GRU is another architectural improvement to the RNN, conceptually similar to the LSTM. It uses reset and update gates to control the flow of information and mitigate the vanishing gradient problem.
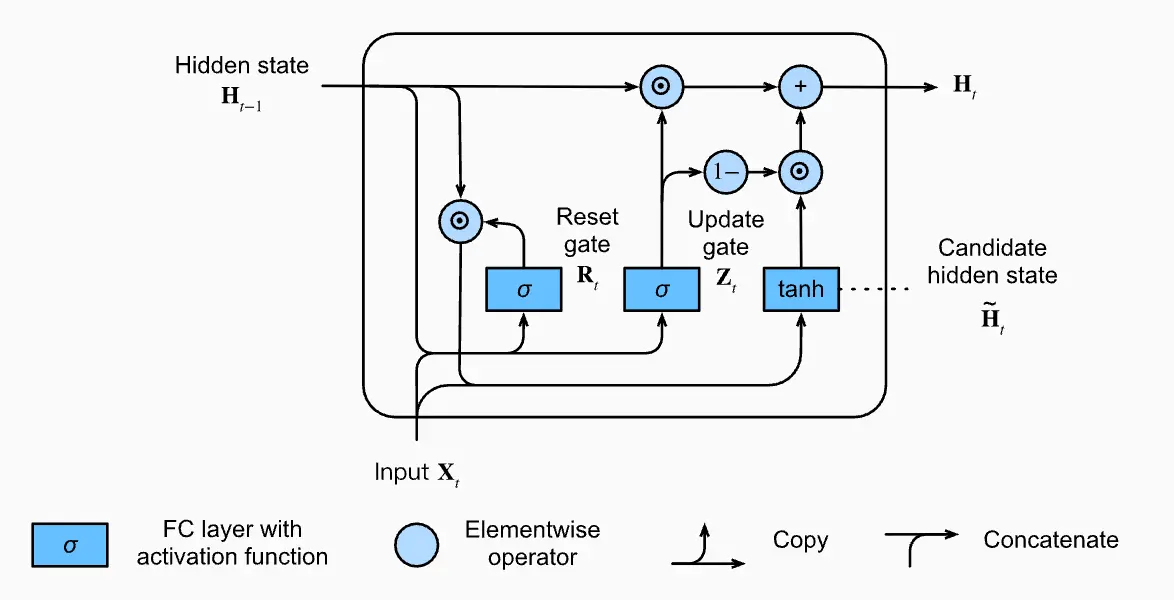
Formulation
Reset Gate
The reset gate controls how much of the previous state we still want to remember. It computes:
The sigmoid forces the value to be between 0 and 1. 0 means that we completely ignore the previous state.
Update gate
The update gate controls how much of the new state is just a copy of the old one. It computes:
Candidate state
The candidate output state that is passed on is calculated as
Note the usage of the reset gate here to control how much of is used.
Output
The final output state is calculated as:
Note how the update gate is used here to weight vs. .