However, the approximate model below tells us a lot about the things we have to consider when situating a process in memory. You may also notice that the figure does not include the .bss segment. This is because where the .bss variables go is up to the implementation, but how they are used is not. Sicne .bss variables are treated just like the variables in the .data segment, the two segments are merged in the image.
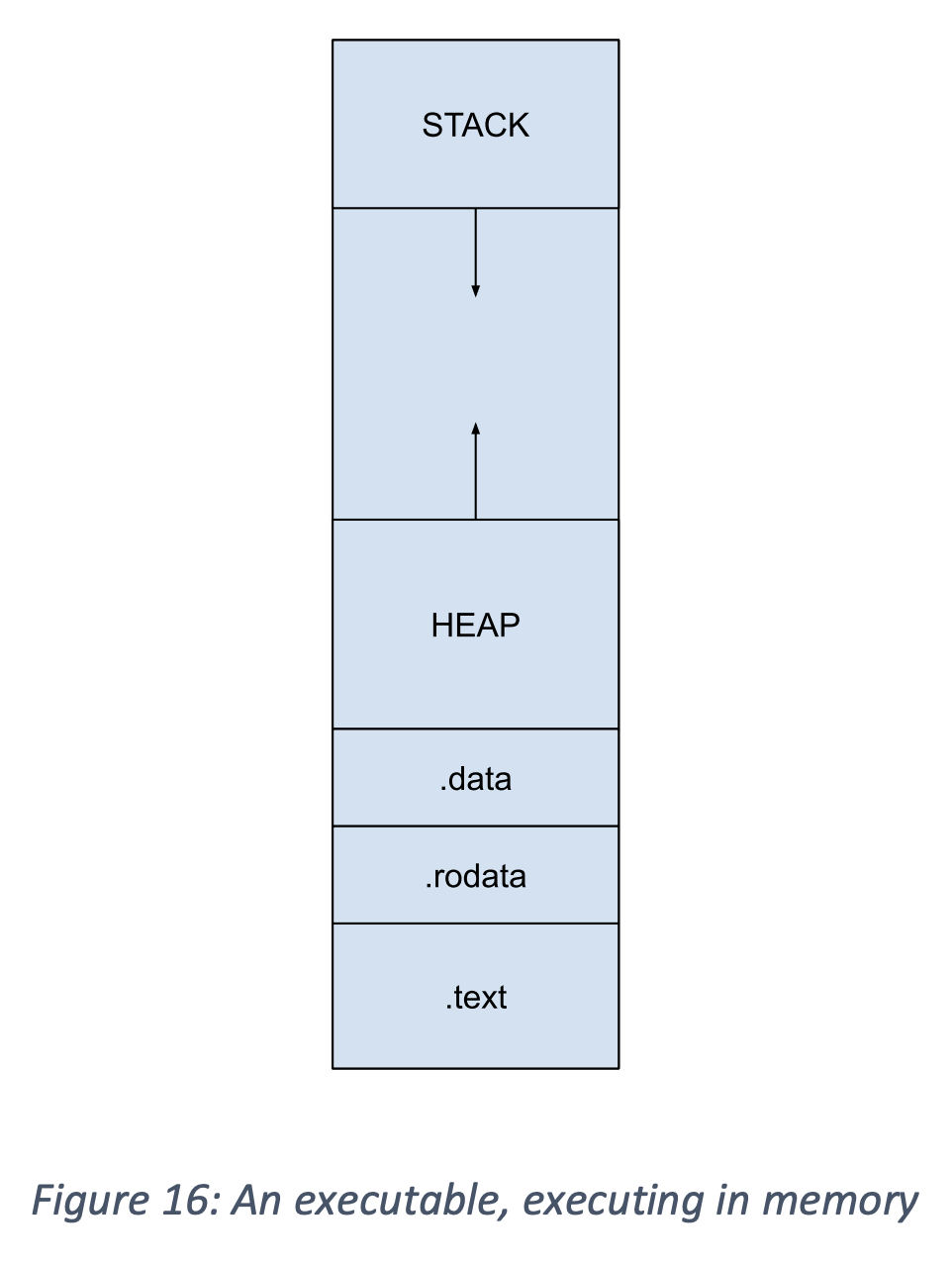
The first thing to notice is the two new areas – the stack and the Heap Memory.
- The stack is used for temporary variables and is typically managed either at compile-time (that is, the compiler encodes the appropriate push/pop operations) or by a very skillful programmer.
- The heap is used for dynamically allocated variables and is always managed by the programmer.
Why does the stack grow down and the heap grows up? This is just a convenient way to ensure that the only way they will ever overlap is when we run out of memory – we place the stack at the top of the memory we are allowed to use and the heap at the very bottom. They then grow towards each other, always into empty space if there is memory available. If we were to place them anywhere else we would have to worry about overlapping them even if there is still memory available to use, which would be a huge amount of overhead to figure out.