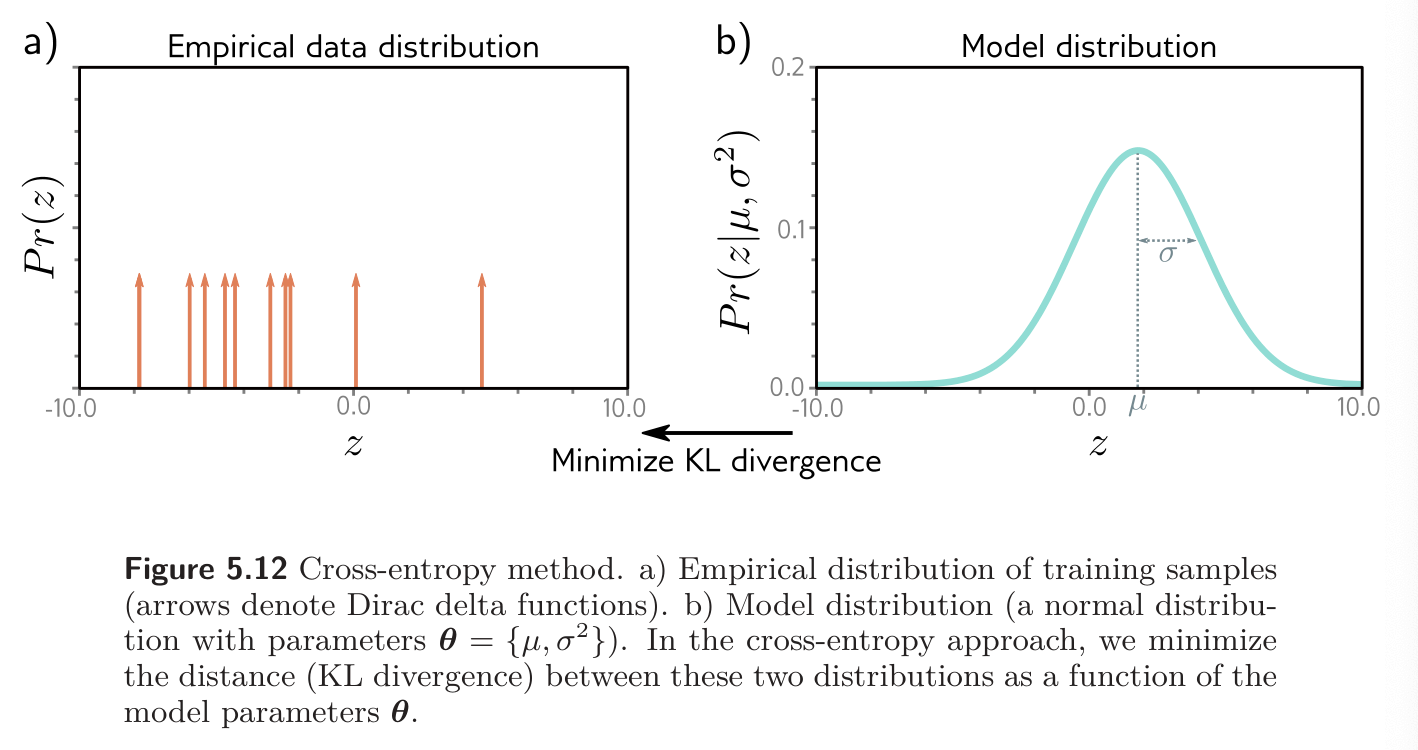
Cross-entropy loss is based on the idea of finding parameters that minimize the distance between the empirical distribution of the observed data and a model distribution .
The distance between two probability distributions and can be evaluated using the Kullback-Leibler Divergence:
Now consider that we observe an empirical distribution at points . We can describe this as a weighted sum of point masses:
where is the Dirac delta function.
We want to minimize the KL divergence between the model distribution and this empirical distribution:
The first term disappears as it has no dependence on . The second term is known as the cross-entropy. It can be interpreted as the amount of uncertainty that remains in one distribution after taking into account what we already know from the other.
Now, we substitute the definition of the empirical distribution :
The product of the two terms in the first line corresponds to pointwise multiplying the point masses (5.12a) with the logarithm of the distribution (5.12b). We are left with a finite set of weighted probability masses centered on the data points. In the last line, we eliminate the constant scaling factor as this doesn’t affect the position of the minimum.
In machine learning, the distribution parameters are computed by the model , so we have
This is exactly equivalent to the negative log-likelihood criterion. Cross-entropy and negative log-likelihood are equivalent!