When implemented well, quicksort is typically two to three times faster than mergesort or heapsort.
Suppose we select an arbitrary item from the items we seek to sort. Quicksort separates the other items into two piles: a low pile containing all the elements that are , and a high pile containing all the elements that are . Low and high denote the array positions into which we place the respective piles, leaving a single slot between them for .
Such partitioning buys as two things:
- The pivot element ends up in the exact array position it will occupy in the final sorted order.
- Second, after partitioning no element flips to the other side in the final sorted order.
Thus, we can now sort the elements to the left and the right of the pivot independently! This gives us a recursive sorting algorithm, since we can use the partitioning approach to sort each subproblem. The algorithm must be correct, because each element ultimately ends up in the proper position:
void quicksort(item_type array[], int low, int high) {
int partitionIndex; /* index of partition */
if (low < high) {
partitionIndex = partition(array, low, high);
quicksort(array, low, partitionIndex - 1);
quicksort(array, partitionIndex + 1, high);
}
}We can partition the array in one linear scan for a particular pivot element by maintaining three sections:
- Less than the pivot (to the left of
firsthigh) - Greater than or equal to the pivot (between
firsthighandi) - Unexplored to the right of `i
int partition(item_type array[], int low, int high) {
int i; /* loop counter */
int pivotIndex; /* pivot element index */
int firstHighIndex; /* divider position for pivot element */
pivotIndex = high; /* select last element as pivot */
firstHighIndex = low;
for (i = low; i < high; i++) {
if (array[i] < array[pivotIndex]) {
swap(&array[i], &array[firstHighIndex]);
firstHighIndex++;
}
}
swap(&array[pivotIndex], &array[firstHighIndex]);
return firstHighIndex;
}- Python implementation here: implementations/sorting-algorithms/quicksort.py.
Complexity
Since the partitioning step consists of at most swaps, it takes linear time. Quicksort, like Mergesort, builds a recursion tree of nested subranges of the -element array Like mergesort, quicksort spends linear time processing (now withpartition instead of merge) the elements in each subarray on each level. As with mergesort, quicksort runs in time, where is the height of the recursion tree. The difficulty is that the height of the tree depends upon where the pivot element ends up in each partition.
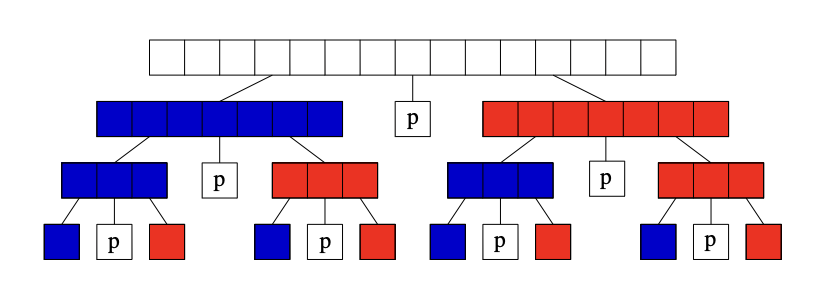
If we get very lucky and happen to repeatedly pick the median element as our pivot, the subproblems are always half the size of those at the previous level. The height represents the number of times we can halve until we get to 1, meaning . This corresponds to the best case of quicksort and is shown below.
The worst case is we get consistently unlucky and our pivot element always splits the array as unequally as possible. This implies that the pivot element is always the biggest or smallest element in the sub-array. After this pivot settles into its position, we will be left with one subproblem of size . After doing linear work we have reduced the size of our problem by just one measly element. It takes a tree of height to chop our array down to one element per level, for a worst case time of .
Average Case
Here is an intuitive explanation of why quicksort runs in time in the average case.
How likely is it that a randomly selected pivot is a good one? The best possible selection for the pivot would be the median key, because exactly half of elements would end up left, and half the elements right, of the pivot. However, we have only a probability of that a randomly selected pivot is the median, which is quite small.
Suppose we say a key is a good enough pivot if it lies in the center half of the sorted space of keys – those ranked from to in the space of all keys to be sorted. Such good enough pivot elements are quite plentiful, since half the elements lie closer to the middle than to one of the two ends, so we have a probability of of picking one. We will make good progress towards sorting whenever we pick a good enough pivot.
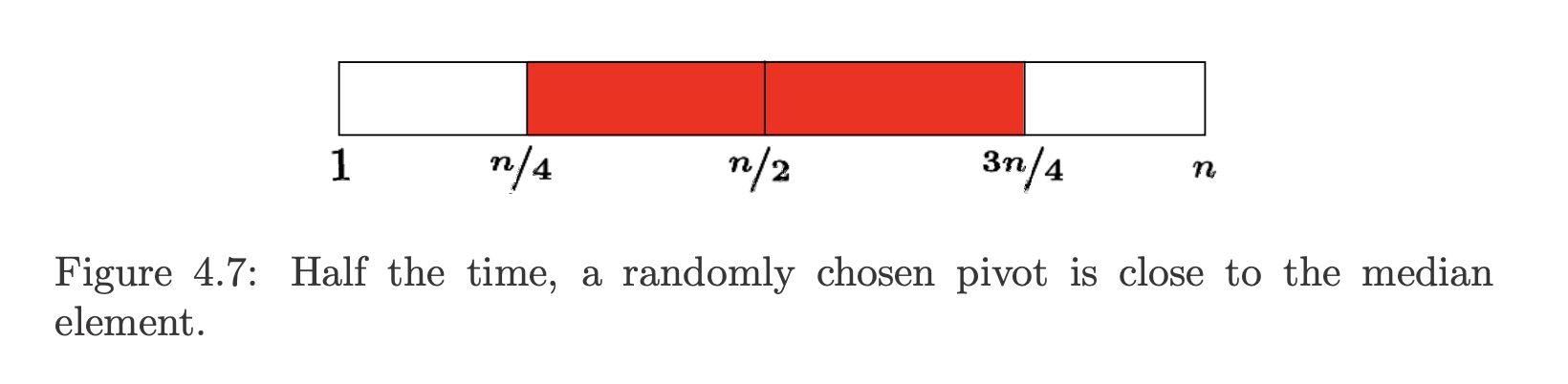
The worst possibly good enough pivot leaves the bigger of the two partitions with items. This is also the expected size (idea of expected value) of the larger partition left after picking a random pivot , at the median between the worse possible pivot ( or leaving a partition of size ), and the best possible pivot ( leaving two partitions of size ).
So what is the height of a quicksort partition tree constructed repeatedly from the expected pivot value? The deepest path through this tree passes through partitions of size down to . How many times can we multiply by until it gets down to ?
so .
- On average, random quicksort partition trees (and by analogy, binary search trees under random insertion) are very good. More careful analysis shows the average height after insertions is approximately . Since , this is only 39% taller than a perfectly balanced binary tree.
- Since quicksort does work partitioning on each level, the average time is .
- If we are extremely unlucky, and our randomly selected elements are always among the largest or smallest element in the array, quicksort turns into selection sort and runs in , but the odds against this are vanishingly small.
Randomization
Our quicksort implementation selected the last element in each sub-array as a pivot. If this program were given a sorted array as input, then at each step it would pick the worst possible pivot, and run in quadratic time.
For any deterministic method of pivot selection, there exists a worst-case input instance which will doom us to quadratic time. We can only claim that quicksort runs in time, with high probability, if we give it randomly ordered data to sort.
But what if we add an initial step where we randomly permute the order of elements before we try to solve them. This can be done in time (see random number generation). This seems like a lot of work but provides the guarantee that we can expect running time whatever the initial input was. The worst case performance still can happen, but it now depends only upon how unlucky we are. Now, we can claim that randomized quicksort runs in time on any input, with high probability.
Alternatively, we can get the same guarantee by selecting a random element to be the pivot at each step.