Problem 7.1
A two-layer network with two hidden units in each layer can be defined as:
where the functions are ReLU functions. Compute the derivatives of the output with respect to each of the 13 parameters and directly. The derivatives of the ReLU function with respect to its input is the indicator function , which returns one if the argument is greater than zero and zero otherwise.
Output layer:
Second hidden layer: Let us first define
Then:
First hidden layer: Let us first define
Then we have:
Problem 7.2
Find an expression for the final term in each of the five chains of derivatives in equation 7.13.
Problem 7.3
What size are each of the terms in equation 7.20?
- is
- is
- is
- is
Problem 7.4
Calculate the derivative for the least squares loss function:
Problem 7.5
Calculate the derivative for the binary classification loss function:
For the sake of clean math let’s write . So we want to find .
We have:
The first term is:
The second term is:
Combining them back, we have:
Recall that the sigmoid is:
Let’s substitute these back into our loss function and simplify:
\begin{align} \frac{ \partial \ell_{i} }{ \partial f } & = \left( (1-y_{i}) \left( \frac{1+\exp[-f]}{\exp[-f]} \right) - (y_{i}) (1+\exp[-f]) \right) \left( \frac{\exp[-f]}{(1+\exp[-f])^{2}} \right) \\[2ex] & = \left( \frac{(1-y_{i})(1+\exp[-f])}{\exp[-f]} - (y_{i}) (1+\exp[-f])\right)\left( \frac{\exp[-f]}{(1+\exp[-f])^{2}} \right) \\[2ex] & =\cancel{ (1+\exp[-f]) }\left( \frac{1-y_{i}}{\exp[-f]} - y_{i} \right)\left( \frac{\exp[-f]}{(1+\exp[-f])^\cancel{ {2} }} \right)\\[2ex] & =\left( \frac{1-y_{i}}{\exp[-f]}-y_{i} \right)\left( \frac{\exp[-f]}{1+\exp[-f]} \right) \\[2ex] & = \frac{1-y_{i}}{1+\exp[-f]}-\frac{y_{i}\exp[-f]}{1+\exp[-f]} \\[2ex] & = \frac{1-y_{i}-y_{i}\exp[-f]}{1+\exp[-f]} \\[2ex] & = \frac{1}{1+\exp[-f]}- \frac{y_{i}+y_{i}\exp[-f]}{1+\exp[-f]} \\[2ex] & = \frac{1}{1+\exp[-f]}-\frac{y_{i}(1+\exp[-f])}{1+\exp[-f]} \\[2ex] & = \frac{1}{1+\exp[-f]} - y_{i} \\[2ex] & =\boxed{\text{sig}[f]-y_{i}} \end{align}Nice result (and seems important)!
Problem 7.6
Show that for :
where is a matrix containing the term in its -th column and -th row.
To do this, first find an expression for the constituent elements , and then consider the form that the matrix must take.
Let:
so that . We can see this is in action in Example Computation – is a dot product between and the -th row of , and then we add the bias for that row.
Now let’s consider the element-wise derivative. For some fixed and :
This is because depends linearly on each , so the partial derivative just plucks out the corresponding weight.
Then, since is a matrix containing the term in its -th column and -th row”:
Now we can notice that the matrix whose entry is is precisely the transpose of , leading us to:
If you instead store instead in row , column —the more common “Jacobian” convention—the matrix would be itself. The textbook’s row/column choice therefore introduces the transpose.
Problem 7.7
Consider the case where we use the logistic sigmoid as an activation function, so . Compute the derivative for this activation function. What happens to the derivative when the input takes (i) a large positive value and (ii) a large negative value?
We have:
and it follows that
which can then be re-written as:
When the input becomes large positive value, , so we have . When the input becomes a large negative value, we in turn have , which gives . Thus, the gradient is (near) zero at both extremes.
Problem 7.8
Consider using (i) the Heaviside function and (ii) the rectangular function as activations:
Discuss why these functions are problematic for neural network training with gradient-based optimization methods.
Both of these functions are flat and discontinuous.
In regions where the function is flat, weights before the activation will not change because the chain rule will include a multiplication by zero. For some weight :
In this case because the activation is flat, so we also just have and the weight doesn’t update at all.
In regions where the function is discontinuous, there’s no gradient to follow (undefined) – optimization algorithms like gradient descent are stuck.
Problem 7.9
Consider a loss function , where . We want to find how the loss changes when we change , which we’ll express with a matrix that contains the derivative at the -th row and -th column. Find an expression for , and, using the chain rule, show that
We have
and so:
Using the chain rule:
Converting back to vector form, we have
as required.
Problem 7.10
Derive the equations for the backward pass of the backpropagation algorithm that uses leaky ReLU activations, which are defined as:
where is a small positive constant, typically .
The Leaky ReLU has a gradient of when the input is greater than zero, and a gradient of when the gradient is less than zero. The backprop equations are the same except for
Problem 7.11
Consider training a network with fifty layers, where we only have enough memory to store the pre-activations at every tenth hidden layer during the forward pass. Explain how to compute the derivatives in this situation using gradient checkpointing.
We just start from each 10th hidden layers.
- We have the loss gradient at 50 and the saved checkpoint at 40, so we recompute the forward for layers 41-50 from the saved state at 40. Then we backprop through 50 to 41, accumulating parameter grads and the gradient wrt the activation at layer 40.
- Then we just move to the next window - recompute forward 31 to 40, 21–30, 11–20, and 1–10,
Problem 7.12
This problem explores computing derivatives on general acyclic computational graphs. Consider the function:
We can break this down into a series of intermediate computations so that:
The associated computational graph is shown below.
Compute the derivative by reverse-mode differentiation. In other words, compute in order:
using the chain rule in each case to make use of the derivatives already computed.
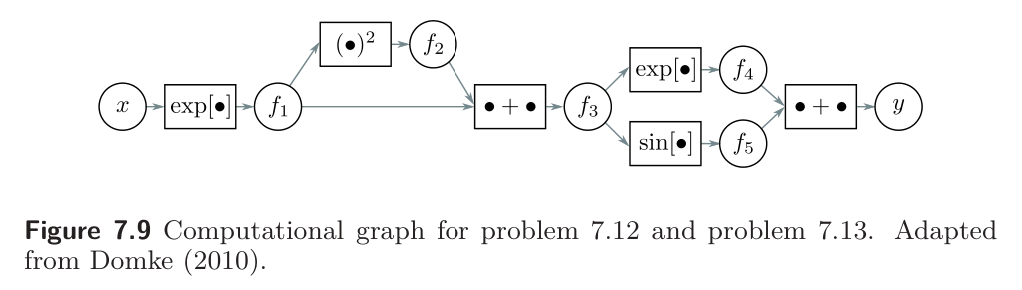
Problem 7.13
For the same function as 7.12, compute the derivative by forward-mode differentiation. In other words, compute in order:
using the chain rule in each case to make use of the derivatives already computed. Why do we not use forward-mode differentiation when we calculate the parameter gradients for deep networks?
We don’t do forward mode differentiation because for each input variable we will need to do a pass, whereas for backward mode we will have to do a pass for each output variable. Generally neural networks have fewer outputs (usually just a scalar loss) than inputs, so backward mode is cheaper.
Example with two input variables
Let’s tweak Problem 7.12 graph to have two inputs and while keeping the same structure:
Forward mode needs one pass per input:
- Pass 1 (derivatives with respect to ):
- Pass 2 (derivatives with respect to ):
Reverse mode only requires one pass:
Problem 7.14
Consider a random variable with variance and a symmetrical distribution around the mean . Prove that if we pass this variable through the ReLU function
then the second moment of the transformed variable is .
We have:
where is an indicator function that returns 1 is the condition inside the brackets is true and 0 if false.
Then:
To find this, let’s try to first find an expression for in terms of .
Since is symmetric around 0, we have:
Splitting into positive and negative parts:
Therefore,
Since . Thus,
as desired.
Problem 7.15
What would you expect to happen if we initialized all of the weights and biases in the network to zero?
During gradient descent, we calculate how each neuron in a layer affects the loss. However, if all the weights are initialized to zero, all the neurons in the same layer have identical gradients; while they will update so that they are not zero, they will all update the same way.
If neurons in a layer are clones, they compute the same function, so the network loses its ability to learn different features. The output will stay the same forever.
Problem 7.16
see github
Problem 7.17
see github