We saw a basic semantic segmentation network that used an encoder-decoder hourglass structure.
- The encoder downsamples the image until the receptive fields are large and information is integrated from across the image.
- The decoder then upsamples it back to the size of the original image. The final output is the probability over possible object classes at each pixel.
The drawback of this architecture is that the low-resolution representation in the middle of the network must “remember” the high resolution details to make the final results accurate. This is unnecessary if residual connections transfer the representations from the encoder to their partner in the decoder.
U-Net is an encoder-decoder architecture where the earlier representations are concatenated to the later ones.
- The original implementation used “valid” convolutions, so the spatial size decreases by two pixels each time a convolutional layer is applied. This means that the upsampled version is smaller than its counterpart in the encoder, which must be cropped before concatenation.
- Subsequent implementations use zero-padding, where no cropping is necessary.
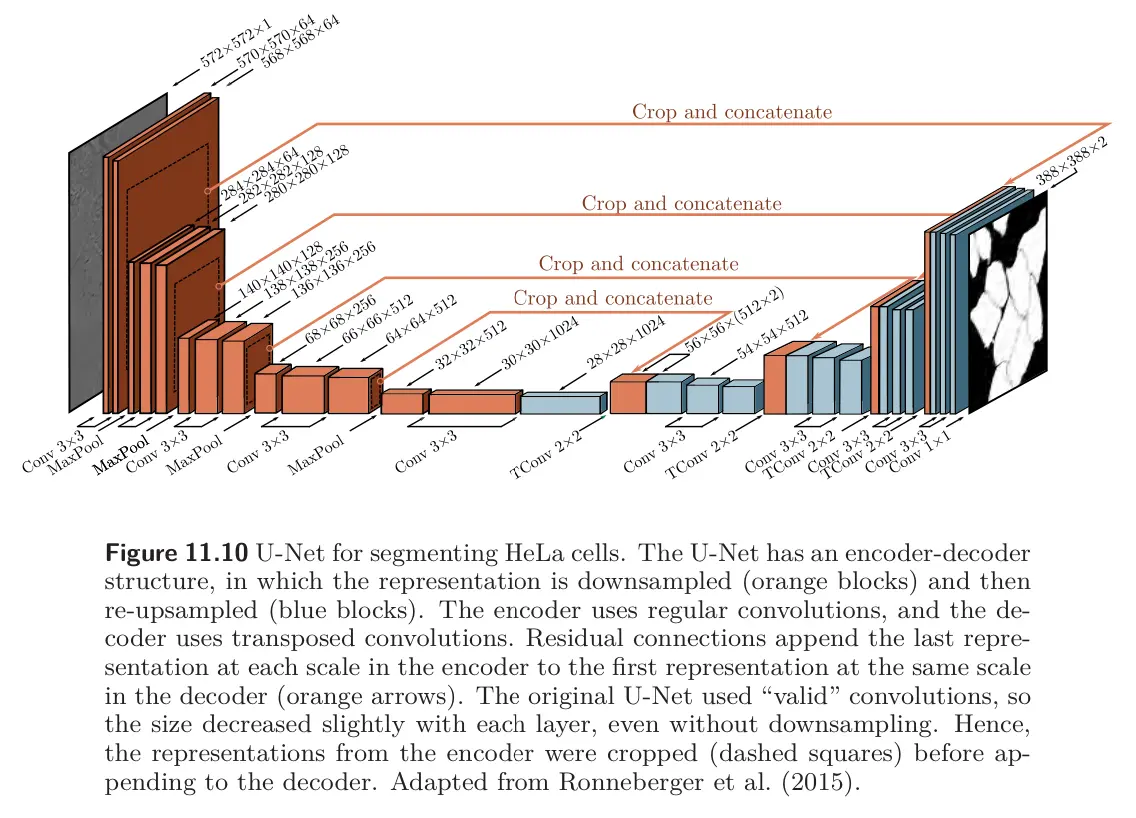
Note that U-Net was completely convolutional, so after training, it can be run on an image of any size.
- Note that we don’t train with arbitrarily sized images. Batch training (especially with batchnorm) wouldn’t be effective; if every image has different dimensions, they cannot be stacked into a single tensor without padding or resizing. Also, GPU memory uses varies with image size so consistent sizing is better for memory use.
dl Why can U-Net be run on images of any size?::It’s completely convolutional, with no FC layers.
U-Net ? Encoder-decoder architecture for segmentation where we concatenate earlier representations with later ones.
+++