We would like an autoencoder that can generate reasonable samples that were not in the training set.
We want to be able to reconstruct samples in our dataset. In fact, we would like to be able to generate ANY valid sample. In essence, we want to sample the distribution of inputs:
We generate samples by choosing elements from some lower-dimensional latent space:
and then generate the samples from those latent representations.
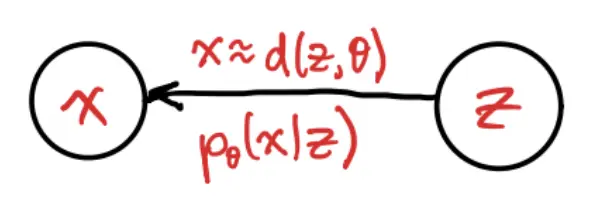
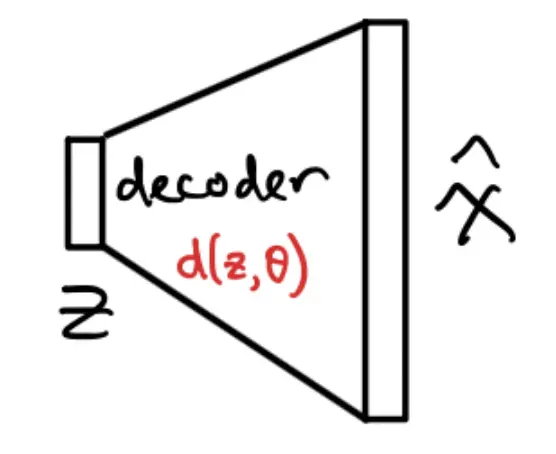
Here we are learning a decoder function to maps the latent to the parameters of a distribution over , .
- For example, if is continuous, the decoder might output a mean and a variance. If is binary, it might output Bernoulli probabilities.
The decoder usually maps to distribution parameters, not directly to a single deterministic . This is because is a random variable, so running it through gives a distribution.

But even for a fixed , we assume that is a distribution:

Given and , we can get as:
How do we define the decoder? We have a dataset of samples, , and we want to find to maximize the likelihood of observing .
Let’s assume that is Gaussian, with mean and some variance . Then:
Thus, given some samples , we have a way to learn to maximize .
We can just solve
Note that
where we can use a Monte Caro method to evaluate the previous integral.
