Text data processing requires a model that uses parameter sharing to deal with long, variable-length input passages, and contains connections between word representations. The transformer architecture acquires both properties using dot-product self-attention.
Self-Attention & Transformers - CS 224N is a nice self-contained resource other than UDL.
Dot-product self-attention
A self-attention block takes inputs , each of dimension , and returns outputs, each of which is also of size . In the context of NLP, each input might represent a word or word fragment (token).
- Note that the figures here (from UDL) instead assume data of shape . I decided to use row vectors because that formulation is a bit more common.
First, a set of values are computed for each input with a standard linear transformation:
Then, the -th output, , is a weighted sum of all the values :
The scalar weight is the attention that the -th output pays to input . The weights are non-negative and sum to one. Thus, self-attention can be thought of as routing the values in different proportions to create each output.

Computing values
The same weights and biases are applied to each input . This computation scales linearly with the sequence (we just do the calculation once for each element in the sequence). Thus, this needs fewer parameters than a fully-connected layer relating all inputs to all values. We can view the value computation as a sparse matrix operation with shared parameters that relates these quantities.
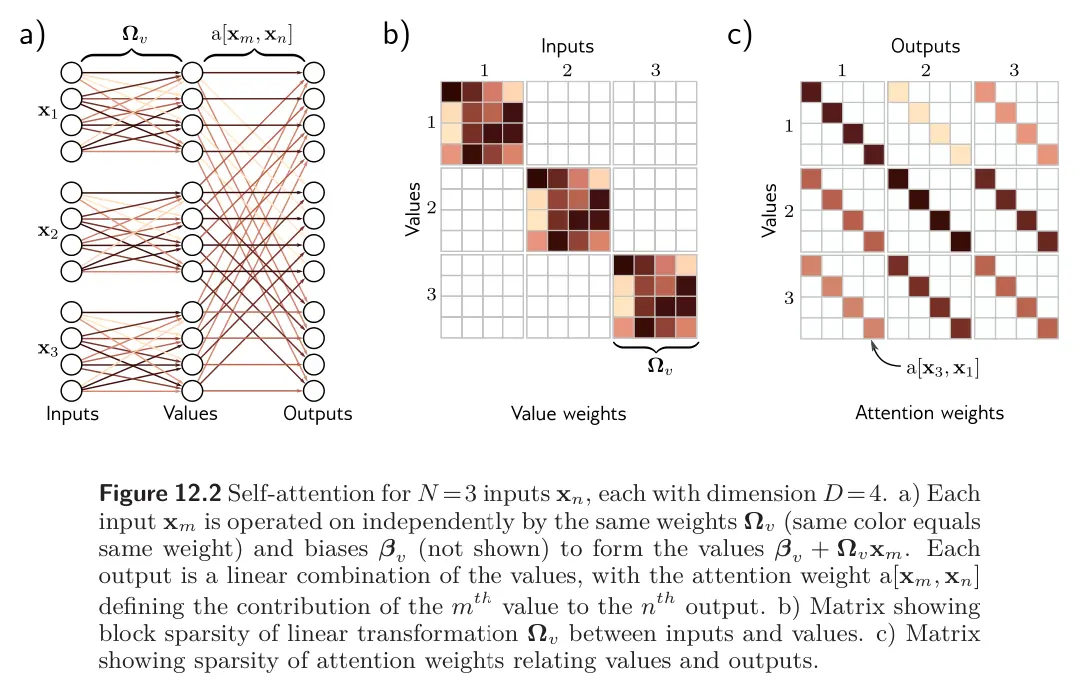
Weighting values
The attention weights combine the values from different inputs. They are also sparse, since there is only one weight for each ordered pair of inputs , regardless of the size of these inputs (see Figure 12.2c).
The number of attention weights has a quadratic dependence on the sequence length , but is independent of the length of each input.
Computing attention weights with queries and keys
The outputs results from two chained linear transformations: the value vectors are computed independently for each input , and then combined linearly by attention weights . However, the overall self-attention computation is nonlinear as the attention weights are nonlinear functions of the input.
- This is an example of a hypernetwork
To compute the attention, we apply two more linear transformations to the inputs:
where and are called queries and keys.
