Consider fitting a model with parameters using a training set of input/output pairs. We seek the parameters that minimize the loss function :
where the individual terms measure the mismatch between the network predictions and output targets for each training pair. To bias this minimization toward certain solutions:
where:
- is a function that returns a scalar which takes larger values when the parameters are less preferred.
- is a positive scalar that controls the relative contribution of the original loss function and the regularization term.
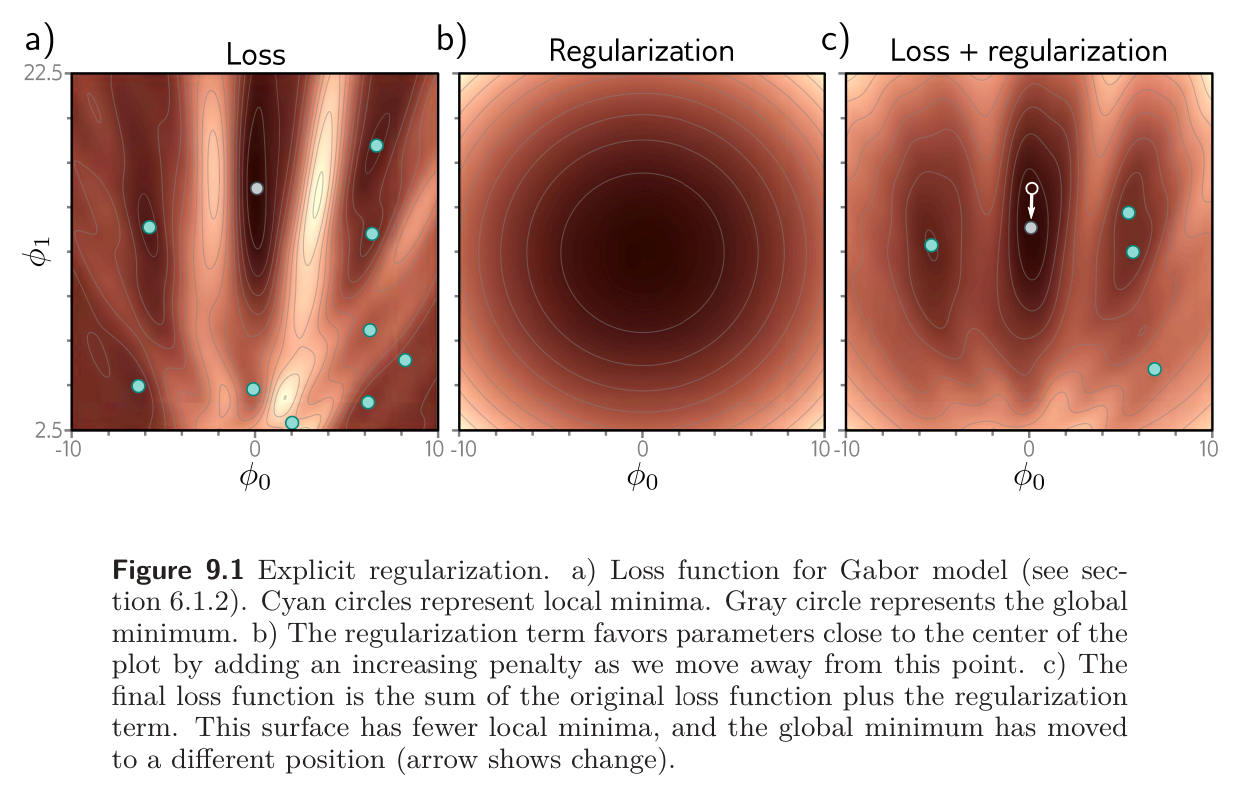
The minima of the regularized loss function usually differ from those in the original, so the procedure converges to different parameter values.
Probabilistic interpretation
Regularization can be viewed from a probabilistic perspective. We’ve seen that loss functions are constructed from the maximum likelihood criterion:
The regularization term can be considered a prior that represents knowledge about the parameters before we observe the data. Now, we have a maximum a posteriori or MAP criterion:
Moving back to the negative log-likelihood loss function (see loss function recipe) by taking the log and multiplying by , we see that