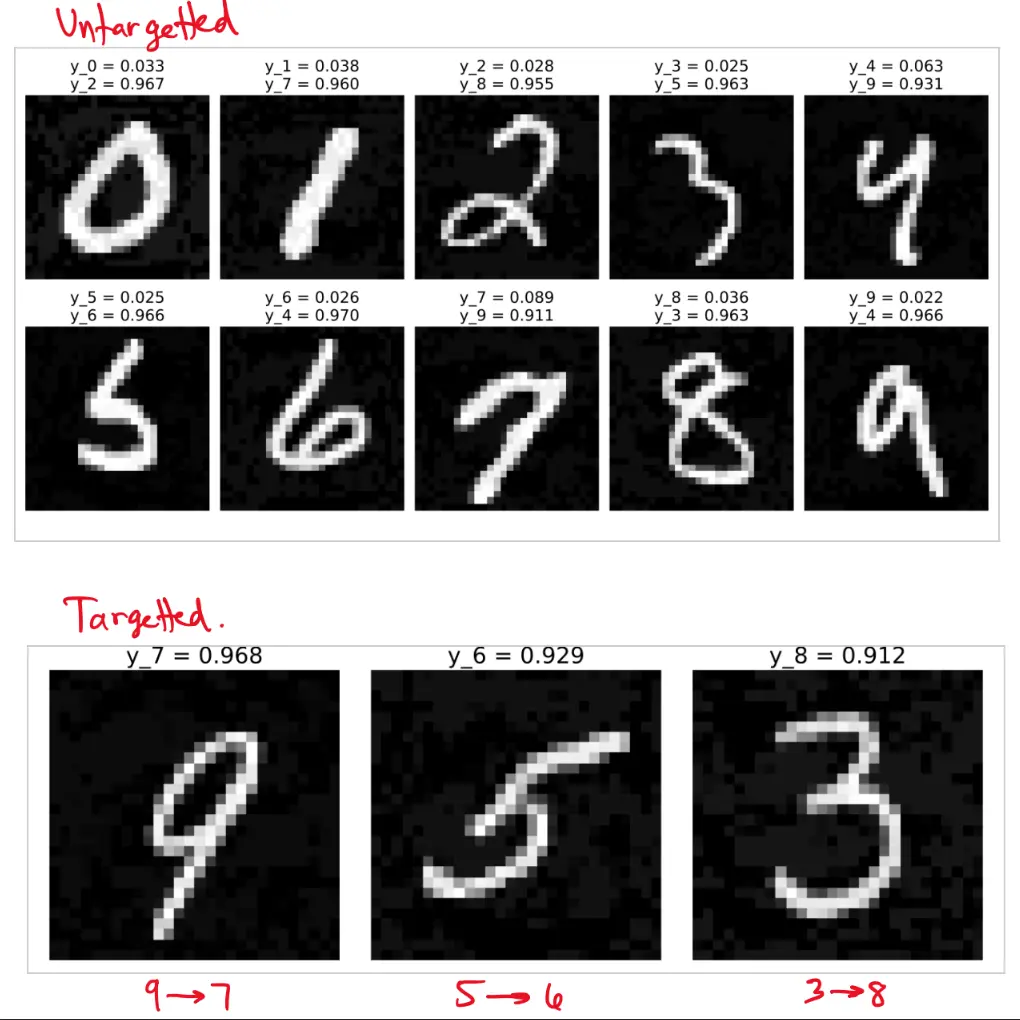
We can easily fool a classify network into misclassifying an input.
Suppose we are given a dataset.
for , where the class of is .
Let be a classifier network, where
represents probability vectors, such as those produced by a softmax function.
The classification error is defined as:
where:
- counts the number of occurrences
- gives the index of the largest element of
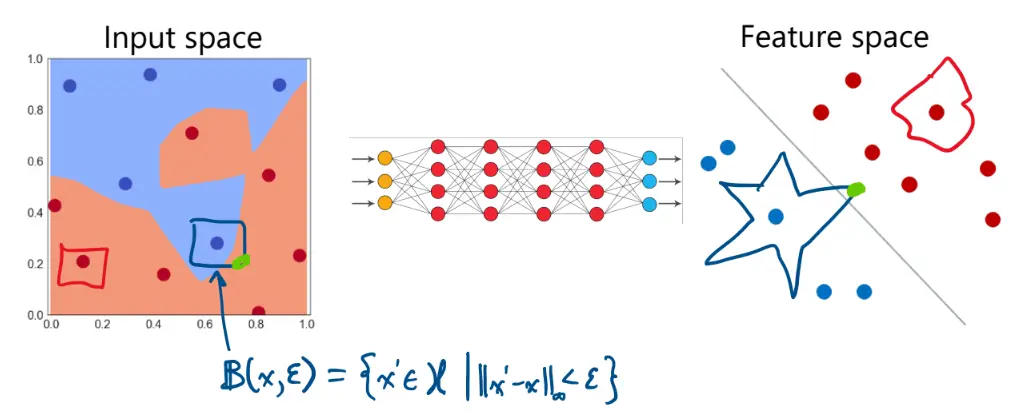
Let’s define the -ball (neighborhood) of an input as:
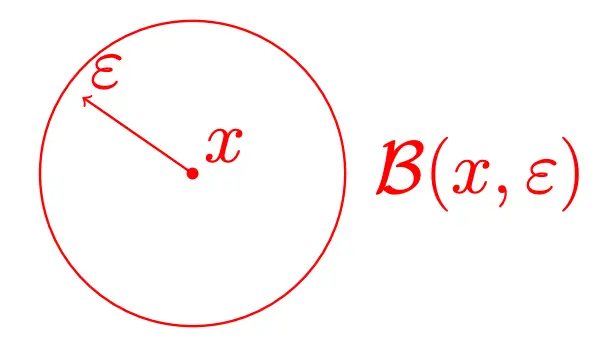
We ask ourselves, given an , is there such that
In other words, is there a very nearby input that would fool the network and yield an incorrect classification?
