Neither gradient descent nor stochastic gradient descent moves neutrally to the minimum of the loss function; each exhibits a preference for some solutions over others. This is known as implicit regularization.
Implicit regularization in gradient descent
Consider a continuous version of gradient descent where the step size is infinitesimal. The change in parameters would be governed by the differential equation:
Gradient descent approximates this process with a series of discrete steps of size :
This discretization causes a deviation from the continuous path.
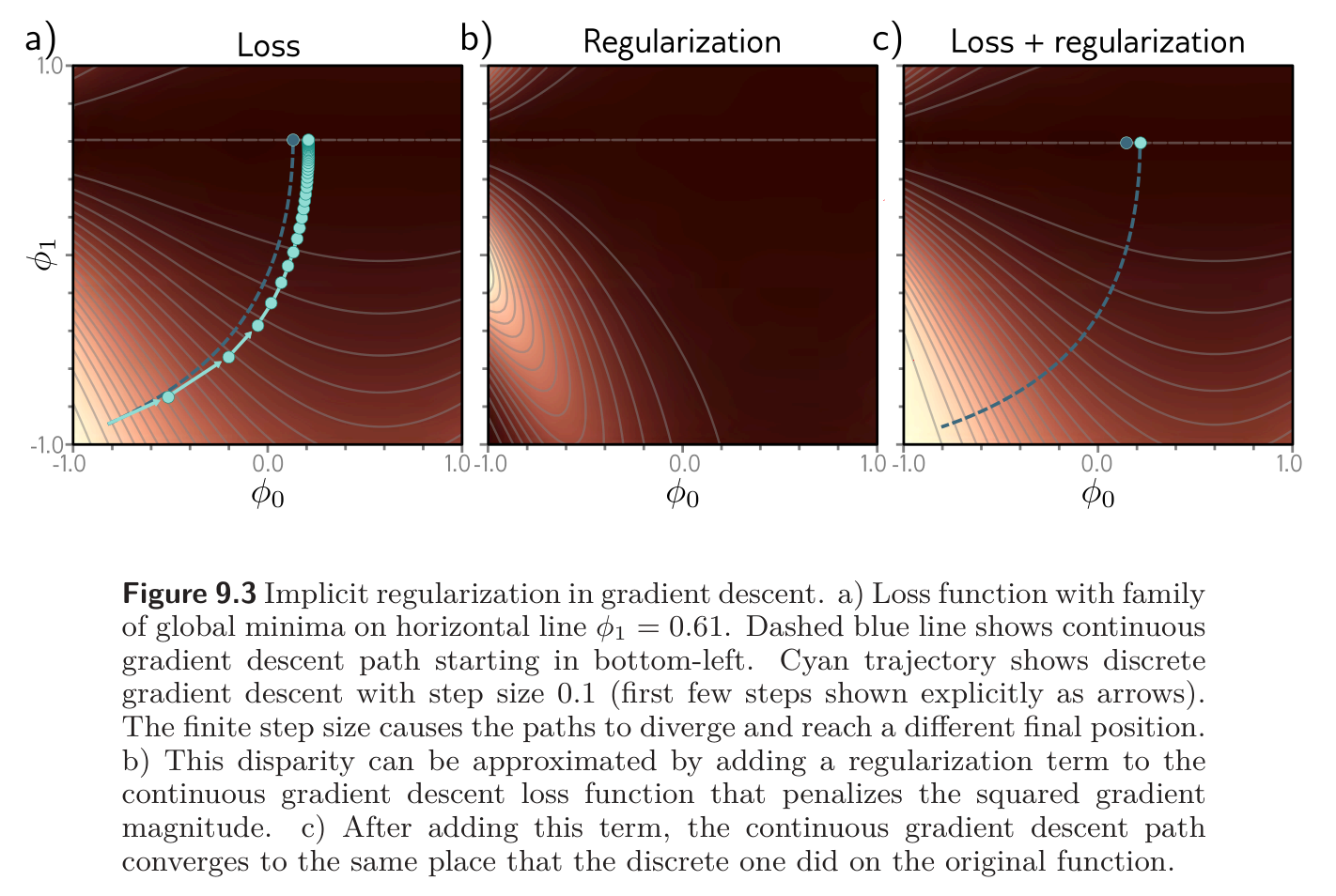
This deviation can be understood by deriving a modified loss term for the continuous case that arrives at the same places as the discretized version on the original loss . It can be shown that this modified loss is
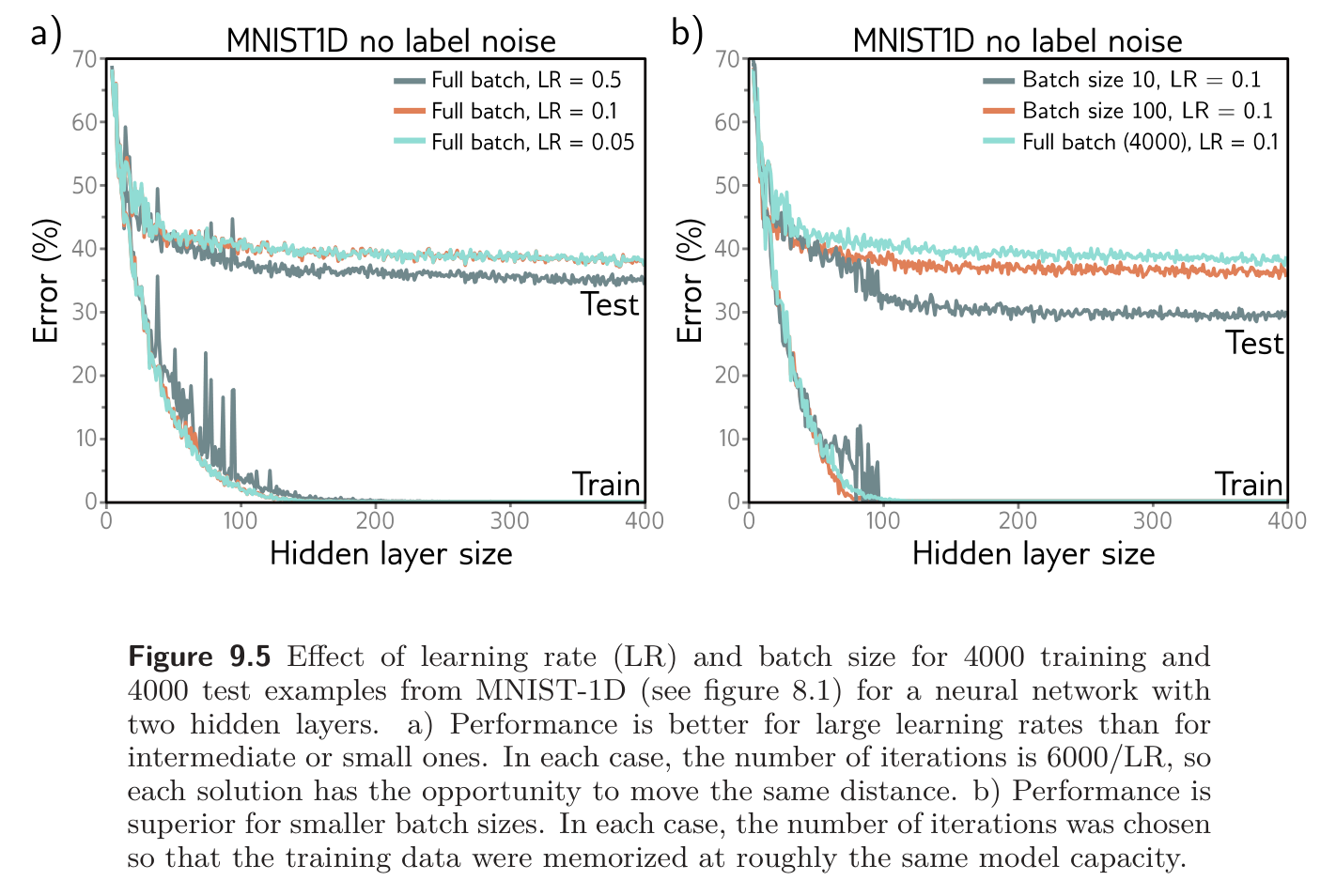
In other words, the discrete trajectory is repelled from places where the gradient norm is large (the surface is steep). This doesn’t change the position of the minima, where the gradients are zero anyway. However, it changes the effective loss function elsewhere and modifies the optimization trajectory, which potentially converges to a different minimum. Implicit regularization due to gradient descent may be responsible for the observation that full batch gradient descent generalizes better with larger step sizes (see fig 9.5a).
Implicit regularization in SGD
A similar analysis can be applied to SGD; now we seek a modified loss function such that the continuous version reaches the same places as the average of the possible random SGD updates. This can be shown to be:
Here, is the loss for the -th of the batches in an epoch. Specifically, now represents the means of the individual losses in the full dataset, while represents the mean of the individual losses in a batch:
Our equation above for revealed an extra regularization term corresponding to the variance of the gradients of the batch losses . In other words, SGD implicitly favors places where the gradients are stable (all the batches agree on the slope). This modifies the trajectory of the optimization process but does not necessarily change the position of the global minimum; if the model is over-parameterized, then it may fit all the training data exactly, so each of these gradient terms will be zero at the global minimum.
