How do we systematically decode, encode, and transform data stored in the activity of a population of neurons? If we know what processing we want done, how do we design a network to do it effectively? Can we build a compiler to implement a program on a neural machine?
Intuition
Population coding is the idea that the input is represented not by a single neuron, but by the pattern of activations across a population of neurons in a hidden layer. Once the input is encoded in that distributed activity, we can decode the population to approximately recover the original input or to compute some transformed quantity from those hidden activations.
Like for any machine, we will add a hardware abstraction layer between our data processing and the hardware. This approach will allow us to focus on the data that we are encoding, and the transformation applied to that data.

We can build a neural network that processes our data by putting together a bunch of regression layers.
The first step is to encode data into the collective activity of a population of neurons.
Consider this simple regression network with an imaginary “linear readout” node, connected to all the neurons in the hidden layer.
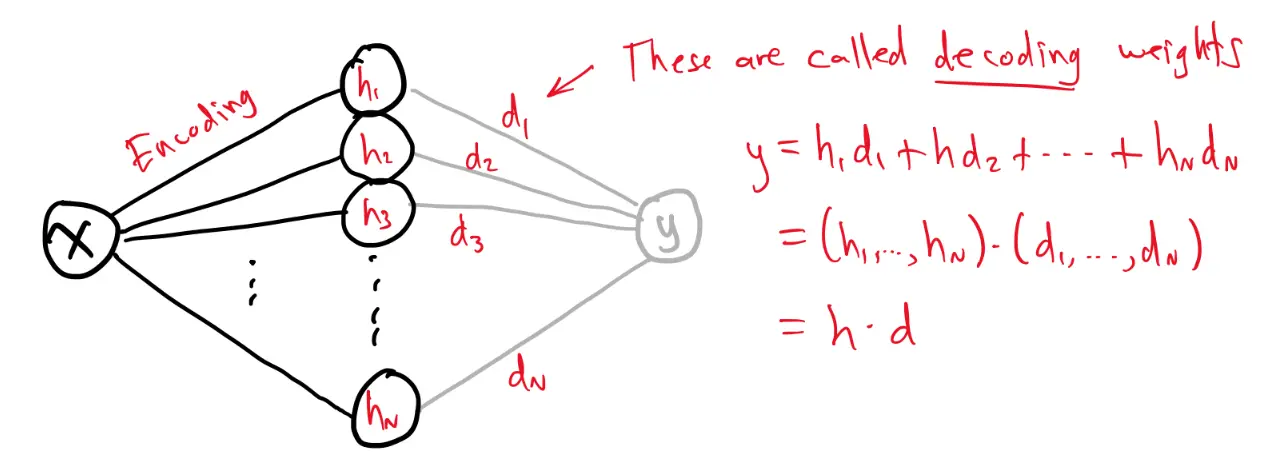
We call decoding weights. The output is computed as
Suppose we want our imaginary readout node to approximate for a range of possible input values. This is essentially a regression problem, but we will only consider changing the decoding weights, and leave the encoding weights alone.
Since we know what function we want our network to compute, we can create our own training dataset.
- Choose a bunch of values,
- Generate samples of the form: Input = , Target = , like an autoencoder
Then we could learn the decoding weights, such that the output is:
by minimizing the loss:
Since it’s a regression problem, we can use a MSE loss. We could then train the decoding weights using backprop. However, if we look at the optimization problem:
This can be rewritten as:
where
H = \begin{bmatrix} h^{(1)} \\ \vdots \\ h^{(P)} \end{bmatrix} $$holds the activities of the hidden population, with each row corresponding to one input sample. ## Optimal Linear Decoding Given a set of $P$ inputs stored in $X$ and corresponding encoding activations inH = \begin{bmatrix} h^{(1)} \ \vdots \ h^{(P)} \end{bmatrix} \quad \quad \text{(e.g. firing rates)}
the optimal linear decoding weights $d^{\ast }$ solved^{\ast } = \underset{d}{\operatorname{argmin}} || Hd - X ||_{2}^{2}
d^{\ast }= (H^{T}H)^{-1}H^{T}X
- This is essentially just [[Ordinary Least Squares|OLS]]? ## Encoding and Decoding Vectors We can encode and decode vectors as well. ![[Population Coding-1775345182440.webp|325]] For example, suppose an input vector $(x_{1}, x_{2})$ is encoded by a hidden layer $h=\sigma([x_{1},x_{2}]E+b)$. Now we just have to find 2 different sets of decoding weights, one for each output:D^{\ast } = \underset{D}{\operatorname{argmin}} || HD-X ||_{F}^{2}
where we are using the [[Frobenius Norm]]. Note that $D^{\ast }$ has 2 columns, one for each output node. Finally, we can decode *nonlinear* functions of the values encoded. For example, suppose a population of neurons is encoding $(x_{1}, x_{2})$, we could decode $t(x_{1},x_{2})=x_{1}\sin x_{2}$. All we have to do is solve another least squares problem with a new target matrix $T$. Let:T = \begin{bmatrix} x_{1}^{(1)} & x_{2}^{(1)} \ x_{1}^{(2)} & x_{2}^{(2)} \ \vdots & \vdots \ x_{1}^{(P)} & x_{2}^{(P)} \end{bmatrix} \quad \text{and} \quad D^{\ast } = \underset{D}{\operatorname{argmin}} || HD-T ||_{F}^{2}
So long as an error (target) can be specified, the decoding weights can be learned. ## Solving the Normal Equations What if $H^{T}H$ is (almost) singular? The usual solution is:d^{\ast } = (H^{T}H)^{-1} H^{T}X
but this can be problematic if $H^{T}H$ is poorly conditioned. If there is noise in $H$, say $H+\epsilon$,\begin{align} || (H+\epsilon)D -T ||{2}^{2 } & = || HD-T+\epsilon D ||{2}^{2} \ & = [(HD-T)+\epsilon D]^{T}[(HD-T)+\epsilon D] \ & = (HD-T)^{T}(HD-T) + \cancelto{ 0 }{ 2(HD-T)\epsilon D }+ D^{T}\underbrace{ \epsilon^{T}\epsilon }_{ \sigma^{2}I } D \ & = || HD-T ||^{2}+\sigma^{2}|| D ||^{2} \end{align}