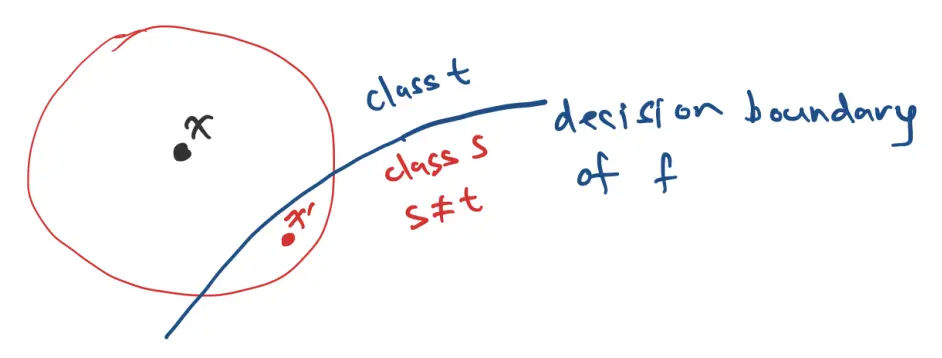
These can actually be found quite easily. This is called an adversarial attack. There are two main classes of adversarial attacks:
- Whitebox: Attacker has access to the whole model, e.g., weights, activations, etc.
- Blackbox: Attacker only has access to inputs and outputs
Gradient-Based Whitebox Attack
This is a common whitebox attack method. Recall that learning is done by gradient descent:
where is our loss function. Using backpropagation, we propagate the gradient of the cost function down through the layers of the network:
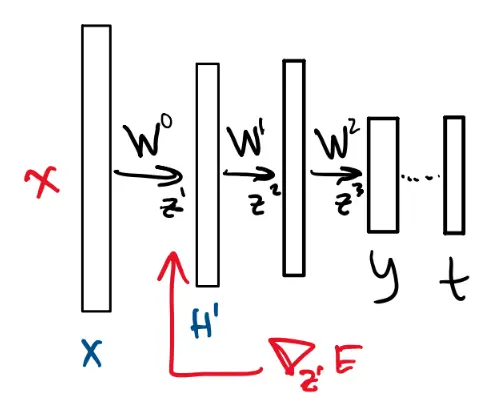
We can calculate using :
This gives us the gradient of the loss with respect to the input, telling us how to adjust out input in order to decrease (or increase) the loss.
Untargeted attack:
This is essentially gradient ascent, pushing image in a direction to increase loss.
Targeted attack:
where . This is gradient descent nudging the input to decrease loss for the wrong target class.
For example, a change in pixel intensity of in an 8-bit image is imperceptible to the human eye. If we want to perturb our image by for each pixel, then we let the perturbation be:
such that . This means that .
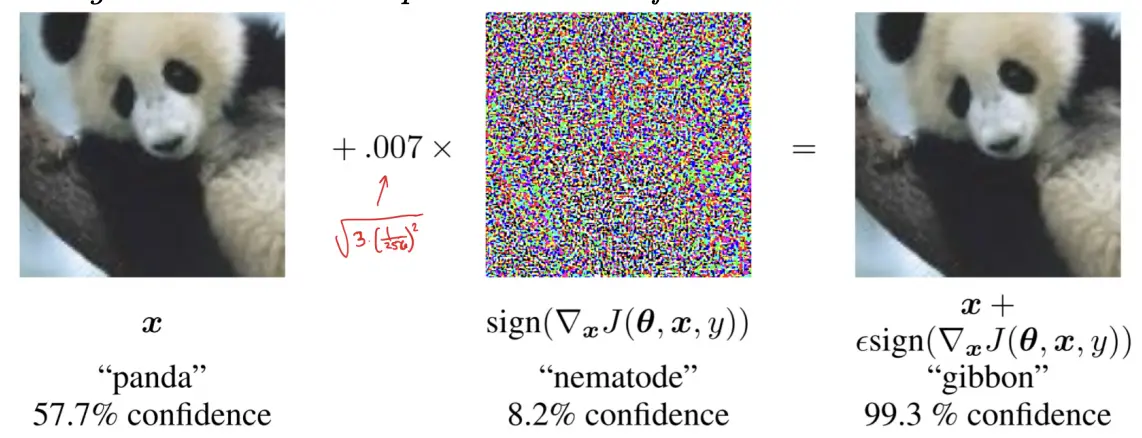
The more general version of this is FGSM:
Fast Gradient Sign Method
FGSM adjusts each pixel by , such that .
For example, for a 24-bit image where , the perturbed image is computed as:
which ensures that the perturbation follows .
Instead of applying a fixed perturbation, one can also search for the smallest that causes misclassification:
Intuition
Why are classification networks so easily fooled?
Consider the input space of for MNIST, such that there are total dimensions. That’s a lot of space. The classification partitions this high-dimensional space into 10 regions, one for each class.
It turns out that most points are not too far away from a decision boundary.
Learning is:
Untargeted attack:
Targeted attack: