The benefit of an RNN is that it can accumulate a hidden state that encodes input over time. However, it can be hard to maintain information in its hidden state for a long time. Backpropagation through time becomes of exploding/vanishing gradients.
To combat this decay, the LSTM includes an additional “cell state” that persists from step to step. It does not pass through an activation function or get multiplied by the connection weights at each timestep.
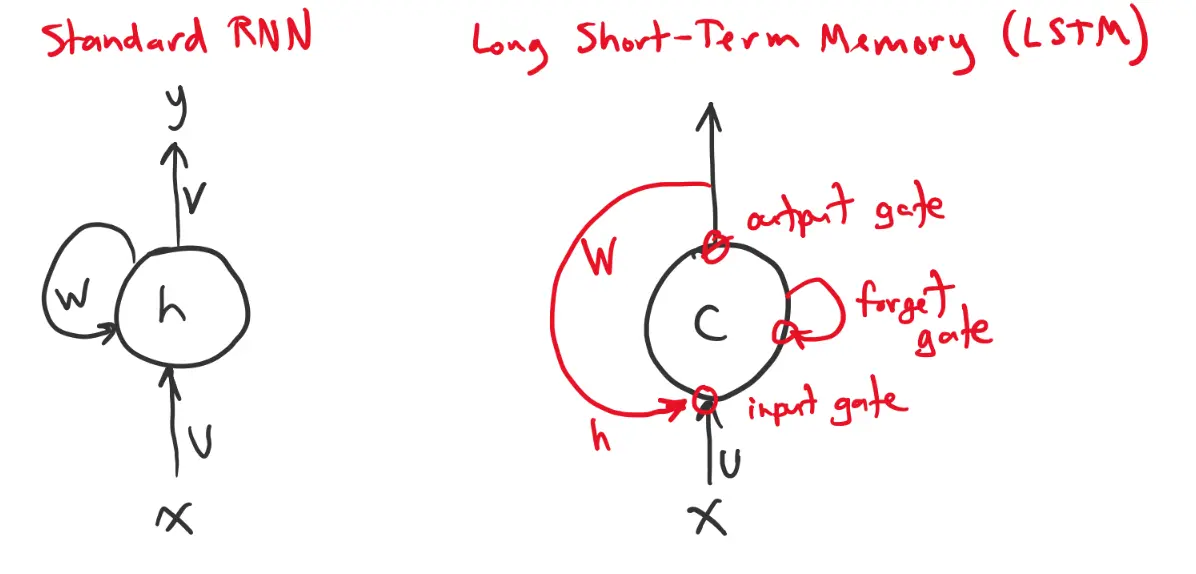
- and can increment (input)
- and can erase (forget)
- and can control the output of (output)
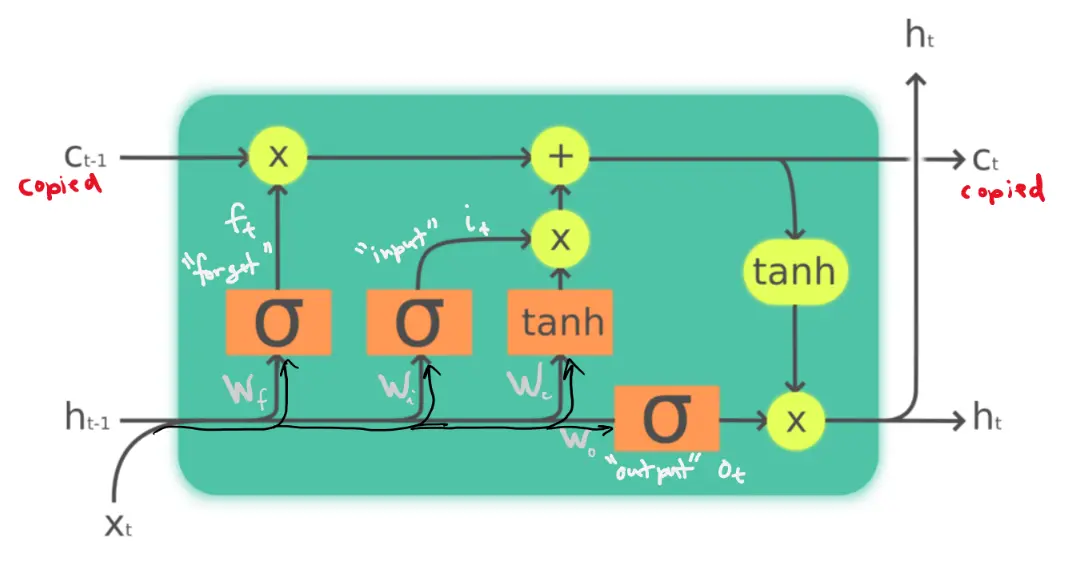
LSTM Formulation
Forget Gate
The forget gate determines whether to keep the current cell state or to flush it. It computes:
The sigmoid function outputs a value between 0 and 1. If 1, we completely persist. If 0, we completely forget. We’ll see how this works later.
Input Gate
The input gate determines how much of the input should be added to . It computes:
Likewise, 1 = input, 0 = no input.
Cell state
A “candidate cell state” is calculated based on the past input hidden state.
Then past and candidate cell states are combined to give the total cell state:
Output Gate
The output gate determines whether the cell state should influence the output. It computes:
where 1 = output and 0 = no output.
Output
Finally, we can compute the output as:
where can be written in one expression as
Gradients
How does this make a difference with respect to solving the exploding/vanishing gradients problem?
We have:
How does depend on ? We have:
As long as is close to , there is little decay of the gradient. Presumably is only close to when we actually want to forget. We don’t want to push gradient lower.
- Note that multiplying by is different from multiplication by .
Essentially, the point is that the cell states evolve additively, When , the gradient can pass backward with little decay. This is much more stable than vanilla RNNs, where gradients are repeatedly multiplied by weight matrices and activation derivatives.