Then, we compute dot products between the queries and keys and pass the results through a softmax function:
Thus, for each , they are positive and sum to one. This is called dot-product self attention.
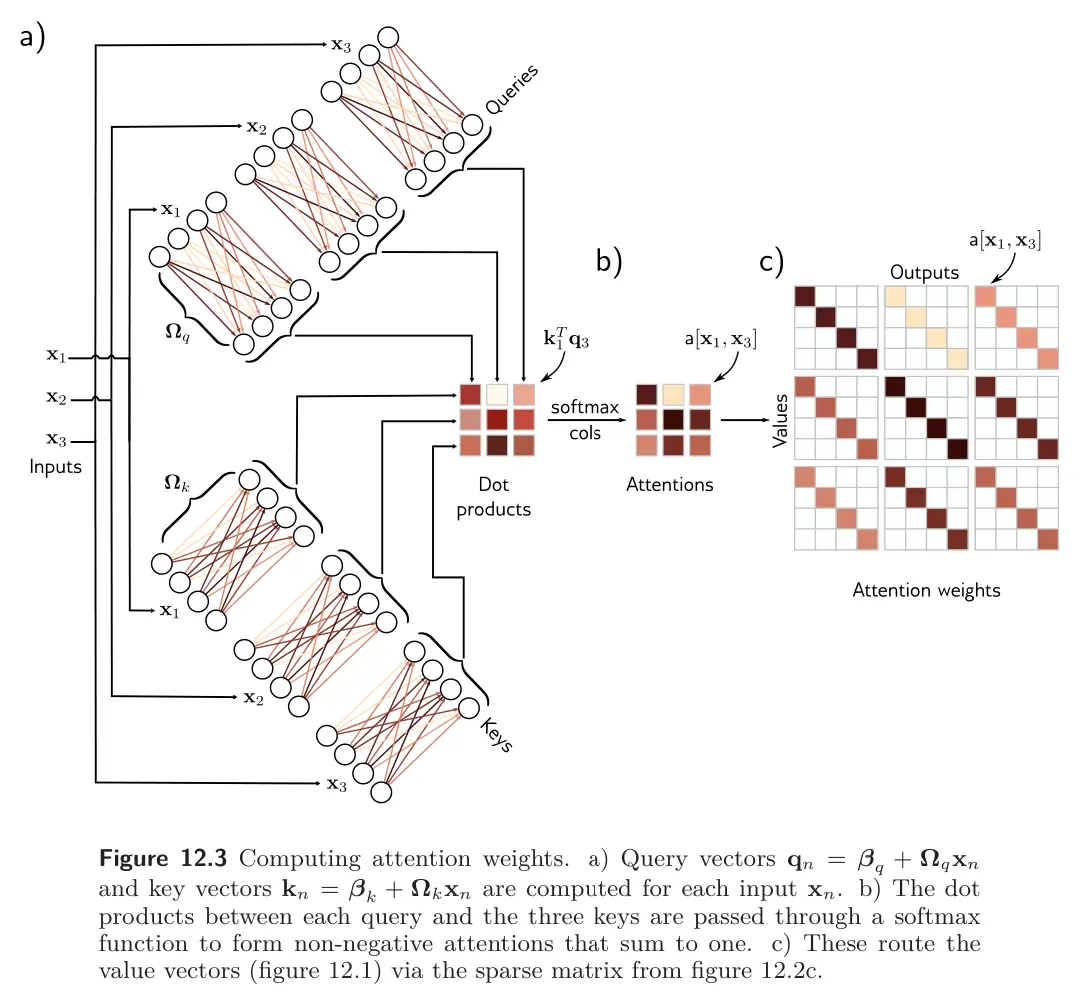
The dot product returns a measure of similarity between its inputs, so the weights depend on the relative similarities between the -th query and all of the keys. The softmax function means that the key vectors “compete” against each other to contribute to the final result.
Properties
Thus, we have seen that the dot-product self-attention mechanism has the properties desired to effectively deal with text data. It has a single shared set of parameters . This is independent of the number of inputs , so the network can be applied to different sequence lengths. Second, there are connections between the inputs, and the strength of these connections depends on the inputs themselves via the attention weights.
