order to reduce the loss incurred on this particular training example.
First, let’s start with how the loss depends on the weights in the final layer, . Recall that:
- Our output is
- We use a shorthand to stand for .
- and Now, we can use the chain rule:
To get the dimensions to match, we can write this as:
So, in order to find the gradient of the loss with respect to the weights in the other layers of the network, we just need to be able to find .
If we repeatedly apply the chain rule, we get this expression for the gradient of the loss with respect to the pre-activation of the first layer:
Let’s understand these quantities:
- is and depends on our particular loss function.
- is and is just .
- is . Each element . This means that whenever . So the off-diagonal elements of are all , and the diagonal elements are .
So we can re-write as:
Combining this with equation (1) lets us find the gradient of the loss with respect to any of the weight matrices!
Sequential Module View
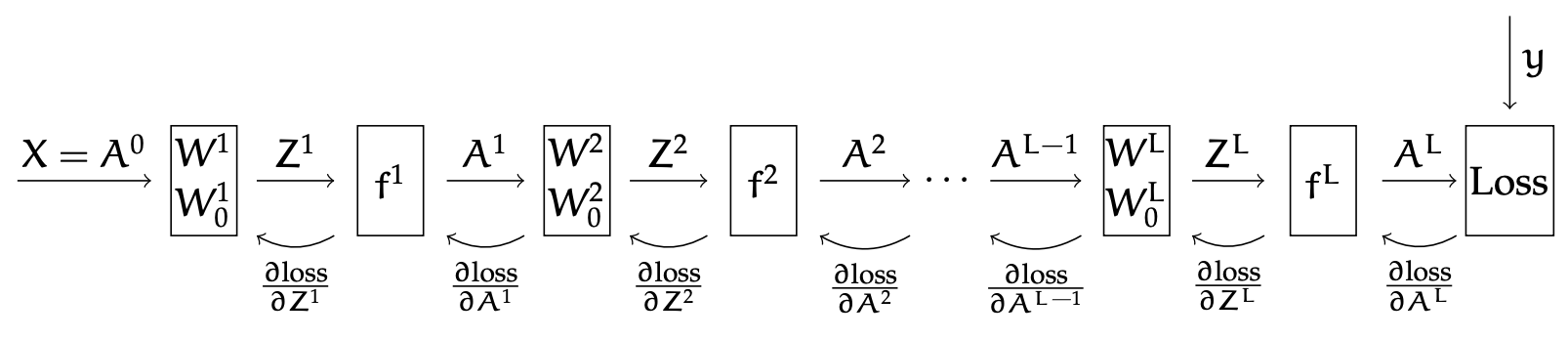
If we view our neural network as a sequential composition of modules (in our work so far, it has been an alternation between linear transformation with a weight matrix, and a component-wise application of a non-linear activation function), then we can define a simple API for a module that will let us compute the forward and backward passes, as well as do the necessary weight updates for gradient descent. Each module has the provide the following methods; letting as the vector input to the method and as the output:
- Forward:
- Backward:
- Weight grad: only needed for modules that have weights .