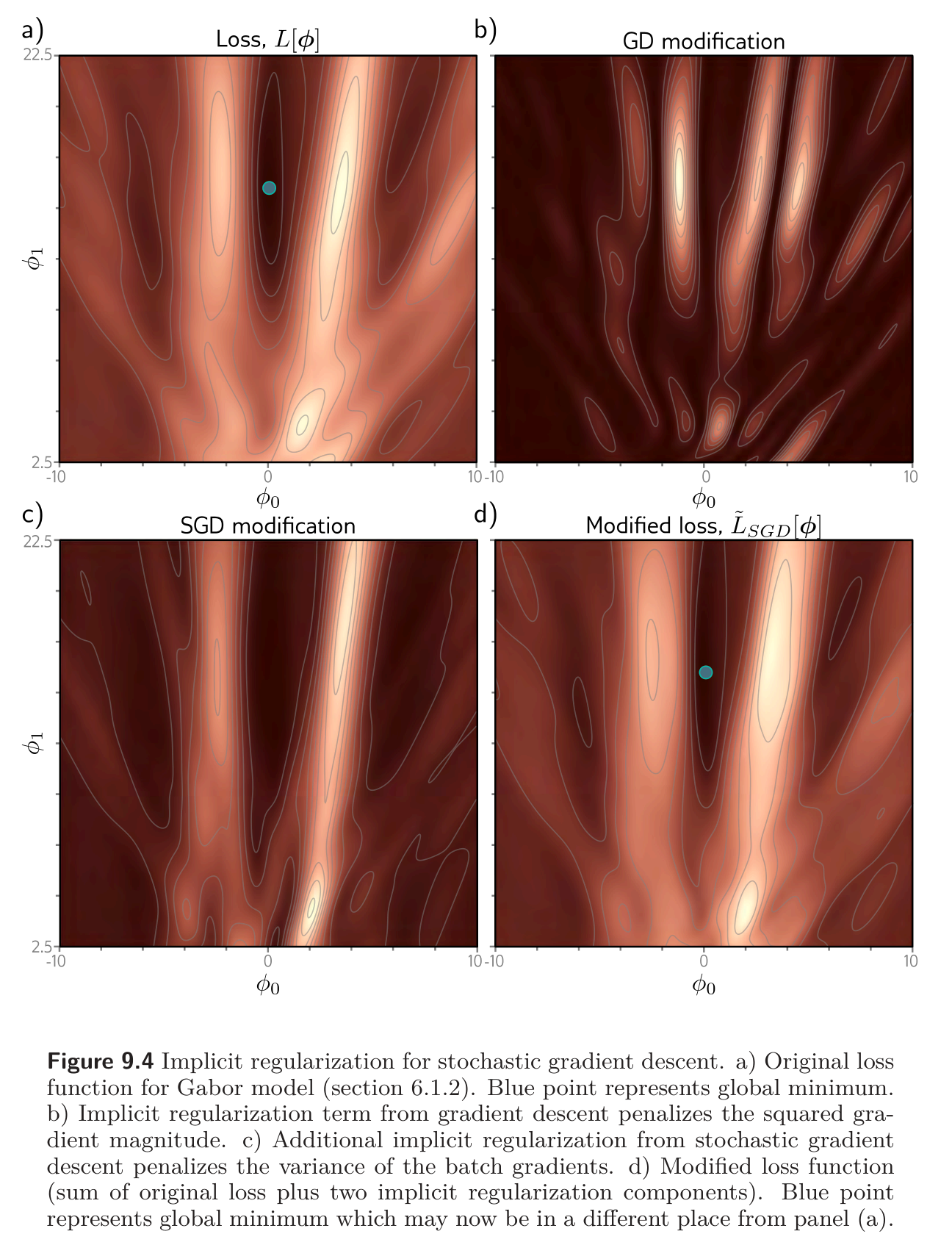
SGD generalizes better than gradient descent, and smaller batch sizes generally perform better than larger ones. One possible explanation is that the inherent randomness allows the algorithm to reached different parts of the loss function. However, it’s also possible that some or all of this performance increase is due to implicit regularization, as it encourages solutions where all the data fits well (so the batch variance is small) rather than solutions where some of the data fits extremely well and other data less well (perhaps with same overall loss but larger batch variance). The former solutions are likely to generalize better.