Hinge loss is defined as:
where is the label of a data point and is the raw prediction made by classifier .
It is also written as:
where is the ground truth and is the prediction given by the model.
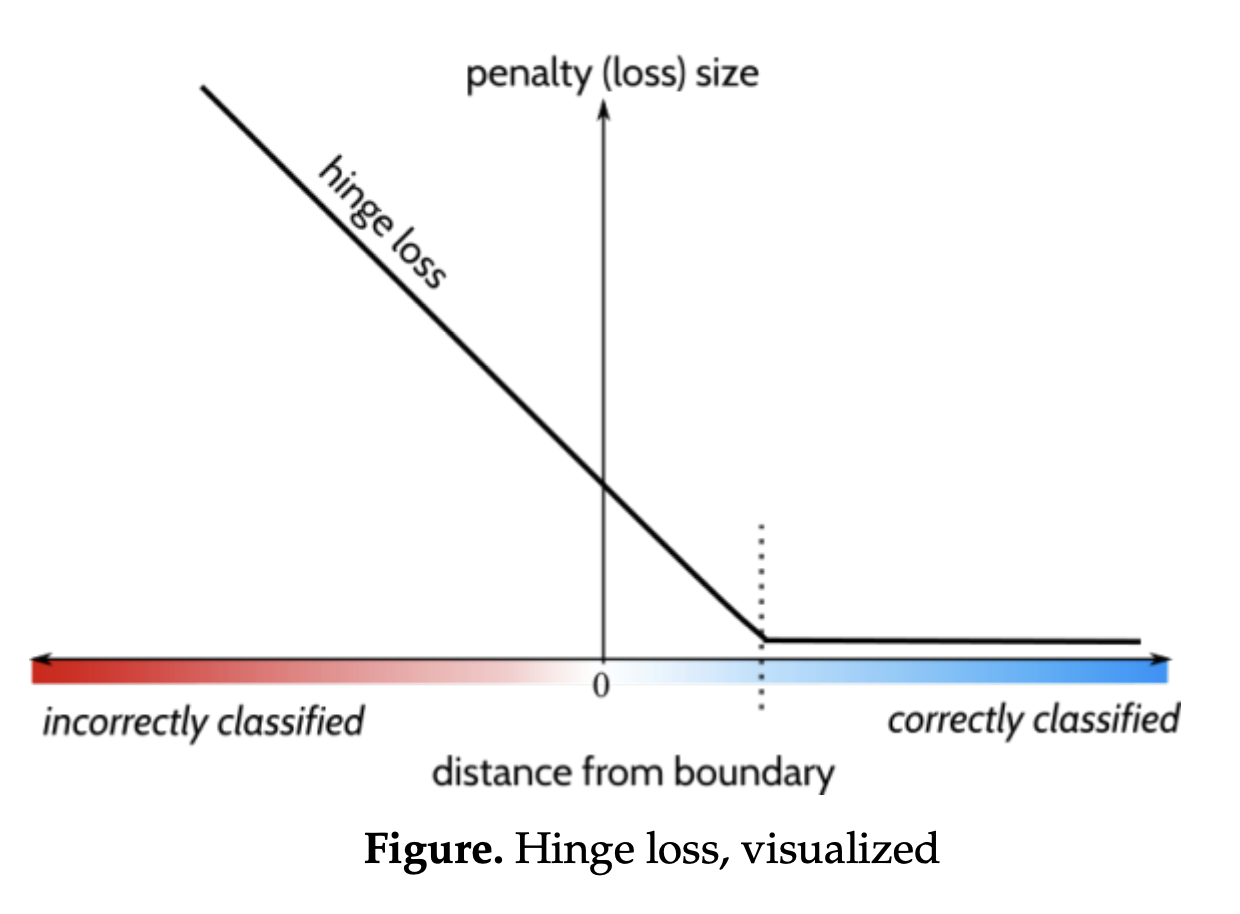
Intuition:
- If is large and positive, the prediction is very confident and correct ( and have the same sign). This means that will be negative; since the maximum of hinge loss is zero, the loss for this sample will be .
- If is positive but less than one, it means that the prediction is correct but the confidence is not high. This is penalized linearly; smaller values of get penalized more by .
- If is zero or negative, it means that the prediction is incorrect (or exactly on the decision boundary). The model is penalized linearly the more it is on the wrong side.
As such, hinge loss is essentially trying to ensure that the sign of the prediction is right (correct classification) and maximize confidence about possible predictions. Hinge loss is commonly used for Support Vector Machine training.