Shallow Networks
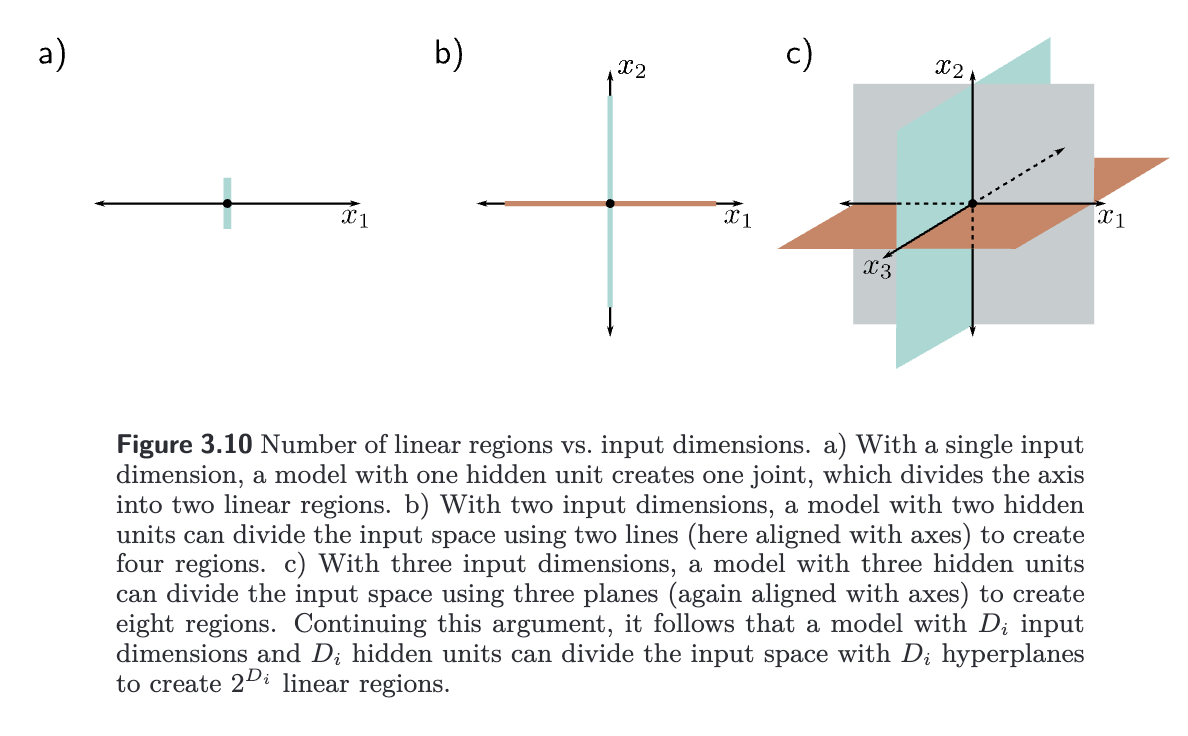
In a shallow network, as the input dimensions grow, the number of linear regions increases rapidly. Each hidden unit defines a hyperplane ( dimensional plane) that delineates the part of the space where this unit is active from the part it is not. If we had the same number of hidden units as input dimensions , we could align each hyperplane with one of the coordinate axes. For two input dimensions, this would divide the space into four quadrants. For three dimensions, this would create eight octants, and for dimensions, this would create orthants. hallow neural networks usually have more hidden units than input dimensions, so they typically create more than linear regions.
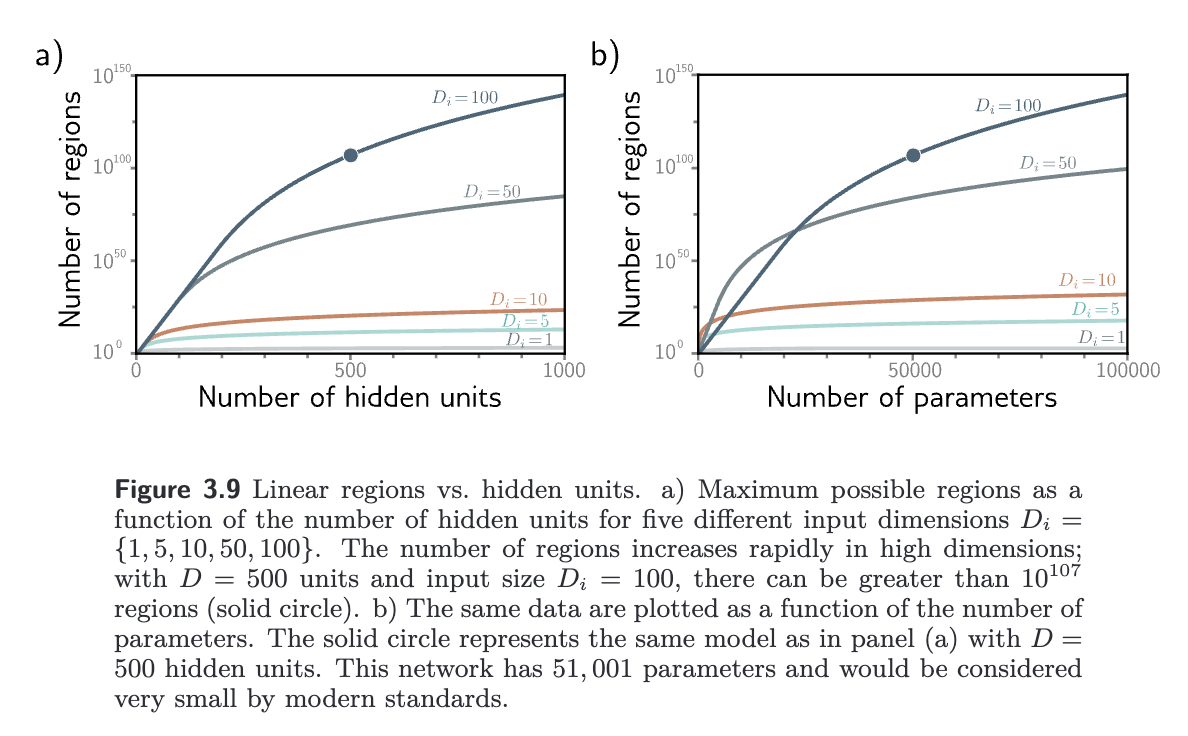
Zavslavsky’s formula: The number of regions created by hyperplanes in the -dimensional input space is at most
which is a sum of binomial coefficients.
As a rule of thumb, shallow neural networks almost always have a larger number of hidden units than input dimensions and create between and linear regions.
Deep Networks
A shallow network with one input, one output, and hidden units can create up to linear regions and is defined by