Sampling Latents
Problem: How do we sample ? It’s an arbitrary unknown thing, and could still be fairly high-dimensional, making sampling difficult.
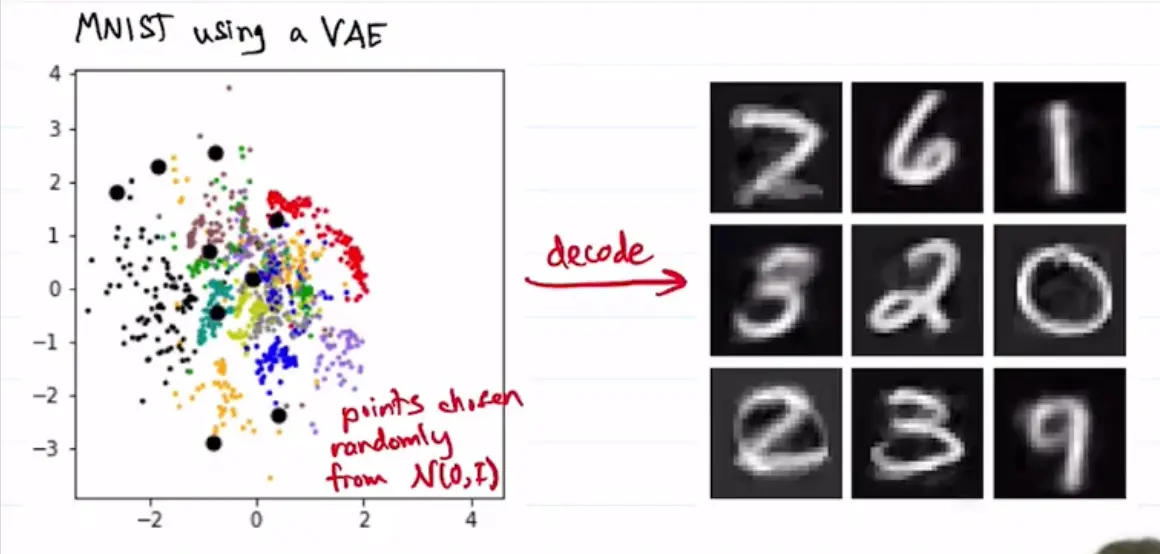
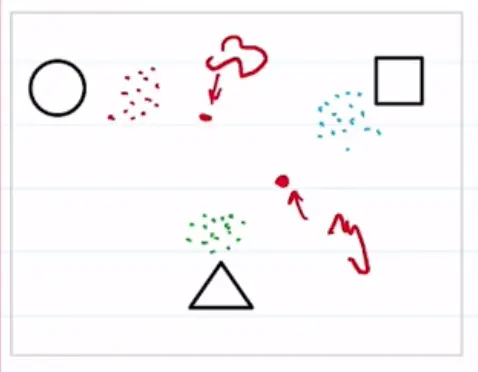
Suppose we train an autoencoder on a dataset of simple shapes. The latent space is 2D, and the clusters are well separated. However, latent vectors between the clusters generate samples that don’t look like our training shapes!
Another example where we are sampling rom MNIST latent space:
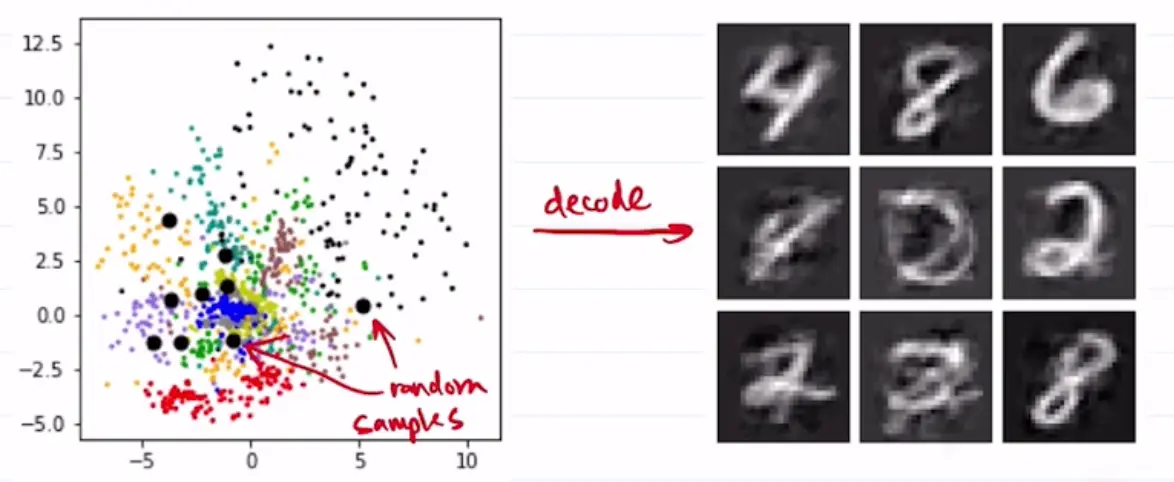
These generations are quite bad! This is because we are choosing improbable samples, such that .
VAE Objective
We would like to sample only that yield reasonable samples with high probability. We want to place requirements on the latent distribution.
Let’s assume that we can choose the distribution of ‘s in the latent space; call it . Then
Essentially we are changing the variable so that instead of using the unknown distribution , we are using our designed distribution .
We can then look to minimize the negative log likelihood:
where we are using the KL divergence.
KL divergence term
Let’s first choose a latent distribution that is convenient for us:
Then, our aim is to design so that it is close to :
How do we design our latent representations to achieve this? We design an encoder, and ask its outputs to be .
