Let’s repeat the backpropagation toy example but for a three-layer network.
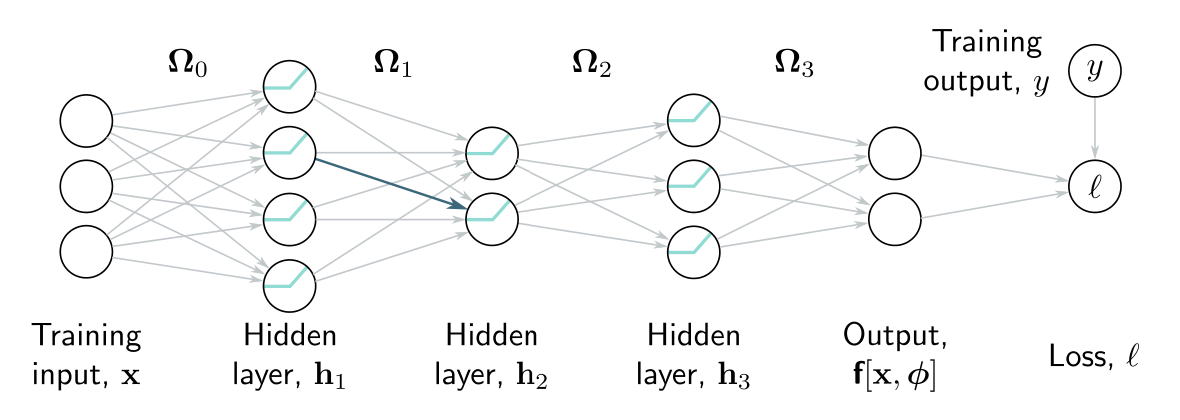
The intuition and much of the algebra are identical. The main differences are that intermediate variables are vectors, the biases are vectors, the weights are matrices, and we are using ReLU functions rather than simple algebraic functions like .
Forward pass
We write the network as a series of sequential calculations:
where:
- represents the pre-activations at the -th hidden layer (values before the ReLU function )
- represents the activations at the -th layer (after the ReLU function)
- The term represents the loss function
In the forward pass, we work through these calculations and store all the intermediate values.
Backward pass 1
Now, let’s consider how the loss changes when the pre-activations change. Applying the chain rule, the expression for the derivative of the loss with with respect to is:
- The first term on the right has size
- is the dimension of the model output
- The second term has size
- is the number of hidden units in the third layer
- The third term has size
Similarly, we can compute how the loss changes when we change and :
- In each case, the term in brackets was computed in the previous step. By working backward through the network, we can reuse previous computations.
Each term tends to be fairly simple:
- (derivative of the loss w.r.t network output ) depends on the loss function but generally has a simple form
- of the network output with respect to hidden layer is: This is shown in Problem 7.6.
- The derivative of the output of the activation function with respect to its input will depend on the activation function.
- It will be a diagonal matrix since each activation only depends on the corresponding pre-activation.
- For ReLU functions, the diagonal terms are zero everywhere is less than zero and one otherwise. Rather than multiply by this matrix, we extract the diagonal terms as a vector and pointwise multiply, which is more efficient.
Backward pass 2
Now that we know how to compute , we can focus on calculating the erivatives of the loss with respect to the weights and biases.
To calculate the derivatives of the loss with respect to biases , we use the chain rule:
which we already calculated above.
Similarly, the derivative of the weights matrix is given by:
- The progression from line 2 to 3 is shown in Problem 7.9 .
The result above makes intuitive sense; the final line is a matrix of the same size as . It depends linearly on , which was multiplied by in the original expression.
This is consistent with the intuition that the derivatives of the weights in will be proportional to the values of the hidden units that they multiply. Recall that we already computed these during the forward pass.