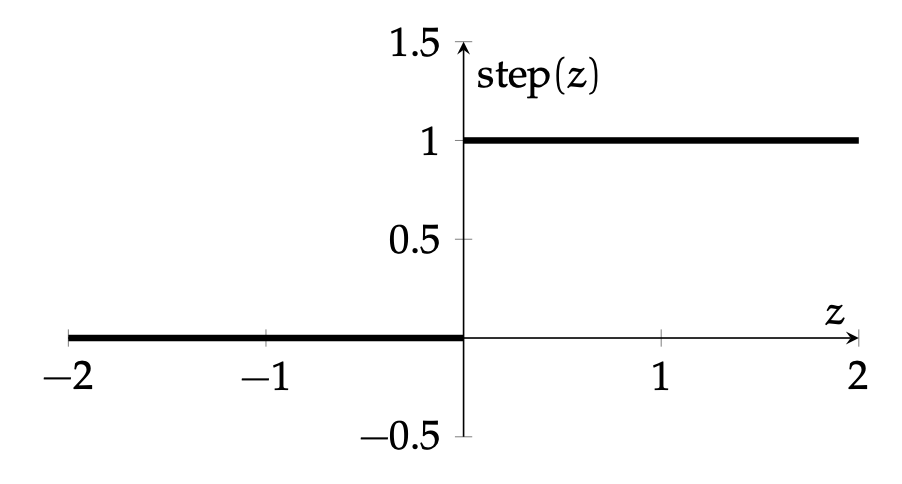
Not very practical as an activation; since the derivative is discontinuous, we won’t be able to use gradient-descent methods to tune the weights in a network.
Not very practical as an activation; since the derivative is discontinuous, we won’t be able to use gradient-descent methods to tune the weights in a network.