Multiple self-attention mechanisms are usually applied in parallel. Now, different sets of values, keys, and queries are computed:
The -th self-attention mechanism or head can be written as:
where we have different parameters for each head.
Typically, if the dimensions of the input is and there are heads, the values, queries, and keys will all be of size , as this allows for an efficient implementation.
The outputs for these self-attention mechanisms are concatenated along the feature dimension, and another linear transform is applied to combine them:
\text{MhSA}[X] = [\text{Sa}_1[X],\ \text{Sa}_2[X],\ \dots,\ \text{Sa}_H[X]] \,\Omega_c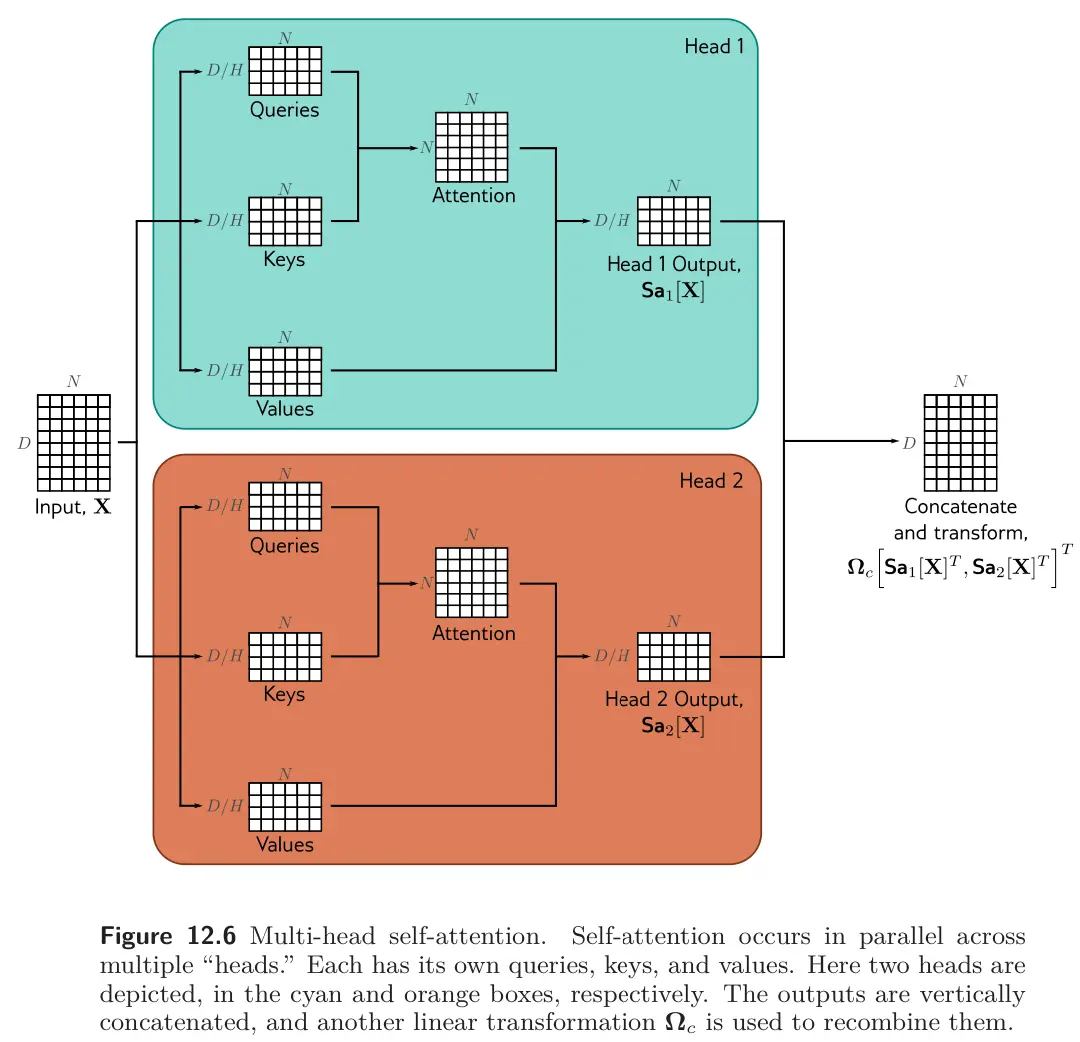
- Note that diagram is using data of shape whereas my equations use . In the case, concatenating along the feature dimension means we concatenate vertically.
Multiple heads seem to be necessary to make self-attention to work well. It has been speculated that they make the self-attention network more robust to bad initializations.
dl Multi-head self-attention ? Run multiple self-attention heads in parallel, concatenate their outputs along the feature dimension, then apply a learned linear transformation to combine them.
\text{MhSA}[X] = [\text{Sa}_1[X],\ \text{Sa}_2[X],\ \dots,\ \text{Sa}_H[X]] \,\Omega_c+++
In multi-head self-attention, if the embedding dimension is and there are heads, what is the dimension of the values, queries, and keys for each head?::