A particle filter represents a probability distribution with a large number of “particles” (samples). This is helpful for random variables whose pdf is unknown, so instead we draw samples.
Consider samples of the posterior :
where each particle is a hypothesis about where the robot might be. If many particles cluster in one region, that region has high probability. If few particles appear in a region, that region has low probability.
Particle Filter Localization
We start with the previous belief distribution represented by particles:
We apply the sample motion model to each particle to generate prediction samples to get
We then do a measurement step by taking the the measurement from a (Lidar) sensor and evaluating each sample according to the sensor model:
where is an importance weight. This evaluates how well each particle explains the actual measurement according to the sensor.
We would then draw new samples according to importance weight to get the next estimate . This is called Importance Re-sampling with Replacement.
Importance Re-sampling
After the motion update, our particles represent the prediction distribution, . After doing the measurement update with importance weights, our weights tell us how well each particle explains the LiDAR scan. But now, our set of particles does not match the true posterior distribution . Instead, we have samples from with weights that reflect how they should be redistributed.
Looking at the update rule:
This tell us how to convert samples from into samples from .
Thus, if we resample the particles of according to the distribution of , we should be able to recover the distribution of . Importance sampling is “resampling with replacement”; we do not change any particle’s value, we only change how frequently each one appears in the new set.
- Particles with high weight are selected many times
- Particles with low weight may disappear entirely
After this resampling, we get:
where the distribution of particles now approximates .
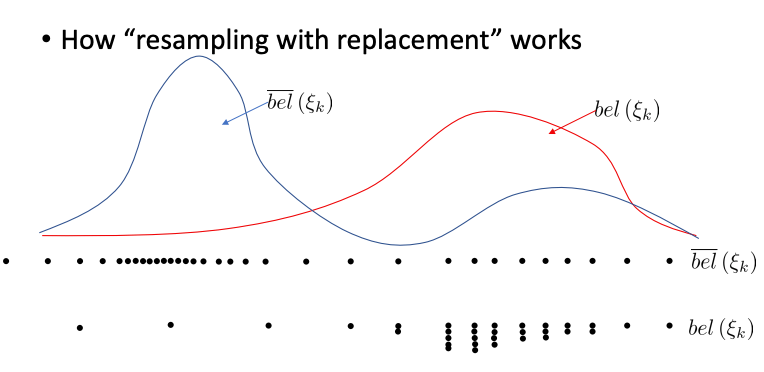
- Blue curve: Predicted distribution before sensor update
- Red curve: Correct posterior after sensor update
Before resampling, the particles are spread out according to the blue curve; each particle gets a weight based on sensor likelihood. After resampling, p.articles cluster according to the red curve. Instead of explicitly shifting particles, we replicate good ones and delete bad ones.