The goal of univariate regression is to predict a single scalar output from using a model with parameters . To use the loss function recipe with a maximum likelihood approach, we try to predict a univariate normal distribution (Gaussian), which is defined over .
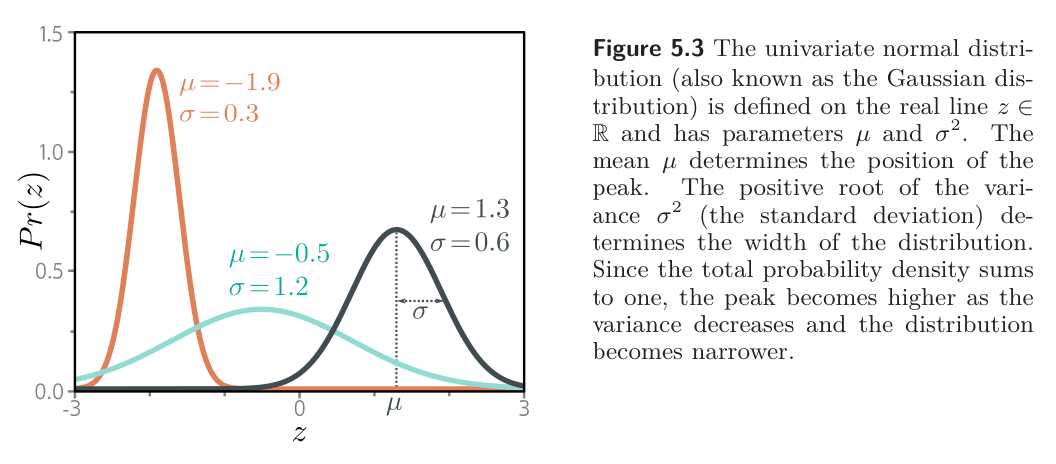
The Gaussian has two parameters, mean and variance , and has a probability density function of
We then need to set the model to to compute one or more parameters of this distribution. Here, we just compute the mean so :
We aim to find the parameters that make the training data most probable under this distribution. To do this, we choose a loss function based on negative log-likelihood:
When we train the model, we seek parameters that minimize this loss.
Least squares loss function
We can perform some algebraic manipulation on the loss function above.
- We removed the first term between the 2nd and 3rd lines because it doesn’t depend on – doesn’t affect the position of the minimum.
- We removed the denominator between the 3rd and 4th lines because it’s just a constant positive scaling factor – doesn’t affect the position of the minimum.
The result that we arrive is the least squares function that we use for linear regression.
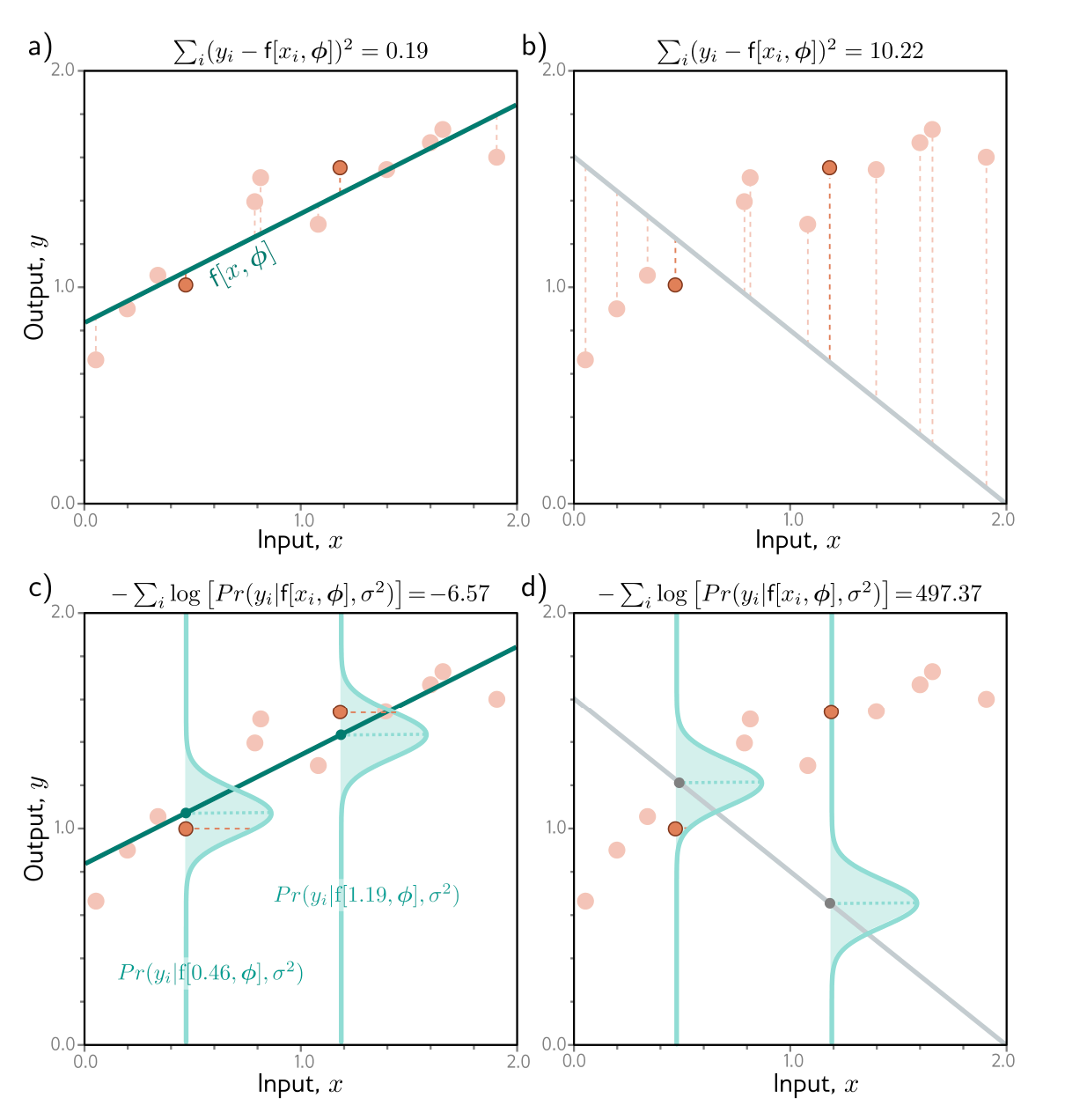
We can see that least squares and maximum likelihood loss are equivalent for the normal distribution.
- (a) Consider the linear model we saw for linear regression. The least squares criterion minimizes the sum of the squares of the deviations (dashed line) between the model prediction (green line) and ground truths (orange points). Here the fit is good, so these deviations are small.
- (b) For these parameters, the fit is bad, and the squared deviations are large.
- (c) The least squares criterion follows from the assumption that the model predicts the mean of a normal distribution over the outputs and that we maximize the probability. For the first case, the model fits well, so the probability of the data (horizontal orange dashed lines) is large, which in turn means the negative log probability is small.
- (d) For this case, the model fits badly, so the probability is small and the negative log probability is large.
Inference
The network no longer directly predicts but instead predicts the mean of the normal distribution over . When we perform inference, we usually want a single “best” point estimate , so we take the maximum of the . predicted distribution:
For the univariate normal distribution, the maximum position is determined by the mean parameter . This is exactly what the model computed, so .
Estimating variance
To formulate the least squares loss function, we assumed that the network predicts the mean of a normal distribution. The final expression above for the best parameters did not depend on the variance . However, we can easily also treat as a learned parameter; then, we can minimize the loss function with respect to both the model parameters and the variance :
In inference, the model predicts the mean from the input, and we learned the variance during the training process. Then, is the best prediction and tells us about the uncertainty of th