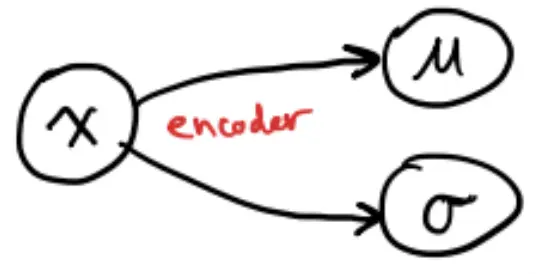
This defines a distribution .
For example, in the case of MNIST:
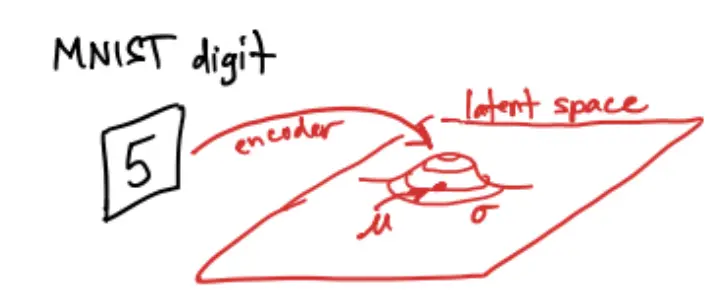
But remember that we want our distribution to be a standard normal distribution , not just any normal distribution ! Thus, we have to pressure our encoder to push and .
We can once again use a KL divergence, which conveniently has a closed-form expression in this case:
So we want to minimize this to push our latent space toward a standard normal distribution. But remember that we have the other term to deal with too!
Reconstruction
The other term in the objective
is our reconstruction loss, and can be written as
where
- and are from the encoder
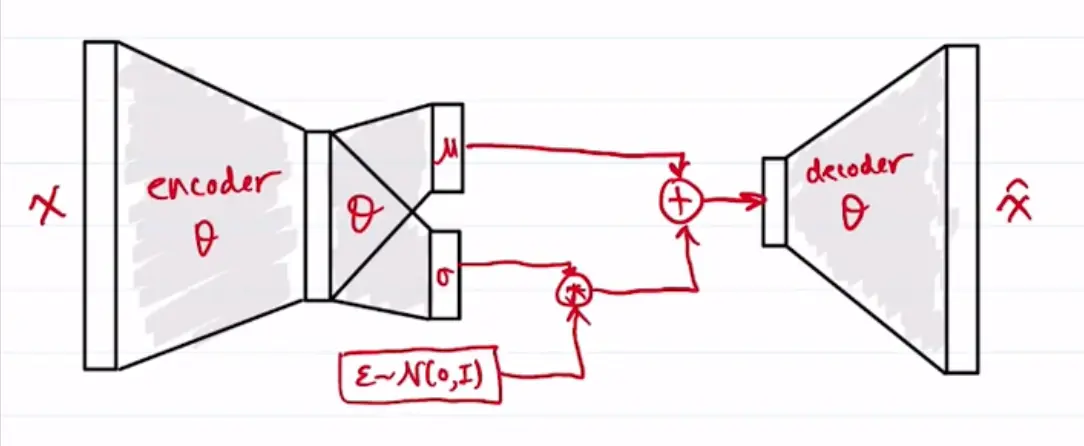
This is the “reparameterization trick”, where the distribution is differentiable because the rest of the network is deterministic, and stochasticity is brought in by the variable. and are deterministic.a
Intuition
Think of a cloud of matter floating ins pace, but collapsing in by its own gravity, eventually forming a star.

Here is the process:
- Encode by computing and using neural networks.
- Sample .
- Calculate KL loss:
- Decode using another neural network:
- Calculate reconstruction loss, for Gaussian or for Bernoulli.
Both terms of our objective function are differential w.r.t .
so we can do gradient descent on . adjusts the relative importance of reconstruction loss vs. KL divergence loss.
With this setup, there are no (or fewer) gaps in the latent space, which enhances the quality of samples generated by the VAE.