Problem 5.1
Show that the logistic sigmoid function becomes as , is when , and becomes when , where
For :
For :
For :
Problem 5.2
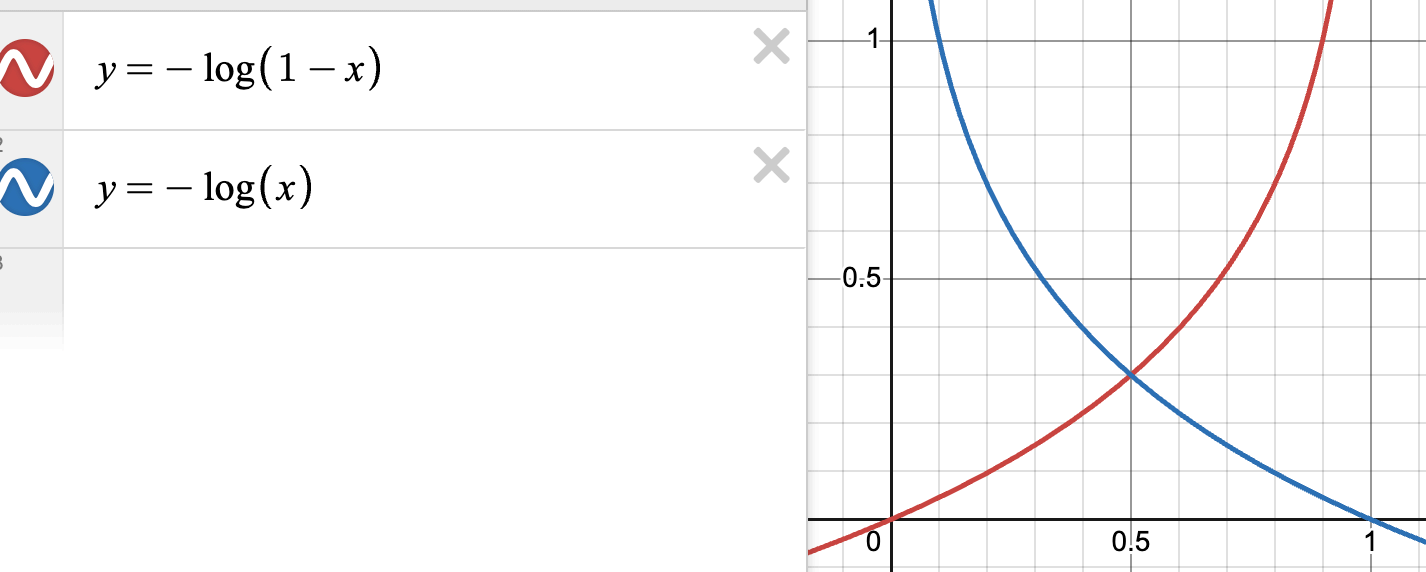
The loss for binary classification for a single training pair is
Plot this loss as a function of the transformed output (i) when the training label and when (ii) when .
When , we just have . With , we just have :
Problem 5.3
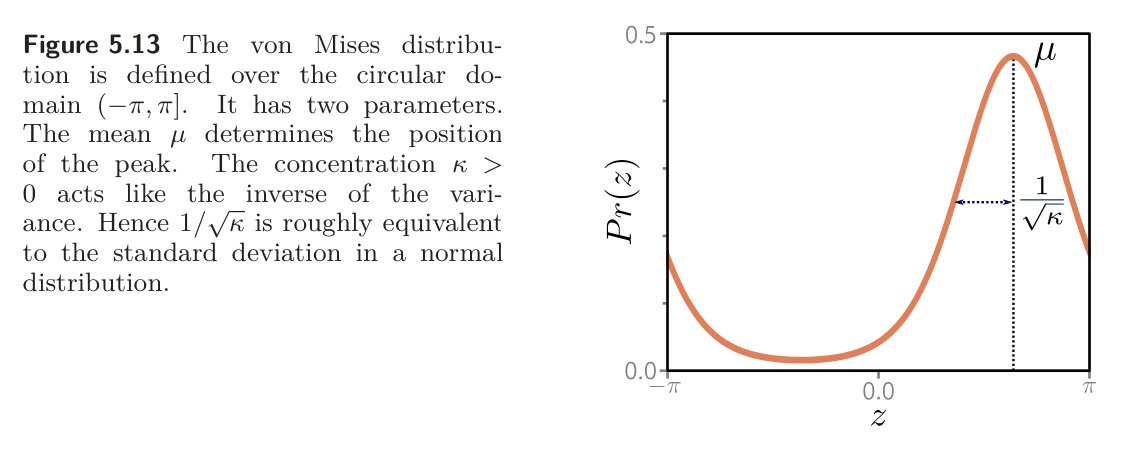
Suppose we want to build a model that predicts the direction in radians of the prevailing wind based on local measurements of barometric pressure . A suitable distribution over circular domains is the von Mises distribution:
is a measure of the mean direction
is a measure of concentration (i.e. inverse of variance)
The term is a modified Bessel function of the first kind of order .
