In binary classification, the goal is to assign the data to one of two discrete classes . In this context, we refer to as a label.
Examples of binary classification:
- Predicting whether a restaurant review is positive () or negative () from text data
- Predicting whether a tumor is present () or absent ()
We can follow the loss function recipe to construct the loss function. First, we choose a probability distribution over the output space . A suitable choice is the Bernoulli Distribution, which is defined on the domain . This has a single parameter that represents the probability that :

This can equivalently be written as
Then, we set the model to predict the single distribution parameter . However, can only take values in the range , and we cannot guarantee that the network output will lie in this range. Thus, we pass the network output through a function that maps the real numbers to . A suitable choice is the sigmoid:
Hence, we predict the distribution parameter as . The likelihood then becomes:
This is shown below for a shallow neural network model:
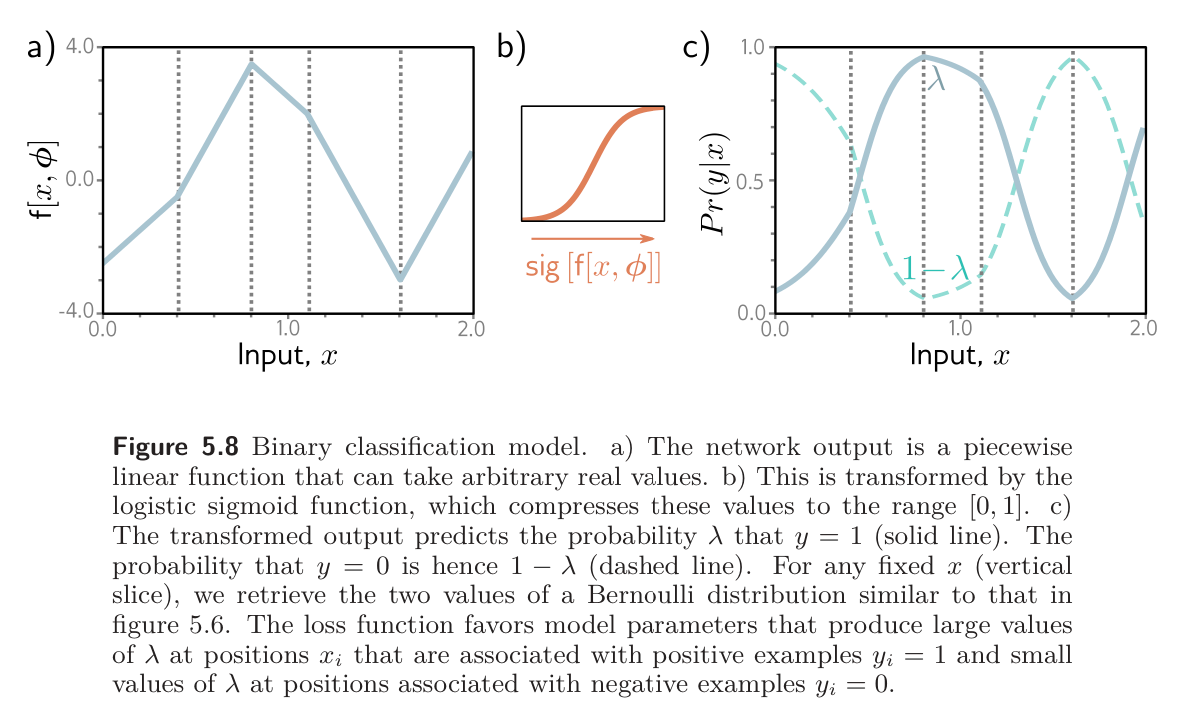
The loss function is the negative log-likelihood of the training set:
This is known as binary cross-entropy loss.
The transformed model output predicts the parameter of the Bernoulli distribution. This represents the probability that , and it follows that represents the probability that . When we perform inference, we may want a point estimate of , so we set if and otherwise.
An important result is that:
where is the loss for a particular data sample. See question 7.5 of UDL Chapter 7 Problems for how this is derived – I quite liked this derivation!