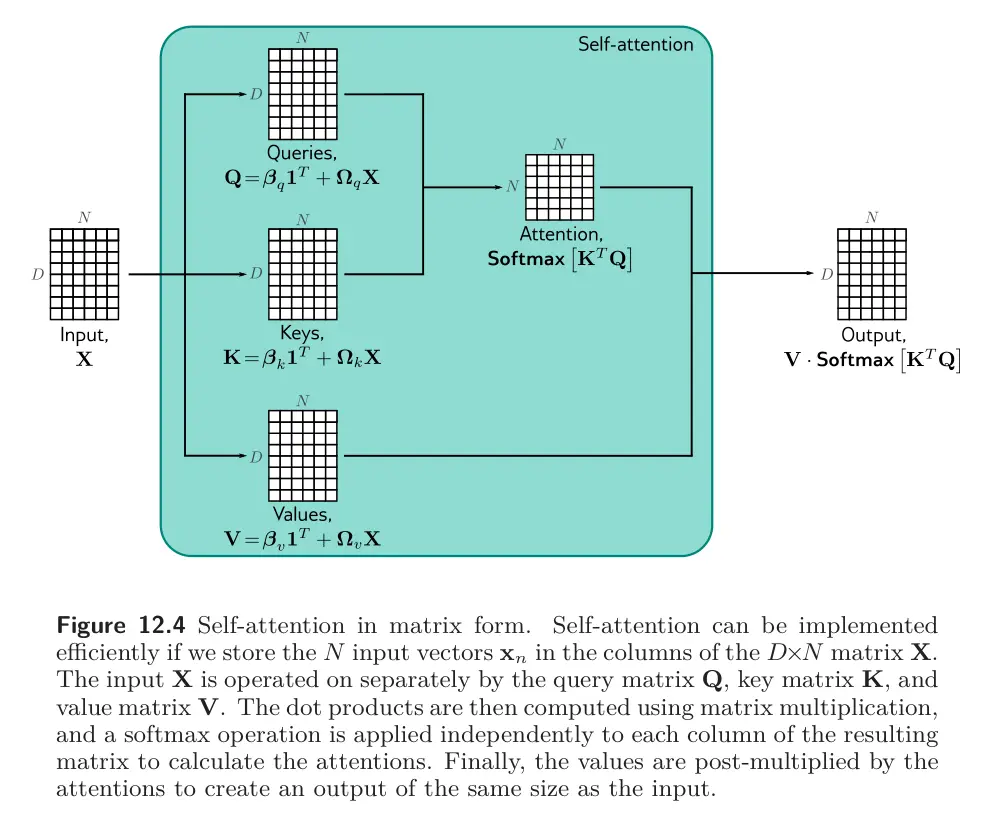
Matrix form
The above computation can be written in a compact form if the inputs are stacked to form the rows of the matrix . (Each input is a row vector with feature dimension , and our sequence length is ).
Then, the values, queries, and keys can be computed as:
where is an vector containing ones. The shape for the above is:
The self-attention computation is then:
where the function takes a matrix and performs the softmax operation independently on each of its rows. We can clean this up by just writing:
The shape is:
Scaled Dot-Product Self-Attention
The dot products in the attention computation can have large magnitudes. Then, and the arguments to the softmax function might be in a region where the largest value completely dominates. Small changes to the inputs to the softmax function now have little effect on the output (the gradients are very small), making the model difficult to train. To prevent this, the dot products are scaled by the square root of the dimension of the keys and queries (the number of columns in and , which must be the same):
dl How does the number of attention weights depend on the sequence length ?::Quadratically. Each of the query vectors attends to all key vectors, producing an attention matrix.
How does the number of attention weights depend on the input dimension ?::No dependence
What are the numerical properties of attention weights?::They are non-negative and sum to 1 because of softmax.
Why is self-attention non-linear even with no activation function?::Dot-product and softmax
In dot-product self-attention, how is parameter sharing done?::To calculate queries, keys, and values, the same three projection matrices () and three bias vectors () are applied to every input. As a result, the parameter count is independent of the number of inputs .
Scaled dot-product self-attention formula::