Use the loss function recipe to develop a loss function for learning the parameter of a model to predict the most likely wind direction. Your solution should treat the concentration as a constant. How would you perform inference?
We set , so
Then the negative log-likelihood loss function is
To perform inference we just take the maximum of the distribution (which is just the predicted parameter ). This might be out of the range , in which case we would add/remove multiples of until it is in the right range.
Problem 5.4
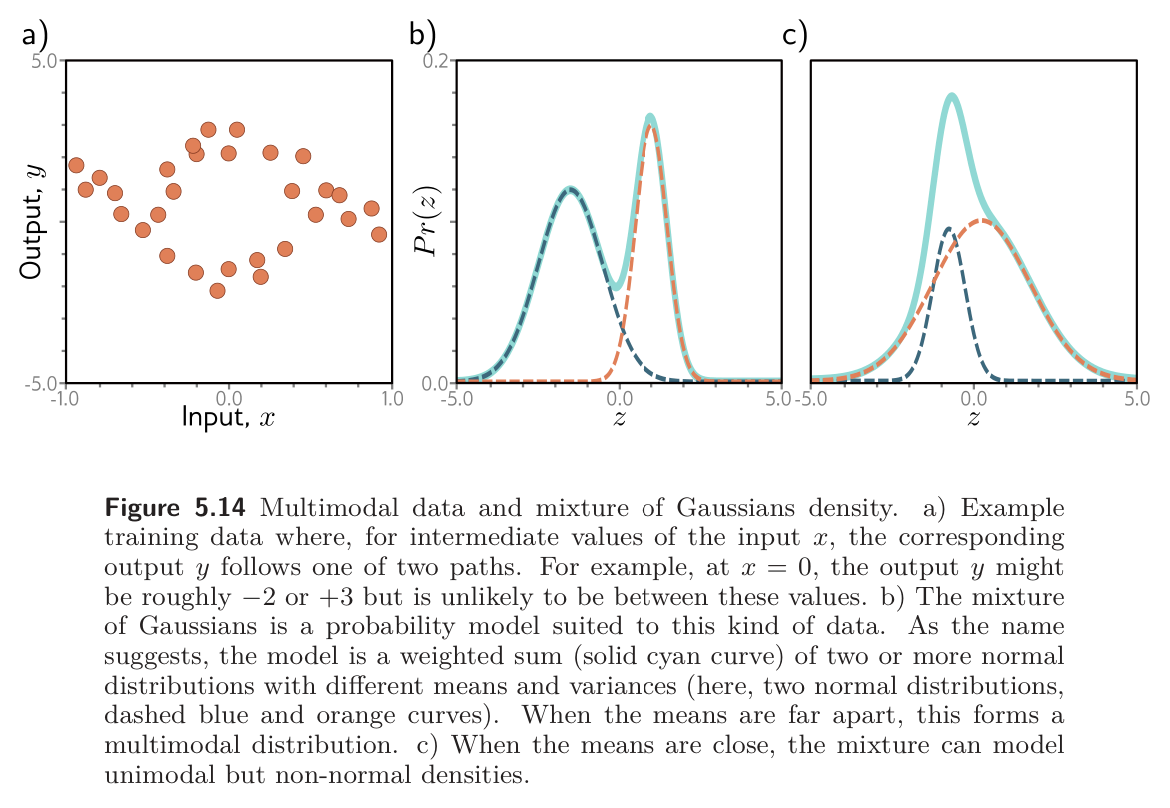
Sometimes, the outputs for input are multimodal; there is more than one valid prediction for a given input. Here, we might use a sum of normal components as the distribution over the output. This is known as a mixture of Gaussians model. For example, a mixture of two Gaussians has parameters :
where controls the relative weight of the two components, which have means and variances , respectively. This model can represent a distribution with two peaks or a distribution with one peak but a more complex shape.
Use the loss function recipe to construct a loss function for training a model that takes input , has parameters , and predicts a mixture of two Gaussians. The loss should be based on training data pairs . What problems do you foresee when performing inference?
Let:
-
- Use sigmoid to enforce .
Then the loss is
Inference is a bit trickier in this case since there is no simple closed form for the mode of this distribution.
Problem 5.5
Consider extending the model from problem 5.3 to predict the wind direction using a mixture of two von Mises distributions. Write an expression for the likelihood for this model. How many outputs will the network produce?
Each von Mises distribution is parametrized by . Thus, for a mixture of two von Mises distributions, the parameters will be
where is the relative weight of the two distributions. The likelihood will then be:
Like the mixture of Gaussians above, we would need five outputs, unless we consider and to be constants, in which case we would need 3.
