Typical divide-and-conquer algorithms break a given problem into smaller pieces, each of which is of size . It then spends time to combine these subproblem solutions into a complete result.
Let denotes the worst-case time this algorithm takes to solve a problem of size . Then, is given by the following recurrence relation:
Consider the following examples of this:
- Mergesort – The running time of mergesort is governed by the recurrence . The algorithm divides the data into 2 sub-problems of equal size, and then spends linear time merging the halves after they are sorted. This recurrence evaluates to .
- Binary Search – The running time of binary search is governed by the recurrence . At each step we spend constant time to reduce the problem to 1 sub-problem that is half its size. This recurrence evaluates to .
- Fast heap construction – The “bubble down” method of heap construction builds an -element heap by constructing two element heaps and then merging them with the root in logarithmic time. The running time is thus governed by the recurrence relation . This recurrence evaluates to .
Solving a recurrence means finding a nice closed form describing or bounding the result. We can use the master theorem to solve the recurrence relations typically arising from divide-and-conquer algorithms.
Solving Divide-and-Conquer Recurrences
Divide-and-conquer recurrences of the form are generally easy to solve, because the solutions fall into three distinct cases:
- If for some constant , then .
- If , then .
- If for some constant , and if for some , then .
The above is called the master theorem.
The figure below shows the recursion tree associated with a typical divide-and-conquer algorithm.
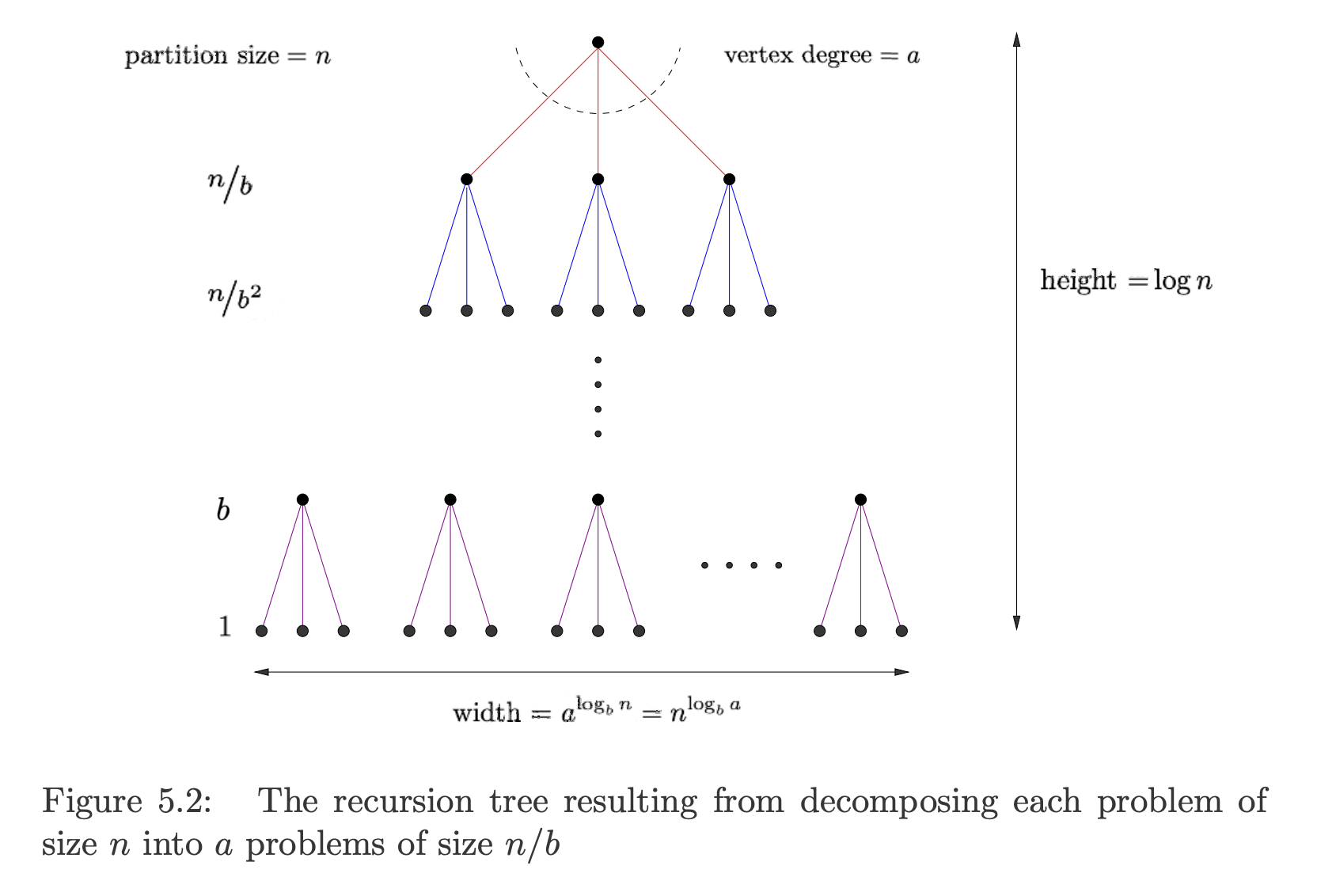
Each problem of size is decomposed into sub-problems of size .
Each subproblem of size takes time to deal with internally; there is an internal evaluation cost at each level of the recursion.
- This includes the work done outside of the recursive calls, such as dividing the problem, processing the subproblems (e.g., partitioning in quicksort), and combining or merging the results (e.g., merging in mergesort).
- At the root, the subproblem size is (where is used to denote the size of the original problem), but as we go down the tree, we have , , etc.
Note on notation: Why do we use instead of ? This recurrence relation describes the total time to solve a problem of size . Here is used in a generic way to denote the size of the current problem (which might be a sub-problem of the original!), instead of the size of the original problem. The function specifically refers to the work done at this level when the problem is of size , while takes a more global view and refers to the work done at different levels of the recursion tree.
The total time for the algorithm is the sum of these internal evaluation costs, plus the time for solving each subproblem.
The height of this tree is and the number of leaf nodes is , which simplifies to .
The three cases of the master theorem correspond to three different costs, each of which might be dominant as a function of , , and :
Case 1: Too many leaves
If the amount of work or sheer number of leaf nodes outweighs the overall internal evaluation cost , the total running time is .
At each level, the recursive subproblems dominate the internal evaluation cost . This means that the work done at each level of the tree decreases as you move down the tree. The total work done in the recursion tree is dominated by the work done at the leaf nodes. Each leaf corresponds to a base case of the recursion, where the problem size is minimal. As such, the overall running time is driven by the sum of all the work done at the leaves.
- Examples: Heap construction and matrix multiplication
Case 2: Equal work per level
As we move down the tree, each problem gets smaller but there are more of them to solve. If the sums of the internal evaluation costs at each level are equal, the total running time is the cost per level () times the number of levels (), for a total running time of .
In this case, there is a significant accumulation of work at each level of the recursion tree, which is why it includes the additional factor.
- Examples: Mergesort. The cost to merge at every level is the same because we are always merging sub-problems of size , such that we have .
Case 3: Expensive Root
If the internal evaluation cost grows very rapidly with , then the cost of the root evaluation may dominate everything. Then the total running time is .
Case 3 generally arises with clumsier algorithms, where the cost of combining the subproblems dominates everything.
See Fast Multiplication Algorithms for an example of evaluating these recurrences.