The basic element of a neural network is called a neuron. This is also sometimes called a Perceptron but I prefer to use perceptron to refer to the learning algorithm; it is also referred to as “unit” or “node”.
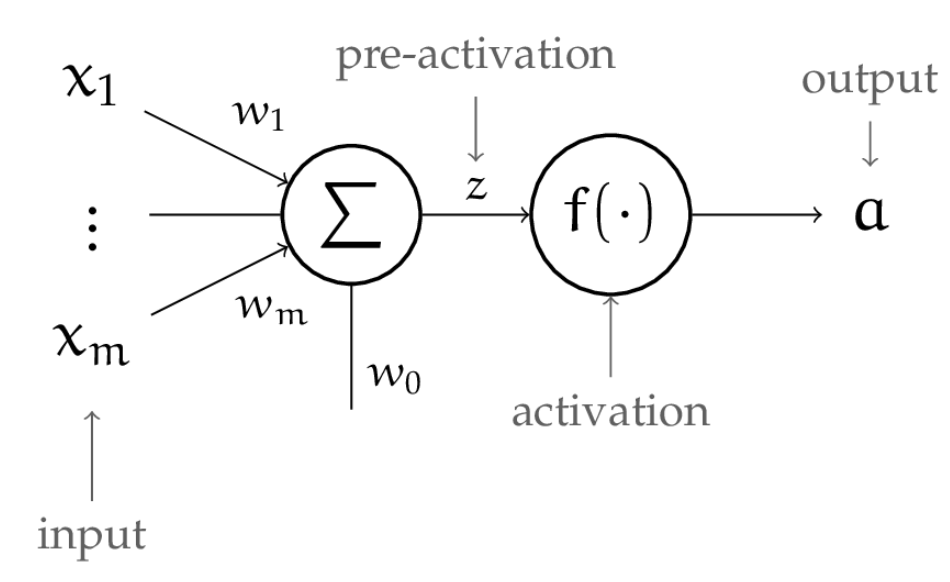
The neuron is essentially a non-linear function of an input vector to a single value . It is parametrized by:
- A vector of weights and an offset/threshold .
- An activation function , which gives us non-linearity.
In total, the function represented by the neuron can be summarized as:
- The final formulation is basically just the activation function applied to linear classifier.
Training
How do we train a single unit? Given a loss function , and a dataset , we can do gradient descent, adjusting the weights to minimize:
where is the output of our neural net for a given input.
Linear classifiers with hinge loss and regression with quadratic loss, which we’ve studied, are two special cases of the neuron; both of them have an activation function of .