Problem 5.6
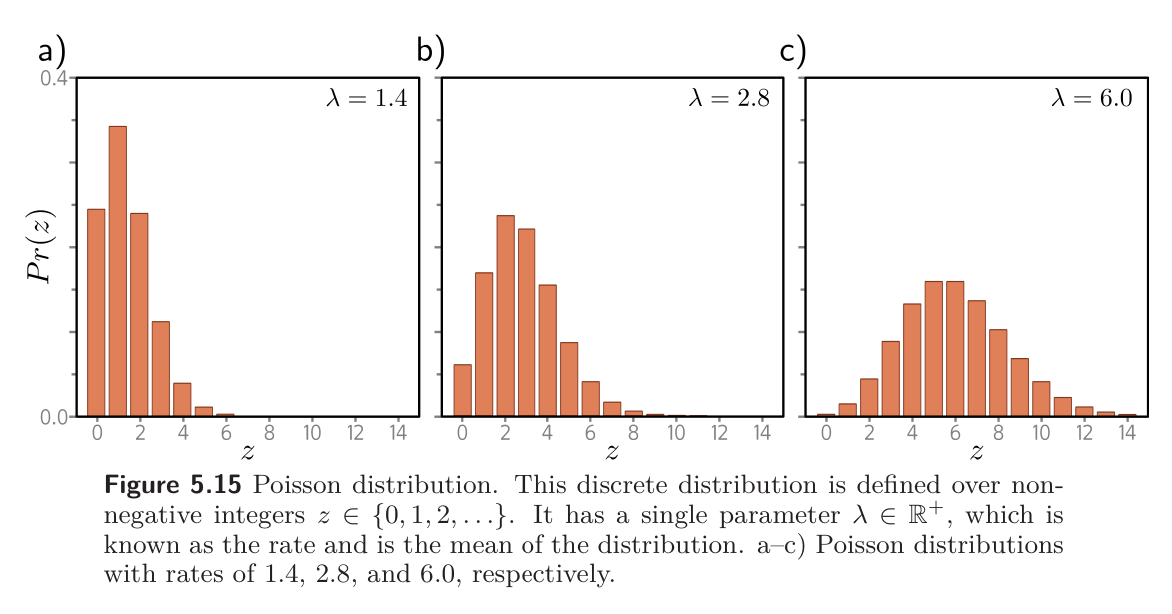
Consider building a model to predict the number of pedestrians that will pass a given point in the city in the next minute, based on data that contains information about the time of the day, the longitude and latitude, and the type of neighborhood. A suitable distribution for modeling counts is the Poisson distribution. This has a single parameter called the rate that represents the mean of the distribution. The distribution has probability distribution function:
Design a loss function for this model assuming we have access to training pairs .
We make the rate the learned parameter such that . Then, we have
The loss function based on negative log-likelihood is then
We can drop the last term above since it doesn’t depend on . Also, we often would want to add a function like or to enforce the condition that , similarly to how we used sigmoid/softmax to enforce before. is likely a better choice because it is differentiable.
Problem 5.7
Consider a multivariate regression problem where we predict ten outputs, so , and model each with an independent normal distribution where the means are predicted by the network, and variances are constant. Write an expression for the likelihood . Show that minimizing the negative log-likelihood of this model is still equivalent to minimizing a sum of square terms if we don’t estimate the variance .
Each probability likelihood is given by
We try to learn parameters to predict each mean, such that .
Then, the overall joint likelihood is given by
Then:
Then, following the derivation we did for least squares, we just have
- The terms with no relation to were discarded since they have no effect on the location of
Problem 5.8
Construct a loss function for making multivariate predictions based on independent normal distributions with different variances for each dimension. Assume a heteroscedastic model so that both the means and the variances vary as a function of the data.
Let:
Then the loss function is:
We can do negative log-likelihood on the inside term too:
Taking the log of the product inside:
Problem 5.9
Consider a multivariate regression problem in which we predict the height of a person in meters and their weight in kilos from data . Here, the units take quite different ranges. What problems do you see this causing? Propose two solutions to these problems.
The values for weight in kilos (50-100 range) are going to be much higher than for height in meters (1-2m) range. Using least squares, the loss will focus much more on weight than height.
Possible solutions:
- Rescale/normalize outputs so they have the same standard deviation, build the model the predict the normalized outputs, and scale them back after inference
- Learn a separate variance for the two dimensions so that the model can automatically take care of this. This can be done in either a homoscedastic or heteroscedastic way.
Problem 5.10
Extend the model from problem 5.3 to predict both the wind direction and the wind speed and define the associated loss function.
Direction uses von Mises distribution in 5.3:
which results in a negative log-likelihood loss function of
For windspeed, we can use a Weibull distribution:
where is a shape parameter and is a scale parameter.
Using negative log likelihood on the Weibull distribution gives us
We can learn both and , or fix and just learn . Let’s say we learn both and have and . Then the complete loss function is: